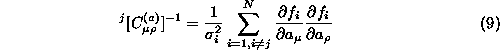We are interested in the ability of the model to predict unseen datapoints. We need to adapt our error estimation to reflect this. The usual method of unbiased prediction is to divide each element of the covariance matrix by (N-1) instead of N. We have found that, although this method correctly predicts the probable error, it can not be used to select the correct model complexity.
An alternative way to make ![]() an unbiased estimate is to estimate each covariance matrices with one datapoint left out in turn:
an unbiased estimate is to estimate each covariance matrices with one datapoint left out in turn:
![]() is now given by:
is now given by:
![]()
We can significantly speed up the computation by using a recursive estimation of covariance [1].
As we want to approximate the error on an unseen datapoint, we add a value of ![]() to the
to the ![]() diagonal of
diagonal of ![]() :
:
where ![]() is the Dirac delta function (1 if
is the Dirac delta function (1 if ![]() , 0 otherwise).
, 0 otherwise).
Figure 5 shows the ability of the model to predict unseen data. The figure was generated using unseen_error_estimation.m.
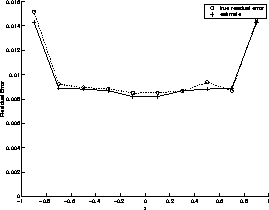
Figure 5: Unseen error prediction on ![]() with an error of
with an error of ![]() on each point
on each point