A Brief Overview of Gesture Recognition
A primary goal of gesture recognition research is to create a system which can identify specific human gestures and use them to convey information or for device control. To help understand what gestures are, an examination of how other researchers view gestures is useful. How do biologists and sociologists define "gesture"? How is information encoded in gestures? We also explore how humans use gestures to communicate with and command other people. Furthermore, engineering researchers have designed a variety of "gesture" recognition systems - how do they define and use gestures?
Biological and Sociological Definition and Classification of Gestures
From a biological and sociological perspective, gestures are loosely defined, thus, researchers are free to visualize and classify gestures as they see fit. Speech and handwriting recognition research provide methods for designing recognition systems and useful measures for classifying such systems. Gesture recognition systems which are used to control memory and display, devices in a local environment, and devices in a remote environment are examined for the same reason.
People frequently use gestures to communicate. Gestures are used for everything from pointing at a person to get their attention to conveying information about space and temporal characteristics [Kendon 90]. Evidence indicates that gesturing does not simply embellish spoken language, but is part of the language generation process [McNeill 82].
Biologists define "gesture" broadly, stating, "the notion of gesture is to embrace all kinds of instances where an individual engages in movements whose communicative intent is paramount, manifest, and openly acknowledged" [Nespoulous 86]. Gestures associated with speech are referred to as gesticulation. Gestures which function independently of speech are referred to as autonomous. Autonomous gestures can be organized into their own communicative language, such as American Sign Language (ASL). Autonomous gestures can also represent motion commands. In the following subsections, some various ways in which biologists and sociologists define gestures are examined to discover if there are gestures ideal for use in communication and device control.
Gesture Dichotomies
One classification method categorizes gestures using four dichotomies: act-symbol, opacity-transparency, autonomous semiotic (semiotic refers to a general philosophical theory of signs and system that deals with their function in both artificially constructed and natural languages) -multisemiotic, and centrifugal-centripetal (intentional) [Nespoulous 86].
The act-symbol dichotomy refers to the notion that some gestures are pure actions, while others are intended as symbols. For instance, an action gesture occurs when a person chops wood or counts money, while a symbolic gesture occurs when a person makes the "okay" sign or puts their thumb out to hitchhike. Naturally, some action gestures can also be interpreted as symbols (semiogenesis), as illustrated in a spy novel, when an agent carrying an object in one hand has important meaning. This dichotomy shows that researchers can use gestures which represent actual motions for use in controlling devices.
The opacity-transparency dichotomy refers to the ease with which others can interpret gestures. Transparency is often associated with universality, a belief which states that some gestures have standard cross-cultural meanings. In reality, gesture meanings are very culturally dependent. Within a society, gestures have standard meanings, but no known body motion or gesture has the same meaning in all societies [Birdwhistell 70]. Even in ASL, few signs are so clearly transparent that a non-signer can guess their meaning without additional clues [Klima 74]. Fortunately, this means that gestures used for device control can be freely chosen. Additionally, gestures can be culturally defined to have specific meaning.
The centrifugal-centripetal dichotomy refers to the intentionality of a gesture. Centrifugal gestures are directed toward a specific object, while centripetal gestures are not [Sousa-Poza 77]. Researchers usually are concerned with gestures which are directed toward the control of a specific object or the communication with a specific person or group of people.
Gestures which are elements of an autonomous semiotic system
are those used in a gesture language, such as ASL. On the other
hand, gestures which are created as partial elements of multisemiotic
activity are gestures which accompany other languages, such as
oral ones [Lebrun 82]. Gesture recognition
researchers are usually concerned with gestures which are created
as their own independent, semiotic language, though there are
some exceptions.
Gesture Typologies
Another standard gesture classification scheme uses three categories: arbitrary, mimetic, and deictic [Nespoulous 86].
In mimetic gestures, motions form an object's main shape or representative feature [Wundt 73]. For instance, a chin sweeping gesture can be used to represent a goat by alluding to its beard. These gestures are intended to be transparent. Mimetic gestures are useful in gesture language representations.
Deictic gestures are used to point at important objects, and each gesture is transparent within its given context. These gestures can be specific, general, or functional. Specific gestures refer to one object. General gestures refer to a class of objects. Functional gestures represent intentions, such as pointing to a chair to ask for permission to sit. Deictic gestures are also useful in gesture language representations.
Arbitrary gestures are those whose interpretation must be learned due to their opacity. Although they are not common in a cultural setting, once learned they can be used and understood without any complimentary verbal information. An example is the set of gestures used for crane operation [Link-Belt 87]. Arbitrary gestures are useful because they can be specifically created for use in device control. These gesture types are already arbitrarily defined and understood without any additional verbal information.
Voice and Handwriting Recognition: Parallel Issues for Gesture Recognition
Speech and handwriting recognition systems are similar to gesture recognition systems, because all of these systems perform recognition of something that moves, leaving a "trajectory" in space and time. By exploring the literature of speech and handwriting recognition, classification and identification schemes can be studied which might aid in developing a gesture recognition system.
Typical speech recognition systems match transformed speech against a stored representation. Most systems use some form of spectral representation, such as spectral templates or hidden Markov models (HMM). Speech recognition systems are classified along the following dimensions [Rudnicky 94]:
· Speaker dependent versus Independent: Can the system
recognize the speech of many different individuals without training
or does it have to be trained for a specific voice? Currently,
speaker dependent systems are more accurate, because they do not
need to account for large variations in words.
· Discrete or Continuous: Does the speaker need to separate
individual words by short silences or can the system recognize
continuous sentences? Isolated-word recognition systems have a
high accuracy rate, in part because the systems know when each
word has ended.
· Vocabulary size: This is usually a task dependent vocabulary.
All other things being equal, a small vocabulary is easier to
recognize than a large one.
· Recognition Rate: Commercial products strive for at least
a 95% recognition rate. Although this rate seems very high, these
results occur in laboratory environments. Also, studies have shown
that humans have an individual word recognition rate of 99.2%
[Pisoni 85].
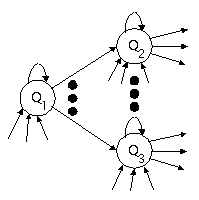
State of the art speech recognition systems, which have the capability to understand a large vocabulary, use HMMs. HMMs are also used by a number of gesture recognition systems (see Control of Memory and Display). In some speech recognition systems, the states of an HMM represent phonetic units. A state transition defines the probability of the next state's occurrence. See Figure 1 for a simple example representation of an HMM. The term hidden refers to the type of Markov model in which the observations are a probabilistic function of the current state. A complete specification of a hidden Markov model requires the following information: the state transition probability distribution, the observation symbol probability distribution, and the initial state distribution. An HMM is created for each word (string of phonemes) in a given lexicon. One of the tasks in isolated speech recognition is to measure an observed sequence of phonetic units and determine which HMM was most likely to generate such a sequence [Ljolje 91] [Rabiner 89].
From some points of view, handwriting can be considered a type of gesture. On-line (also called "real time" or "dynamic") recognition machines identify handwriting as a user writes. On-line devices have the advantage of capturing the dynamic information of writing, including the number of strokes, the ordering of strokes, and the direction and velocity profile of each stroke. On-line recognition systems are also interactive, allowing users to correct recognition errors, adapt to the system, or see the immediate results of an editing command.
Most on-line tablets capture writing as a sequence of coordinate points. Recognition is complicated in part, because there are many different ways of generating the same character. For example, the letter E's four lines can be drawn in any order.
Handwriting tablets must take into account character blending and merging, which is similar to the continuous speech problem. Also, different characters can look quite similar. To tackle these problems, handwriting tablets pre-process the characters, and then perform some type of shape recognition. Preprocessing typically involves properly spacing the characters and filtering out noise from the tablet. The more complicated processing occurs during character recognition.
Features based on both static and dynamic character information can be used for recognition. Some systems using binary decision trees prune possible characters by examining simple features first, such as searching for the dots above the letters "i" and "j". Other systems create zones which define the directions a pen point can travel (usually eight), and a character is defined in terms of a connected set of zones. A lookup table or a dictionary is used to classify the characters.
Another scheme draws its classification method from signal processing, in which curves from unknown forms are matched against prototype characters. They are matched as functions of time or as Fourier coefficients. To reduce errors, an elastic matching scheme (stretching and bending drawn curves) is used. These methods tend to be computationally intensive.
Alternatively, pen strokes can be divided into basic components, which are then connected by rules and matched to characters. This method is called Analysis-by-Synthesis. Similar systems use dynamic programming methods to match real and modeled strokes.
This examination of handwriting tablets reveals that the dynamic features of characters make on-line recognition possible and, as in speech, it is easier to recognize isolated characters. Most systems lag in recognition by more than a second, and the recognition rates are not very high. They reach reported rates of 95% due only to very careful writing. They are best used for filling out forms which have predefined prototypes and set areas for characters. For a more detailed overview of handwriting tablets, consult [Tappert 90].
Presentation, Recognition, and Exploitation of Gestures in Experimental Systems
The researchers who create experimental systems which use "gestural" input use their own definitions of gesture, which are as diverse as the biological and sociological definitions. The technology used to recognize gestures, and the response derived from gestures, further complicates this issue. Gestures are interpreted to control computer memory and displays or to control actuated mechanisms. Human-computer interaction (HCI) studies usually focus on the computer input/output interface [Card 90], and are useful to examine for the design of gesture language identification systems. Many telerobotic studies analyze the performance of remotely controlled actuated mechanisms. The study of experimental systems which span both HCI and telerobotics will illuminate criteria for the design of a gestural input device for controlling actuated mechanisms located in remote environments.
In such systems, gestures are created by a static hand or body pose, or by a physical motion in two or three dimensions, and can be translated by computer into either symbolic commands or trajectory motion commands. Examples of symbolic command gestures are stop, start, and turn. Gestures may also be interpreted as letters of an alphabet or words of a language. Alternatively, the kinematic and dynamical content of a gesture can represent a trajectory motion command. Combinations of symbolic and trajectory commands are possible in a single gesture.
Given that gestures are used to communicate information, the question arises: is it possible to consistently capture that information in a usable form? Based on the work of Wolf [Wolf 87] in studying hand drawn gestures, we analyze gestural control devices by examining the following generation, representation, recognition, and transformation questions:
· What is the gesture lexicon?
· How are the gestures generated?
· How does the system recognize gestures?
· What are the memory size and computational time requirements
for gesture recognition?
And for using gestures for device control:
· What devices are the gestures intended to control?
· What system control commands are represented by gestures?
· How are the gestures transformed into commands for controlling
devices?
· How large are the physical and temporal separations between
command initiation and response (local control versus telerobotics)?
Based on the answers to the above questions gestural control devices are classified into three categories: control of computer memory and display, local control of actuated mechanisms, and remote control of actuated mechanisms.
A number of systems have been designed to use gestural input devices to control computer memory and display. These systems perceive gestures through a variety of methods and devices. While all the systems presented identify gestures, only some systems transform gestures into appropriate system specific commands. The representative architecture for these systems is show in Figure 2.
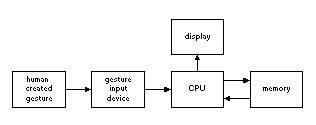
A basic gesture input device is the word processing tablet. Through the use of mouse drawn gestures, Mardia's system allows the editing of display graphics [Mardia 93]. Similarly, Rubine's system uses gestures (stylus markings) on a graphics tablet to represent word processing commands [Rubine 91].
In these representative systems, two dimensional hand gestures are sent via an input device to the computer's memory and appear on the computer monitor. These symbolic gestures are identified as editing commands through geometric modeling techniques. The commands are then executed, modifying the document stored in computer memory. Both systems require that the gesture be completed before recognition can begin.
Both systems require the calculation of feature points to represent the gesture. Mardia's system requires 27 binary valued features. Most features are computed through simple additions and comparisons, but one feature is computed using a Linear Least Squares algorithm. A decision tree is used to sort through the 27 features to determine a specific gesture classification.
Rubine's system requires the computation of 13 different features, with five features requiring multiplications and additions based on the total number of data points used to create the gesture. Again, a linear evaluation function is used to discriminate between gestures.
Murakami's system inputs the gesture data via a data-glove [Murakami 91]. Instead of geometric modeling, a neural network identifies gestures based on a finger alphabet containing 42 symbols. The data-glove, which provides 13 features, allows a wider range of motions than the mouse and stylus input devices, which enables a richer vocabulary of gestural inputs and responses. Several hours are required to train the neural network using a SUN/4 workstation.
Darrell's monocular vision processing system accurately identifies a wide variance of yes/no hand gestures [Darrell 93]. Gestures are represented by a view-based approach, and stored patterns are matched to perceived gestures using dynamic time warping. View-based vision approaches also permit a wide range of gestural inputs when compared to the mouse and stylus input devices. Computation time is based on the number of view-based features used (20 in their example) and the number of view models stored (10). Through the use of specialized hardware and a parallel architecture, processing time is less than 100 ms.
Baudel's system [Baudel 93] uses symbolic gestures to control a Macintosh hypertext program. Gestures are tracked through the use of a data-glove and converted into hypertext program commands. Because Baudel's system identifies natural hand gestures unobtrusively with a data-glove, it is more intuitive to use than a standard mouse or stylus control system. Unlike Murakami's and Darrell's systems which only identify gestures, this system uses gestural commands to control a display program, similar to the control of word processing programs. This system had difficulty identifying gestures which differed in their dynamic phase, for instance, when one gesture was twice the speed of another.
The ALIVE II system [Maes 95] identifies full body gestures, as opposed to hand gestures, through basic image processing techniques. Body gestures are used to control simulated mechanisms ("virtual creatures") located in computer memory ("virtual environment"). ALIVE II is the first system presented here which uses kinematic information from a gesture as part of a control command. The direction of the pointing arm is translated into a virtual creature's travel direction command. The body gesture itself is superimposed into the computer generated environment. A gesture interacts with a virtual environment, and the system can use background environment information to aid in interpreting the gesture command. Therefore, the user can use gestures to point at or grab objects in the virtual environment.
The Digital Desk Calculator [Wellner 91] is another kinematic gesture tracking system which controls a display. Computer graphics are displayed onto a real world desk top. The system tracks a human finger which points at real desk top items. If the system can identify the objects or text pointed at, then the graphical output display responds. Objects pointed to on the graphics overlay also effect the graphics display. For example, a user points at numbers located on a real document. The vision system scans the numbers. When the user points at a virtual calculator, the numbers appear on the calculator and are entered into computer memory. The user can perform operations by pointing at the virtual calculator's buttons superimposed on the desk. Low resolution image processing is used to obtain the approximate position of the finger through motion detection via image differencing. Then, high resolution image processing is used to determine the finger's exact position. Tracking occurs at 7 frames per second.
Starner and Pentland's system uses an HMM method to recognize forty American Sign Language gestures [Starner 95]. Acquired feature vectors are run through all possible sets of five-word sentences. The probability of the data stream being generated by each HMM model is then determined. The system picks the model which has the highest probability of generating the data stream. States consist of a probability distribution of the hand features (as opposed to the pose itself).
Weng's SHOSLIF identifies the most discriminating features of an image through a multi-class, multivariate discriminant analysis [Cui 94]. These features are categorized in a space partition tree. SHOSLIF can recognize 28 ASL signs. The calculations are multiplication intensive, based on the size of the image, the number of images in a gesture sequence, and the number of signs in the lexicon. However, the time spent searching the partition tree increases only logarithmically.
Local Control of Actuated Mechanisms.
An examination of research in mobile robotics and visual servoing systems reveals systems in which control can be conceptualized as local gestural control of actuated mechanisms. Although the "gestures" in many of these systems are created by the local environment rather than a human, interesting possibilities are suggested by analogy. A representative system architecture is shown in Figure 3.
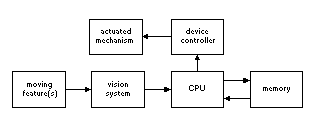
Road-following systems used by some mobile robots can be conceptualized as examples of local control through gestures. Two representative systems are Crisman's [Crisman 93] and Dickmanns' [Dickmanns 88] work. Crisman's system uses road features detected through monocular vision as navigation cues for a mobile robot platform. On a reduced color image, classification is performed by determining the probability of each pixel representing a road surface. Detection of straight roads and intersections on a SUN/4 takes 6 seconds and 20 seconds, respectively. Dickmanns' system models road features, from motion relative to the moving mobile robot, as dynamical systems. Each feature's trajectory is a gesture used to control the attached mobile platform. A Linear Least Squares calculation (with additional computations to handle noise) is used to recognize gestures at video field rate.
The Buhgler Juggler [Rizzi 92] can also be considered a local gesture control device. The system identifies and visually tracks a falling ball "gesture" and uses the dynamics of the gesture to command a robot arm to juggle via a "mirror law" calculation at field rate.
Allen's system [Allen 93] tracks a moving toy train, which can be considered a gesture, to be grasped by a robot arm. Using optical flow, updated centroids of the train are obtained every 0.25 seconds, with a probabilistic method used to obtain a model of the motion.
Kortenkamp uses static gestures, in the form of six human arm poses, [Kortenkamp 96], to control a mobile robot. Small regions in 3-D visual space, proximity spaces, are used to concentrate the system's visual attention on various parts of a human agent. Vision updates occur at frame rate, but the system can only track gestures which move less than 36 deg/sec. This architecture stresses the need to link gestures to desired robot actions. The system can also determine the intersection of a line formed from a pointing gesture with the floor of an environment, allowing a human to give a position command to a mobile robot.
Cohen developed a system which recognizes gestures which are natural for a human to create, consisting of oscillating circles and lines [Cohen 96]. Each gesture is modeled as a linear-in-parameters dynamical system with added geometric constraints to allow for real time gesture recognition using a small amount of processing tie and memory. The linear least squares method is used to determine the parameters which represent each gesture. A gesture recognition and control architecture is developed which takes the position of a feature and determines which parameters in a previously defined set of predictor bins best fits the observed motion. The gesture classification is then used to create a reference trajectory to control an actuated mechanism.
Remote Control of Actuated Mechanisms: Telerobotics.
Telerobotics refers to the control of mechanisms "at a distance". This includes both short and long range control - the mechanism can be in the next room or in earth orbit. Telerobotics also incorporates the study of relevant human-machine interfaces, so as to enable better overall control of mechanisms at a distance.
As above, the control of an actuated mechanism located in the same environment as the input device is "local control in a local environment". Remote control and telerobotics are terms used when the input device and controlled mechanism are located in physically separate environments, requiring visual communication links to enable users to see the activity of the controlled mechanisms.
Certain challenges arise when controlling mechanisms located a very large distance, due to the effect of communication time delays [Sheridan 93]. For example, when relaying a control command from the earth to synchronous earth orbit, the round trip time delay for visual feedback is several tenths of a second. The range of possible controls is limited because of added instabilities arising from time delays in feedback loops.
Research to mitigate the effects of time delays has taken the form of studying system modeling and sensor display concepts [Liu 93]. Conway uses a simulator to aid in mechanism device control, exploiting a time-desynchronized planning model that projects the future trajectory of the telerobotic mechanism (see [Conway 90] and the patent [Conway 91]). Herzinger adds additional sensors to aid user mechanism control [Hirzinger 90].
The time delay problems can also be alleviated if a symbol, representing a recognized gesture command, is sent to the remote site. However, this creates an additional "time delay": the time required to recognize the gesture. The Robogest architecture uses such a gestural control method. The Robogest system controls a robot with static hand gestures, which are recognized, converted into a command, and sent to a remote site [Schlenzig 94].
A hidden Markov model describes the six hand gestures, and recognition occurs at 0.5 Hz. Each gesture is paired with various robot behaviors, such as turn, accelerate, and stop.
Other telerobotic systems use a joystick to control the remote mechanism (see Figure 4) [Sheridan 93]. Consistent with our previous observations, a joystick is used to input "gestures" which control the remote actuated mechanism.
Unfortunately, if a gesture is generated at a local site and interpreted at a remote site, time delays cause further gesture recognition difficulties: the recognition must now take into account blurred and warped gestures. With additional processing, Darrell's system (see Control of Memory and Display) [Darrell 93] could help identify "warped"gestures.
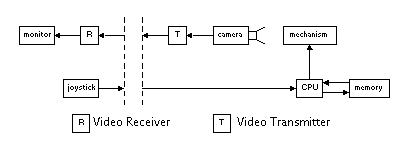
A special communication environment could be developed to take advantage of gestural inputs for the control of devices. Since gestures are visual, a video communication system could transmit a gesture from the local site to the remote site. However, a created gesture would be isolated from the device it is intended to control. If we desire gestures which appear as though they were created in the remote location, another architecture or communication environment is required. (For example, see the University of Michigan M-ROVER remote control project and a patent [Conway 97] on remote control in the visual information stream.)
Issues Concerning the Recognition and Generation of Human Generated Gestures
In addition to human-to-human communication research, the use of gestures as computer input has been studied. Wolf's research in this area examines the following concerns [Wolf 87a]:
1. How consistent are people in their use of gestures?
2. What are the most common gestures used in a given domain, and
how easily are they recalled?
3. Do gestures contain identifiable spatial components which correspond
to the functional components of command (the action to be performed),
scope (the object to which the command is applied), and target
(the location where the object is moved, inserted, copied, etc.)?
4. What kind of variability exists in a gesture, and are the deviations
predictable or random?
Wolf explored these questions by studying hand drawn two dimensional gestures which were used to edit text documents [Wolf 87a]. Hauptmann attempted to answer similar questions by examining three dimensional spatial gestures which were used to rotate, translate, and scale three dimensional graphic objects on a computer screen [Hauptmann 89]. Although the uses were drastically different (text versus graphics), the concepts and conclusions were strikingly similar.
People consistently used the same gestures for specific commands. In particular, the recognition scheme used by Hauptmann was able to classify the types of three dimensional gestures used for rotation, translation, and scaling with a high degree of consistency.
People are also very adept at learning new arbitrary gestures. Gesturing is natural for humans, and only a short amount of training is required before people can consistently use new gestures to communicate information or control devices (see [Wolf 87], [Hauptmann 89], and [Harwin 90]).
Wolf also discovered that, without prompting, test subjects used very similar gestures for the same operations, and even used the same screen drawn gestures days later. Hauptmann also found a high degree of similarity in the gesture types used by different people to perform the same manipulations. Test subjects were not coached beforehand, indicating that there may be intuitive, common principles in gesture communication. Therefore, this research illustrates that accurate recognition of gestures from an intuitively created arbitrary lexicon is possible.
In both studies, humans were used to interpret the gestures, and humans are very adept at handling noisy data and recognizing shifted data [Shepard 71]. Unfortunately, the problems of computers recognizing specific gestures were not addressed. However, these studies were among the first steps toward designing such a system.
A further complication in gesture recognition is determining which features of the gesture generator are used. In a study of representing language through gestures, McNeill and Levy [McNeill 82] have identified gestures according to physical properties. These properties include hand configuration, orientation of the palm, and direction of movement. McNeill and Levy note that gestures have a preparatory phase, an actual gesture phase, and a retraction phase (see Figure 5). Hauptmann defines a "focus" or "center'" of a gesture, used to identify and classify three dimensional gestures. Systems that are created to recognize gestures must define which aspects of the gesture creator they are recognizing.
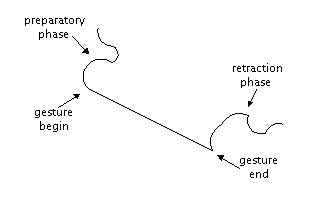
Wolf noted that screen drawn gesture variability can cause problems when one gesture begins to look like another. However, even when the gesture was not precise, enough information was conveyed to allow the system to execute the correct response. In Hauptmann's study, the variations of three dimensional gestures was not explored as much as the alignment of a gesture with respect to a manipulated object. Still, despite deviations in alignment, there was a high percentage of correct recognition.
Although, from Wolf's and Hauptmann's studies, we know that humans can recognize and differentiate between gestures, additional problems are involved in designing a system which can reliably recognize human created gestures. There are many difficulties involved because, unlike a device, a human cannot form "perfect" circles, lines, and ASL gesture motions. Furthermore, people often hesitate when starting or ending a gesture, which could confuse a recognition system.
When a system, for example, recognizes a repeated oscillatory gesture, it should not matter where on the circle or line the generation begins. To be more specific, starting a circle gesture at the top or bottom of its arc does not effect how humans recognize the gesture. Therefore, any recognition system should be able to handle such arbitrary initial positions.
Furthermore, how accurately can humans create oscillatory circles and lines of various frequencies? The human arm is a linked kinematic chain, and such oscillating motions might not be easy for it to make. In addition, between the slowest and fastest physically possible speed, gradations in oscillating frequency are possible. However, the gesture velocities for similar spatial gestures need to be distinct in order for any gesture recognition system, human or otherwise, to have a chance at accurate recognition.
Therefore, the gesture velocities for "slow" and "fast" need to separated by a distinct amount. This amount can be determined empirically by watching people make circles and determining when the velocities can be consistently distinguished. Brown [Brown 90] has determined that humans can stay within 5% of the velocity in a desired line motion. Her experiments show that people are very adept at choosing distinct motion speeds when the human pretends there is a visual target velocity to track. This trait is common in all humans and is one of the first aspects to be lost when the human brain is damaged in a specific way.
System Architecture Concepts for Gesture Recognition Systems
Based on the use of gestures by humans (see Biological section), the analysis of speech and handwriting recognizing systems (see Voice and Handwriting Recognition section), and the analysis of other gesture recognition systems (see Experimental Systems section) requirements for a gesture recognition system can be detailed. Some requirements and tasks are:
· Choose gestures which fit a useful environment.
· Create a system which can recognize non-perfect human
created gestures.
· Create a system which can use a both a gesture's static
and dynamic
· information components.
· Perform gesture recognition with image data presented
at field rate (or as fast as possible).
· Recognize the gesture as quickly as possible, even before
the full gesture is completed.
· Use a recognition method which requires a small amount
of computational time and memory.
· Create an expandable system which can recognize additional
types of gestures.
· Pair gestures with appropriate responses (language definitions
or device command responses).
· Create an environment which allows the use of gestures
for remote control of devices.
Gesture Rocognition Home Page
For a list of current research availible on the internet, please go to the Gesture Recognition Home Page. Also, if anyone wishes to add their page to the GRHP, or knows of pages which should be added, please contact ccohen@cybernet.com.
Bibliography
[Allen 93] P. K. Allen, A. Timcenko, B.
Yoshimi, and P. Michelman. Automated tracking and grasping of
a moving object with a robotic hand-eye system. IEEE Transactions
on Robotics and Automation, 9(2):152-165, April 1993.
[Baudel 93] Thomas Baudel and Michel Beaudouin-Lafon. CHARADE: Remote control of objects using free-hand gestures. Communications of the ACM, 36(7):28-35, July 1993.
[Birdwhistell 70] R. L. Birdwhistell. Kinesics and Context; essays on body motion communication. Philadelphia, PA, 1970.
[Brown 90] S. Brown, H. Hefter, M. Mertens, and H. Freund. Disturbances in human arm movement trajectory due to mild cerebellar dysfunction. Journal of neurosurgery psychiatry, 53(4):306-313, April 1990.
[Card 90] Stuart K. Card, Jock D. Mackinlay, and George G. Robinson. The design space of input devices. In Proceedings of the CHI ’90 Conference on Human Factors in Computing Systems, pages 117-124, April 1990.
[Cohen 96] Charles J. Cohen, Lynn Conway, and Dan Koditschek. "Dynamical System Representation, Generation, and Recognition of Basic Oscillatory Motion Gestures," 2nd International Conference on Automatic Face- and Gesture-Recognition, Killington, Vermont, October 1996.
[Conway 90] L. Conway, R. Volz, and M. Walker. Teleautonomous systems: methods and architectures for intermingling autonomous and telerobotic technology. Robotics and Automation, 6(2):146-158, April 1990.
[Conway 91] L. Conway, R. Volz, and M. Walker. Teleautonomous system and method employing time/position synchrony/desynchrony. U.S. Patent 5,046,022, September 1991.
[Conway 97] L. Conway and C. Cohen. Apparatus and method for remote control using a visual information stream. U.S. Patent 5,652,849, July 1997.
[Crisman 93] Jill Crisman and Charles E. Thorpe. SCARF: A color vision system that tracks roads and intersections. Robotics and Automation, 9(1):49-58, February 1993.
[Cui 94] Yunato Cui and John J. Weng. SHOSLIF-M: SHOSLIF for motion understanding (phase I for hand sign recognition). Technical Report CPS 94-68, December 1994.
[Darrell 93] Trevor J. Darrell and Alex P. Penland, Space-time gestures. In IEEE Conference on Vision and Pattern Recognition, NY, NY, June 1993.
[Dickmanns 88] E. D. Dickmanns and V. Graefe. Dynamic Monocular machine vision. Machine Vision and Applications, pages 223-240, 1988.
[Harwin 90] W. S. Harwin and R. D. Jackson. Analysis of intentional head gestures to assist computer access by physically disabled people. Journal of Biomedical Engineering, 12:193-198, May 1990.
[Hauptmann 89] Speech and Gestures for Graphic Image Manipulation. In Computer Human Interaction 1989 Proceedings, pages 241-245, May, 1989.
[Hirzinger 90] G. Hirzinger, J. Heindl, and K. Landzettel. Predictor and knowledge based telerobotic control concepts. In Proc. 1989 IEEE Int. Conf. Robotics and Automation, pages 1768-1777, Scottsdale, AZ, May 14-19 1989.
[Kendon 90] Adam Kendon. Conducting Interaction: Patterns of behavior in focused encounters. Cambridge University Press, Cambridge, 1990.
[Klima 74] E. S. Klima and U. Bellugi. Language in another mode. Language and Brain: Developmental aspects, Neurosciences research program bulletin, 12(4):539-550, 1974.
[Kortenkamp 96] David Kortenkamp, Eric Huber, and R. Peter Bonasso. Recognizing and interpreting gestures on a mobile robot. Proceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI ’96), 1996.
[Lebrun 82] Y. Lebrun. Neurolinguistic models of language and speech, pages 1-30. Academic Press, New York, 1982.
[Link-Belt 87] Link-Belt Construction Equipment Company. Operating Safety: Cranes and Excavators, 1987.
[Liu 93] A. Liu, G. Tharp, L. French, S. Lai, and L. Stark. Some of what one needs to know about using head-mounted displays to improve teleoperator performance. IEEE Transactions on Robotics and Automation, 9(5):638-649, October 1993.
[Ljolje 91] Andrej Ljolje and Stephen E. Levinson. Development of an acoustic-phonetic Hidden Markov Model for continuous speech recognition. IEEE Transactions on Signal Processing, 39(1):29-39, January 1991.
[Maes 95] Pattie Maes, Trevor Darrell, Bruce Blumberg, and Alex Pentland. The Alive System: Full-body interaction with autonomous agents. In Computer Animation ’95 Conference, IEEE Press, Geneva, Switzerland, April 1995.
[Mardia 93] K. V. Mardia, N. M. Ghali, T. J. Hainsworth, M. Howes, and N. Sheehy. Techniques for online gesture recognition on workstations. Image and Vision Computing, 11(5):283-294, June 1993.
[McNeill 82] D. McNeill and E. Levy. Conceptual Representations in Language Activity and Gesture, pages 271-295. John Wiley and Sons Ltd, 1982.
[Murakami 91] Kouichi Murakami and Hitomi Taguchi. Gesture recognition using recurrent neural networks. Journal of the ACM, 1(1):237-242, January 1991.
[Nespoulous 86] Jean-Luc Nespoulous, Paul Perron, and Andre Roch Lecours. The Biological Foundations of Gestures: Motor and Semiotic Aspects. Lawrence Erlbaum Associates, Hillsdale, MJ, 1986.
[Pisoni 85] D. Pisoni, H. Nusbaum, and B.Greene. Perception of synthetic speech generated by rule. Proceedings of the IEEE 73, pages 1665-1676, November 1985.
[Rabiner 89] L. R. Rabiner. A tutorial on Hidden Markov Models and selected applications in speech recognition. Proceedings of the IEEE, 77(2), February 1989.
[Rizzi 92] Alfred A. Rizzi, Louis L. Whitcomb, and D. E. Koditschek. Distributed Real-Time Control of a Spatial Robot Juggler. IEEE Computer, 25(5), May 1992.
[Rubine 91] Dean Rubine. Specifying gestures by example. Computer Graphics, 25(4):329-337, July 1991.
[Rudnicky 94] Alexander I. Rudnicky, Alexander G. Hauptmann, and Kai-Fu Lee. Survey of current speech technology. Communications of the ACM, 37(3):52-57, March 1994.
[Schlenzig 94] J. Schlenzig, E. Hunter, and R. Jain. Recursive identification of gesture inputs using Hidden Markov Models. Proceedings of the Second Annual Conference on Applications of Computer Vision, December 1994.
[Shepard 71] R. N. Shepard and J. Metzler. Mental rotation of three-dimensional objects. Science, 171:701-703, 1971.
[Sheridan 93] T. B. Sheridan. Space teleoperation through time delay: review and prognosis. IEEE Transactions on Robotics and Automation, 9(5):592-606, October 1993.
[Sousa-Poza 77] J. F. Sousa-Poza and R. Rohrberg, Body movement in relation to type of information (person- and non-person oriented) and cognitive style (file dependence). Human Communication Research, 4(1), 1977.
[Starner 95] Thad Starner and Alex Pentland. Visual recognition of American Sigh Language using Hidden Markov Models. IEEE International Symposium on Computer Vision, November 1995.
[Tappert 90] C. Tappert,, C. Suen, and T. Wakahara. The state of the art in on-line handwriting recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 12(8):787-808, August 1990.
[Wellner 91] Pierre Wellner. The DigitalDesk Calculator: Tangible manipulation on a desk top display. In Proceedings of the ACM Symposium on User Interface Software and Technology 91, pages 27-33, November 1993.
[Wolf 87] C. G. Wolf and P. Morrel-Samuals. The use of hand-drawn gestures for text editing. In International Journal of Man-Machine Studies, volume 27, pages 91-102, 1987.
[Wolf 87a] C. G. Wolf and J. R. Rhyne. A taxonomic approach to understanding direct manipulation. In Journal of the Human Factors Society 31th Annual Meeting, pages 576-780.
[Wundt 73] W. Wundt. The language of gestures. The Hague, Mouton, 1973.