Computer vision is an essentially practical subject. You are very unlikely to complete your research work without `getting your hands dirty' in the manipulation of image and other data by computer. These practical aspects - instantiating your techniques in software and evaluating them on real (and perhaps simulated) data - are often considered as being fairly trivial. This is most definitely not the case, as most PhD students will probably spend at least 50% of their time on practical work. Hence, it is in your interest to become adept at both using existing software tools and constructing your own. This document aims to help.
In this document, we shall look at software relevant to computer vision. Most of the software considered will be concerned with the image processing aspects of the subject, since that is the base upon which other vision techniques are constructed. Section 2 presents a simple taxonomy of software packages for image processing and computer vision, and several of the most popular are mentioned in Section 3. Some relevant software tools for related operations are also reviewed. There are some efforts to provide standardized versions of common algorithms; the most important of these are discussed in Section 4. You are, of course, going to have to write code of your own at some point, and several aspects of the topic are discussed in Section 5. Section 6 gives a few words of advice, which you are free to ignore - at your peril.
The earliest image processing software package of any significance appears to be VICAR (`Video Image Communication And Retrieval'), developed at the Jet Propulsion Laboratory during the 1960s for processing imagery from the Pioneer probes. VICAR was essentially a set of programs with a batch-only `command language' which simplified the use of the underlying operating system, IBM's OS/360. Since those days, image processing software has developed dramatically, largely inspired by hardware advances. For example, the mini- and micro-computer revolutions of the 1970s produced interactive systems, generally driven from the keyboard, while the 1980s saw the production of packages based around the graphical user interface (GUI) and the 1990s has seen the emergence of vision systems that are able to operate in real-time on fairly conventional hardware. However, throughout all this time, the structure of the underlying algorithms has changed little.
We can identify six basic approaches to the design of software packages for image processing and computer vision. These are presented below in order of increasing complexity.1
To illustrate the above taxonomy, and to give some idea of the functionality of the software packages available, let us consider some of the more popular ones. Most of these are for image processing (i.e., operations involving the manipulation of pixel data) rather than for vision, which may involve the manipulation of higher-level data objects; this is a reflection of the state of the software art.
This is basically a collection of programs that supports inter-conversion between image formats. It does this by providing programs that convert to its own formats and back from them; the formats are PBM (portable bit-map, for bi-level data), PGM (portable grey-map, for grey-scale data), and PPM (portable pix-map, for RGB colour data). The image representations are particularly simple - and come in binary and textual forms - so they have become a de facto standard for making scientific image data available on the net. All the images on PEIPA, for example, are currently stored in PBMPLUS format.
The package also provides some limited processing capabilities (histogramming, convolution, etc.) and there are contributed programs for operations such as Canny edge detection. Most of the programs access the image on a line-by-line basis and hence are suitable for large images and for platforms that lack virtual memory (e.g., DOS). PBMPLUS is freely available; you can get it and a range of add-ons from PEIPA and elsewhere. The latest version of this package was renamed NETPBM and dates from about 1994: it includes some bug-fixes and additional programs.
HIPS [2] is again a collection of cooperating programs for image processing; in fact, it was HIPS that popularized the Unix `filter' philosophy [4] for image processing. It became very popular in the UK in the Alvey-funded projects of the mid-1980s, so there are lots of miscellaneous bits of software floating around that use HIPS-format images. In fact, the image representation was fairly good, supporting byte, integer, and floating-point data, multiple channels (for colour or multi-spectral images, time sequences, or stereo pairs), and an audit trail.2 However, it is fair to say that the original HIPS code was quite poorly written and inefficient, despite being a semi-commercial product. A new version of HIPS has been available for a few years, which is reputed to be better written than the original, and there is a freely-distributable library for reading and writing HIPS-format data.
SEMPER is a complete dinosaur, but should nevertheless serve as an example to us all. It started life in the 1970s in Cambridge, where it was applied principally to electron microscopy [5]. Written in highly-portable Fortran IV on a PDP-8 with 8 kbytes of core memory, SEMPER now runs on machines from the smallest PC to the largest supercomputer. It is written for line-by-line access but, on machines with a decent amount of memory, has a caching mechanism that increases its speed. The data representation of the older versions was complex throughout, since the type of image processing for which it was written employs largely Fourier-based operations; newer versions support other representations too.
C Set up an empty picture.
CREATE 2 SIZE (10); INSERT 0,0
PROJ = 10; T = -PI/2 + 0.1
TEMP = 90; C Temporary picture name.
L: FOURIER PROJ TO TEMP; WEIGHT; IMAGE; C Filter the projection.
SELECT 2; BACKPROJECT TEMP ANGLE T; C Accumulate its back-projection.
PROJ = PROJ+1; T = T + 0.3; UNLESS T > PI/2 JUMP L
set track = "/pix/munev/tmp/track"
@ xsize = 15 # sizes of the template
@ ysize = 15
@ xpos = 170 # position at which the initial template should be extracted
@ ypos = 140
set threshold = "0.6" # threshold on the cross-correlation coefficient
@ spiral = 0 # or 1; whether to use spiral before peak-crawling
# Set up stuff for generating filenames
set basename = "/pix/munev/munev-"
set filetype = ".hips"
@ first_frame = 11
@ last_frame = 421
@ frame_inc = 10
set template = "TMP-template"
set track_out_base = "TMP-track-output-"
# Loop over the frames, running the tracking and extraction programs
# each time round
@ frame = $first_frame
while( $frame <= $last_frame )
# make `num' hold the right-aligned frame number
set num = $frame
if( $frame < 100 ) set num = "0$frame"
if( $frame < 10 ) set num = "00$frame"
set filename = "${basename}${num}${filetype}"
echo Looking at file $filename
# generate temporary files for the current frame
set track_out = "${track_out_base}${num}"
# on the first frame, get an initial template; on other frames,
# we have to run the tracking program, too
if( $frame == $first_frame ) then
extract $ysize $xsize $ypos $xpos <$filename >! $template
else
echo " extracting at ($xpos,$ypos)"
$track $template $xpos $ypos $threshold $spiral <$filename >! $track_out
source $track_out
echo " position: ($xpos,$ypos)"
echo " displacement: ($xdisp,$ydisp)"
extract $ysize $xsize $ypos $xpos <$filename >! $template
delete ${track_out} # delete the unwanted temporary files
endif
@ frame = $frame + $frame_inc # increment the frame counter
end
delete $template # remove the template file
More impressive though, SEMPER provides a baroque but powerful command language (Figure 1); toolkits such as HIPS rely on the facilities of the Unix shells for building higher-level programs, which is less efficient (for both man and machine) and inherently non-portable. To illustrate this, a Unix C-shell script driving a HIPS-like tracking program is presented in Figure 2: the script uses only two programs, extract and track, so the overhead of the C-shell language is obviously significant. Now commercially available (and apparently converted to C), there are GUIs that convert menu selections to SEMPER commands and execute them. SEMPER is a single program that is small and beautifully formed; I admire it very much.
I have deliberately considered Khoros [6] after SEMPER to emphasize the contrast between the two: a full SEMPER installation comes on a couple of floppies and occupies a few megabytes - but Khoros occupies about 100 Mbytes! It is an incredibly bloated collection of programs, some written in C and some in Fortran. Its data format (VIFF) is actually a set of different formats, supporting single-band, multi-band, and volumetric data, so it is often necessary to insert data-format conversion filters in the processing pipeline (a criticism also true of HIPS and other packages of the same ilk, incidentally). Having said that, Khoros processing programs all have consistent command-line interfaces (required for Cantata, discussed below) and the range of pixel-level functionality is probably the greatest of any of the packages considered here. With the release of Khoros 2.0 and latterly Khoros 2000, the general quality of the code and of the user interface has improved, though it has concentrated more on visualization than on processing.
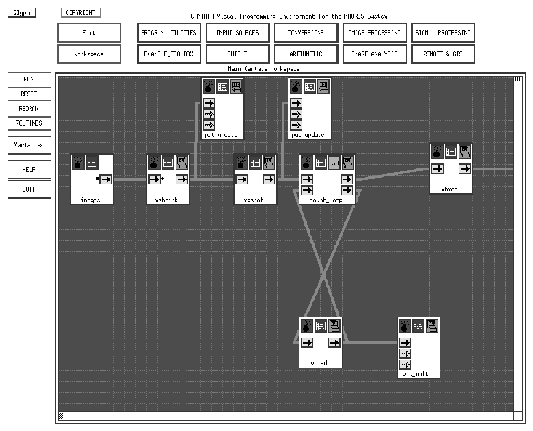
The most lauded part of Khoros is Cantata (see Figure 3), its `visual programming' tool. The Cantata user essentially draws a flow-chart of the sequence of operations, which may be executed automatically by Cantata, or step by step under the user's control. As far as the author can tell, this approach originated with ConMan [7], which was used for constructing and visualizing the stages of a 3-D rendering pipeline. The author must admit to being a little suspicious of the visual programming approach: the graphical presentation is undoubtedly good for giving demonstrations and is an excellent way for non-computer-literate users to get going quickly. For scientists and engineers who are already familiar with computers, however, it seems to be an inefficient and limited mode of interaction and encourages a `black box' mentality.
xv is not really an image processing package, it is an image display program with a few simple display-related options built in. It is sufficiently well-written as to be in common use in most image processing laboratories and elsewhere. xv is shareware but there is a CHEST agreement that makes it available to the UK academic community free of charge. Do try it.
A commercial product, KBVision is one of the few packages intended to be used for problems in image understanding. KBVision has a visual programming tool somewhat like Cantata, data visualization tools, a `task library' (which seems to be a set of co-operating programs), and libraries of routines for accessing files, interfacing to graphics functions, and so on. However, KBVision also supports `intermediate symbolic representations' (lines, regions, polygons, etc.) and allows the user to manipulate them in much the same way as images. In fact, the low-level software is written in C and the higher-level software for performing reasoning about image content is Lisp-based. Hence, KBVision provides somewhat more facilities for vision than do most other packages.
Matlab is a commercial product that is pretty widely-used in the signal processing community. It also has an adequate image processing `toolbox,' and toolboxes for things like Kalman filters, neural networks, genetic algorithms, and so on. It runs on most Unices, including Linux, and on Windows 95/NT. Its programming language is compact - much more compact than C, for example - and it has excellent visualization facilities. If your research requires you to use these types of operations rather than research into them and Matlab is available, you would be well-advised to use it. For people who are researching into vision algorithms, the lack of source code is a killer.
There are a couple of freely-available approximations to Matlab: SciLab from INRIA in France and Octave from the USA; but neither of these seems to have anything like the functionality of the commericial product.
The above discussion concentrates on the processing of pixel data since that is the most common requirement in the vision field. However, it is becoming more and more common for vision applications to combine this type of processing with higher-level reasoning. With one or two exceptions, you currently have to devise your own higher-level software from scratch - though there are moves afoot (see Section 4.2) in this area too. Even now though, there are some bits of software that you might be able to make use of.
Neural networks are almost ubiquitous - though it is fair to say that, for many vision tasks, they are a solution in search of a problem. There are a few decent neural network packages on the net (and lots of awful ones). Two with which the author has some experience are BPS and SNNS, the Stuttgart Neural Network Simulator. BPS handles only multi-layer perceptrons, but has the advantage that networks can be trained on fast Unix machines and then used on DOS-based ones - valuable if you have to work in the field. SNNS seems to be particularly useful for people who wish to use neural networks rather than research them: it provides multi-layer perceptron, radial basis function, and Kohonen networks (and others) and supports a range of learning paradigms. It can also be used in batch mode, where it checkpoints automatically (invaluable when networks take a long time to train, as do some of the author's), and can be used on some parallel architectures.
However, the neural approach is not the only one. Equally good in many situations is the genetic algorithm (which, it seems to me, is a better analogue of biological processes than is a neural network). One of the most popular packages on the net is probably John J. Grefenstette's GENESIS:3 with it, as with most genetic algorithm packages, you must supply an evaluation function, written in C, which is minimized (or maximized). You can consider this as explicitly building knowledge of the problem into the algorithm; with neural networks, it is only there implicitly via the training set. GENESIS does have some restrictions: it requires a binary representation for its `genes' (though it does support Gray codes) and expects its input and output files to have particular names - so I normally use it within a Perl [8] `wrapper.'
For the numerical techniques that underlie many vision processes, there are quite a few sources of information - though, incredibly, the author is not aware of a freely-distributable package that implements cluster or statistical analysis techniques. In terms of the Internet, good starting places are netlib and statlib, both of which are mirrored in the UK. However, having the software is only half of the story, since you should be at least familiar with the underlying algorithms. The most popular book on the topic is undoubtedly [9], and rightly so since it explains the algorithms in a clear and informative way. However, do not treat it as the gospel truth: there are definitely some inaccuracies in the discussion of fast Fourier transforms, for example.
You should also be a little cautious when using software from books verbatim. For one thing, there are restrictions on its use. The C code in [9] in particular (being partially machine-translated from Fortran) has some quirks: array subscripts starting from 1 instead of 0 by use of pointer calisthenics, for example. More importantly however, you should be aware that the implementations are not necessarily the best available: the author has used eigen decomposition routines from [9] and from the NAg library in the implementation of a principal component analysis routine and found the latter to produce significantly better eigenvectors. (Accuracy is easily checked by calculating the inner product of eigenvectors: the eigenvectors should be orthogonal, so the inner product should evaluate to the identity matrix.)
For the really fundamental numerical algorithms such as random number generators, the author has yet to find a better source of information than [10]. Although the style of presentation may not be to everyone's taste, it gives a well-informed and accurate discussion of the techniques available.
One area of computer vision that is finally starting to receive serious attention is that of testing and benchmarking. This is not simply verifying that software works as expected (discussed in a later section) but the use of objective, usually statistical, measures for comparing the performance of vision algorithms. Currently, most papers describe a novel algorithm and illustrate its effectiveness on a few images, sometimes carefully chosen; they rarely make any attempt to compare the new algorithm's effectiveness with those of existing alorithms. This is bad science. To be able to achieve the aims of computer vision more rapidly, we need to be able to build on other researchers' work efficiently - and to do that, we need to be able to use their software and know how well it works.
One of the problems with statistically-based testing is that it generally involves applying an algorithm to many images. Since this is an incredibly tedious and error-prone process when done manually, there are a number of tools that can do it for you. One that was designed with the needs of vision in mind is HATE, currently available from
http://vase.essex.ac.uk/projects/hate/HATE is written entirely in Tcl [11]. To use it, you write a short procedure to interface your software to HATE, define the series of tests to be carried out as another procedure, and then let HATE perform the tests and calculate things like false-alarm rates.
Some of the software considered above is sold commercially, so you have to buy the right to use it. Most of the rest is freely available (generally from PEIPA) so you can obtain and use it without worrying about how you are going to pay for the privilege. Such software is not generally public domain, since the authors retain copyright; restrictions are typically placed on their use - for example, research use only, or may not be incorporated in commercial applications. You should check the restrictions on anything you use. You should not hassle the authors of free software for fixes to any bugs you might find! They will probably be pleased to learn of a problem but, unless the fix is trivial, they are under no obligation to fix it.
Some other software is shareware. If, after trying the software for a while, you find it useful, you are obliged (at least morally) to pay the requested fee. The fee is normally not high; and paying it encourages the author to maintain and develop the code.
One caveat: the quality of freely-distributable software is highly variable. When you import such software, test it carefully to ensure that it does what it purports to do and that it does it correctly. Only then trust the results.
What of the other side of the coin, when you develop a piece of software that you believe will be of more general interest? Surprisingly, very few UK-based researchers or research groups make their software available: PEIPA is full of software from the USA, from Germany, Switzerland, and from Scandanavian countries, but there is little from the UK. My suspicion is that the principal reason is that people are embarrased about the quality of their code (often with justification). I strongly believe that this must change. So I would like to exhort you, the up-and-coming generation of UK researchers, to submit your own code to PEIPA, where it can be made available to the world at large.4 Everyone benefits from this: you have your software tested by other people, possibly finding bugs that might bite you later; they may suggest improvements and enhancements; and the documentation that you write can eventually find its way into your thesis.
There have been a few calls for the development of standards in the image processing and computer vision areas, and one or two groups have even gone to some effort in producing portable code and attempting to popularize it. However, it is only recently that serious efforts have been made to produce standards of widespread applicability. The two most important of these are discussed below.
Image Processing and Interchange (IPI) was published as an international standard in 1995. It provides a programming interface and an image transfer specification that may be used for a variety of image processing applications; it is not intended specifically for vision applications. Work on IPI started in 1991, so the entire project was completed in under four years, something of a record for a standard of its size!
IPI comprises three parts. The first part defines IPI's main architectural features. The second part is concerned with processing images; and the third part considers image interchange. The standard defines a `functional specification,' a detailed description of the image processing functions that must be provided without reference to any programming language; a separate standard describes how the functional specification is mapped onto a specific programming language. (Such a mapping only exists for C at the moment, though a C++ one is on the cards.)
Images that may be processed by PIKS, the image processing part of IPI, may be thought of as comprising five dimensions: the usual two spatial dimensions; depth (for representing voxel data); time (for moving imagery); and band (for colour or multispectral data). Multi-sensor data can also be represented by means of the band dimension. Several pixel representations are supported, including unsigned byte, integer, floating-point, and complex. The range of image processing functions is roughly equivalent to that of Khoros. The definitions are such that hardware can be built to implement many of the operations.
While IPI is an official international standard intended for general image processing applications, the Image Understanding Environment (IUE) is being defined and developed by a group of academic and other institutions specifically for vision-like applications. IUE was conceived in the USA but work is being directed towards it in other countries, particularly the UK, where the second phase of the Integrated Machine Vision programme concentrated on making extant research code fit in with the IUE core.
In fact, the IUE was initialy imposed upon the US institutions by DARPA, their funding agency - though the participants have subsequently realized the advantages of working towards a common environment and have become more enthusiastic about it. After producing something to form the basis of discussions, the IUE group approached European and Japanese groups for comments and contributions, the aim being that it could form the basis of an internationally-accepted vision environment.
The IUE was originally conceived as a C++ class library interfaced to a common Lisp interpreter, with the C++ classes being identical to classes within CLOS, the common Lisp object system. However, no Lisp system existed to support such a concept, and the company that received funding to develop a suitable system ceased trading before reaching a product. Hence, the IUE is currently being developed principally as a set of cooperating C++ classes. The existing classes fall into four main areas: sensors; data representation (images, lines, etc.); geometry; and coordinate transformations. The IUE code is being written by Amerinex AAI, the company that currently sells KBVision; although it will eventually be sold, it is intended that the cost will be low enough for academic groups to afford it - and the revenue will be used for support and further development. You can find out more about the IUE by looking at Amerinex's world-wide web pages:
http://www.aai.com/The code and documentation distributions are mirrored twice-weekly on PEIPA. If you want to explore it, this is the best place to look.
Although the author has not yet used the IUE himself, he is aware that reaction to it is mixed: the classes appear to be surprisingly specific to a particular version of g++ and compilation is supposedly very slow. Run-time performance is apparently not too sparkling either (though that was not the intention). My personal opinion has swung against the IUE in the couple of years: I was initially very supportive because I believe that a common framework would benefit the entire community; but it seems to be suffering from a serious case of the ``second-system effect''5 which means its development is slow, ponderous, and probably not relevant to the community at large. Indeed, I am so disenfranchized that my students and I have been working for the last few months on Jive, a package that aims to small (like SEMPER rather than Khoros), flexible (with a scripting language for extensions and GUI construction), but yet fast enough for real-time processing. However in trying to give you a balanced judgement of the IUE, perhaps I should say that the jury is still out: it offers much promise but it is not yet mature enough to be used outside the major research groups with confidence.
Before passing on, Target Jr deserves a mention. It was initially devised as a prototype for the full IUE but seems to have taken a life of its own. To find out more, look at
http://www.targetjr.org/
We now turn our attention to the practical aspects of image processing and vision software - in other words, things to bear in mind when producing software of your own. Many people consider the programming stage a necessary evil, something that can be rushed off quickly because it simply instantiates the underlying mathematics. This attitude is totally naïve, for mathematically tractable solutions do not guarantee viable computational algorithms. Indeed, the author prefers to consider a programming language as a formal notation for expressing algorithms, one that can be checked by machine, and a program a formal description of an algorithm, incorporating both mathematical and procedural aspects.
The fast Fourier transform (FFT) is a classic example of the distinction between mathematics and algorithmics. The underlying discrete Fourier transform is normally represented as a matrix multiplication; hence, for N data points, O(N2) complex multiplications are required to evaluate it. The (radix-2) FFT algorithm takes the matrix multiplication and, by exploiting symmetry properties of the transform kernel, reduces the number of multiplications required to O(Nlog2N); for a 256 ×256 pixel image, is a saving of roughly
|
On the other hand, one must not use cute algorithms blindly. When median filtering, for example, one obviously needs to determine the median of a set of numbers, and the obvious way to do that is to sort the numbers into order and choose the middle value. Reaching for our textbook, we find that the `quicksort' algorithm (see, for example, [12]) has the best performance for random data, again with computation increasing as O(Nlog2N), so we choose that. But that is its best-case performance; its worst-case performance is O(N2)! A better compromise is probably the shell sort: its best-case performance isn't as good as that of the quicksort but its worst-case performance is nowhere near as bad - and the algorithm is simpler to debug.
Even selecting the `best' algorithm is not the whole story. Median filtering involves working on many small sets of numbers rather than one large set, so the way in which the sort algorithm's performance scales is not the overriding factor. Quicksort is most easily implemented recursively, and the time taken to save registers and generate a new call frame will probably swamp the computation, even on a RISC processor; so we are pushed towards something that can be implemented iteratively with minimal overhead - which might even mean a bubble sort! But wait: why bother sorting at all? There are median-finding algorithms that do not involve re-arranging data, either by using multiple passes over the data or by histogramming. One of these is almost certainly faster.
Considerations such as these are important if you need to obtain accurate answers or if your code forms part of an active vision system.
The first question obviously concerns what programming language to use. These days, there are only two popular choices in the image processing and vision areas, C and C++. The choice between these two is not as clear-cut as you might expect as both have their advantages and disadvantages:
Sun's Java language, which has received incredible amounts of hype with regard to Web content programming, actually promises much for vision programming in the future. It is well-thought-out in as much as it dispenses with explicit pointers (always the most error-prone part of C and C++), avoids the run-time penalty of multiple inheritance by prohibiting it, and makes a better job of enforcing the object-oriented approach. It is also highly portable, which the author considers to be the holy grail of any programming task, and builds in important practical features such as multi-threading. On the down side, the byte-interpreted nature of most implementations makes Java too slow for serious vision work at the moment, though the advent of``just-in-time'' interpreters has ameliorated that. Worse, images have a poor internal representation, at least within Sun's JDK; and there are methods for reading GIF and JPEG images but not for writing them!
It is only common sense to use make (e.g., [15]) for compiling programs. However, there are other support tools that can make your life easier. The most important of these is the `Revision Control System,' RCS [16]7 [17] or its sibling, the Concurrent Version System (CVS); my preference is for the latter. As well as giving each generation of your programs a version number, RCS and CVS allow you to back-track to earlier versions of the source code if you find you have introduced a bug at some point. CVS also supports team-based concurrent development. Since RCS and CVS are freely available (from GNU archives) and run on Unix and Windows, there is no good excuse for not using it. There's even a GUI for CVS.
Time spent gaining a basic proficiency in one of the popular scripting languages is well spent. There are many such languages to choose from: Perl, Tcl/Tk, Python, and so on. There are freely-available interpreters for all the languages mentioned and good books to help you learn them. (The author uses principally the first two, but you can undoubtedly get by with any one of them.)
You also need a good symbolic debugger, such as dbx on BSD-derived systems. The author favours gdb, the GNU debugger, since it interfaces well to Emacs and is available on all the platforms he uses. Many of the Windows-based compilers come with fairly useful debuggers too, as does the JDK and integrated development environments such as Symantec's Cafe.
A useful rule of thumb is that for every image processing package there is an associated file format! For most people, the image file format they use will be mandated by that used by existing software; however, you will still probably have to import or export imagery at some point, so there is no escaping the problem. Here are a few guidelines:
In the author's opinion, there is still no image file format that is sufficiently flexible for all application areas of computer vision.
Perhaps the best way to illustrate this is by means of an example. The following C code performs image differencing, a simple technique for isolating moving areas in image sequences.
typedef unsigned char byte;
void sub_ims (byte **i1, byte **i2, int nl, int np)
{
int l, p;
for (l = 0; l < nl; l++)
for (p = 0; p < np; p++)
i1[l][p] = i1[l][p] - i2[l][p];
}
The procedure consists of two nested loops, the outer one scanning
down the lines of the image and the inner one accessing each pixel of
the line; it was written with exposition in mind, not speed. Let us
consider what is good and bad about the code.
Firstly, the code accesses the pixels in the correct order. Two-dimensional arrays in C are represented as `arrays of arrays,' which means that the last subscript should cycle fastest to access adjacent memory locations. On workstation-class machines, all of which have virtual memory subsystems, failure to do this could lead to large numbers of page faults, substantially slowing down the code. Incidentally, it is commonly reported that this double-subscript approach is dreadfully inefficient as it involves multiplications to subscript into the array - but that is complete bunkum!
There are several bad aspects to the code. Arrays i1 and i2 are declared as being of type unsigned char, which means that pixel values must lie in the range 0-255; so the code is constrained to work with 8-bit imagery. This is a reasonable assumption for the current generation of video digitizers, but the software cannot be used on data recorded from a 10-bit flat-bed scanner, or from a 14-bit remote sensing satellite, without throwing some potentially important resolution away.
What happens if, for some particular values of the indices l and p, the value in i2 is greater than that in i1? The subtraction will yield a negative value, one that cannot be written back into i1. Some compilers may generate an exception; others will silently reduce the result modulo 255 and continue, so that the user erroneously believes that the operation succeeded. In any case, one will not get what one expected. The simplest way around both this and the previous problem is to represent each pixel as a 32-bit signed integer rather than as an unsigned byte. Although images will then occupy four times as much memory (and require about four times as long to read from disk, etc.), it is generally better to get the right answer slowly than an incorrect one quickly. In any case, on modern processors, there penalty in computation speed is negligible.
The code also has serious assumptions implicitly built in. It assumes that images comprise only one channel of information, so that colour or multi-spectral data require multiple invocations. More seriously, it assumes that an image can be held entirely in computer memory. Again, this is reasonable for imagery grabbed from a video camera but totally unreasonable for the author's 6000 ×6000 satellite data!
There are ways of avoiding these types of assumptions. Although it is not really appropriate to go into these in detail in this document, an indication of the general approaches is probably of interest.8 Firstly, by making a structured data type (or, in C++, a class) called `image', one can arrange to record the data type of the pixels in each image; a minimal approach is:
struct {
int type;
void *data;
} image;
...
image *i1, *i2;
Inside the processing routine, one can then select separate loops
based on the value of i1->type.
The traditional way of avoiding having to store the entire image in memory is to employ line-by-line access:
for (l = 0; l < nl; l++) {
buf = getline (l);
for (p = 0; p < np; p++)
...operate on buf[p]...
putline (l, buf);
}
However, an alternative approach, pioneered in
[18], also avoids building knowledge of the
array sizes into the code:
while (buf=getline (buf, &np)) {
for (p = 0; p < np; p++)
...operate on buf[p]...
putline (buf, np);
}
Originally written for accommodating an `interval' representation for
image data, this approach was used by the author and colleagues to
produce code that was capable of being used unchanged on both
serial and parallel hardware.
The following paragraphs give some advice that you might wish to bear in mind when developing software of your own. They are probably strongly influenced by the author's prejudices, but also drawn from nearly two decades' experience of processing image data.
There is a great temptation to fit a GUI to image processing and
vision software, the intention being to simplify its user interface
and to improve interaction. Resist it! The time taken to write a
half-decent GUI in C for X or Motif is at least as long as
the time it takes to construct the rest of the program - and a poor
GUI is actually counter-productive. After all, you are researching
into vision, not into GUI construction! Furthermore, if you are
writing a component of an overall system, which is often the case, a
GUI will definitely get in the way when you come to the integration
stage.
A much better solution, at least in the author's opinion, is to produce a good command-line interface. There are free routines around, such as parseargs9 that do the hard work: you simply provide a table that indicates the argument name, type, etc.. Having written several programs that have consistent command-line interfaces and utilize a common data format, it is quite simple to write a GUI ``wrapper'' in a suitable language. Popular choices are Tcl/Tk [11] and an equivalent package for version 5 of Perl [8].
In fact, one can go even further: the author has in the past integrated image processing functionality into the Tcl language, so that the image processing `commands' appear as new verbs (keywords). One of the former attendees at this summer school has built a complete vision system, TABS, based on this approach, and it is freely available from
http://vasawww.essex.ac.uk/~craccb/tabs.html
Whatever language you choose for writing your software, get a copy of the language definition, read it (no matter how boring), and write programs strictly in accordance with the standard. You will hate it at first - but you will be thankful later. People who do not write to a language standard often claim that portable code is necessarily slow; this is not the case. However, if your code does turn out to be slow, there are several common-sense approaches to speeding it up without compromising portability. The first thing to do is to turn on the optimizer on your compiler! If that doesn't help, the next step is to profile your code (there are tools that will do this for you, such as the GNU profiler) to find out where your effort should be directed. Choosing a better algorithm for critical sections of code, if one is available, will pay the greatest dividends. There are other optimizations you can do too, such as removing repetitive calculations from loops; some compilers will do this for you but many will not.
There are also some programming tricks you can use to improve performance. For example, if your code carries out a significant number of operations on small regions (e.g., 3×3 or 5×5) of an image, modify your code to copy the values from the image into temporary variables, process the temporary variables, and then write the result back into the image. Although this increases the total amount of code, it allows the compiler to generate code that operates on the temporary variables by holding them in registers; operations on register variables are typically faster than operations on variables in memory by a factor of three or more, especially on RISC processors. Optimizations of this type were applied to UC Berkeley's software MPEG player and gave about a 15% performance boost.
However, do not put much effort into speeding up your code unless real-time performance is required: a day's effort in speeding up a program that is used for a couple of minutes per day is not efficient use of your time.
Comment your programs thoroughly, and ensure that the comments explain the algorithm accurately. When you have to modify the program after 18 months, good comments can save days of debugging. It is also worth writing brief documentation on all non-trivial programs and routines, even if only in the form of abominable Unix manual pages, for the same reason.
Develop a programming style, including consistent structure, layout and commenting practice, and stick to it. There are a few style guides in books and on the net; you could do worse than [19] as a starting point,10 which defines the easy-to-read style used in Tcl/Tk.
Even if you do none of the above, do test your code meticulously. For each program or routine, write a short script that applies it to a series of datasets and verifies that it yields the expected result. (This is another good reason for having a command-line interface.) Keep the script. When a bug eventually comes to light, add a test to the script that exercises the bug. Then fix the bug. Then run the script again to ensure that all the tests succeed: fixing one problem can easily introduce another. (This approach is sometimes termed `regression testing' and is often used for testing compilers.) The datasets you choose should ideally exercise every line of code; and they should test boundary cases, such as an image size 0×0, 1×n, n ×1, images with all pixels set to zero, and so on. There are tools that will help run regression tests for you; the best-known of these is probably Déjà Gnu, though the author's abovementioned HATE system is arguably more appropriate in the vision context.
You will almost have certainly have to use computers in your research projects, both running other people's software and developing your own. This document should have given you some idea of what other people have written and made available; you will generally find it faster to use existing code than writing your own. But test other people's code carefully, at least as carefully as you test your own, before trusting it. And when you do write your own software, remember that correctness is the most important virtue; be prepared to put some effort into ensuring it. All other considerations are secondary.
Even when you have rigourously tested your software, treat any results that emerge from a computer with suspicion. Are the numbers the right order of magnitude? Are they consistent with what you expect? If not, why not? Developing a feel for the subject is the best way to catch bugs - and the best way to come up with new ideas and approaches.
Now, go forth and write beautiful programs.
1 Some might say in order of increasing sophistication.
2 An audit trail is a history of all the operations that have been applied to an image.
3 Beware: there are other genetic algorithm packages with very similar names.
4 Before doing so, however, it is polite to obtain your supervisor's agreement. In my experience, this is normally forthcoming.
5 The first versions of most systems are usually small and elegant. In all too many cases, the second version becomes laden with features that are irrelevant, hard to use, and full of bugs and inconsistancies. Users of Microsoft Word will know what I mean.
6 Languages such as Eiffel are much better in this respect.
7 The RCS distribution contains an expanded version of this paper with fairly good instructions for its use.
8 The author is happy to ramble on ad nauseam about this in the bar.
9 This appears to originate from Eric P. Allman's `C Advisor' column in Unix Review 7(11). An extended version of his original routine was subsequently distributed to the comp.sources.misc newsgroup by Brad Appleton. The version I use is adapted from the routine Tk_ParseArgv from John Ousterhout's Tk package [11], which also seems to be derived from Allman's code; you're welcome to have a copy.
10 I can let you have the LATEX source of this upon request.