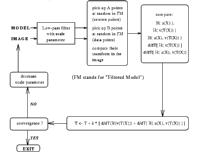
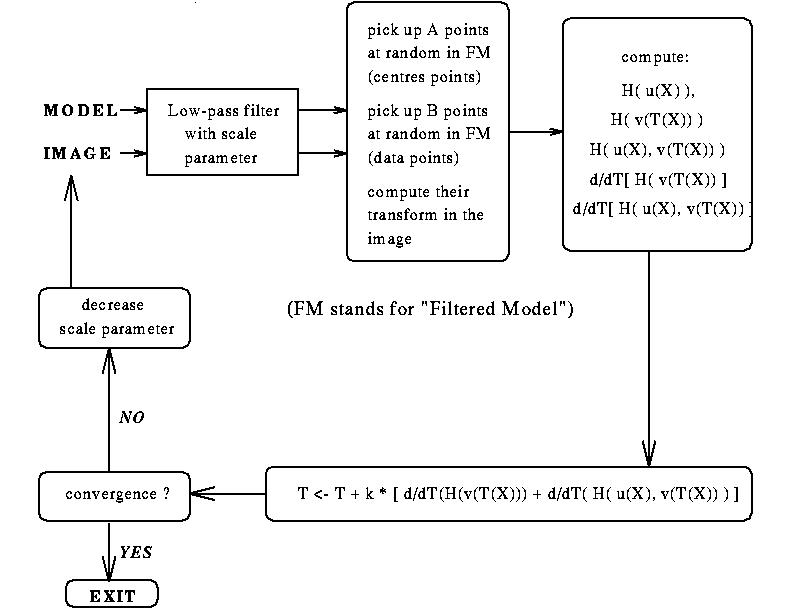
The optimisation
scheme
Since we can't compute the exact entropy of
the image and/or the model, (because the complexity of the algorithm is
quadratic in the number of random points), we are actually using a stochastic
gradient descent scheme, which leads to the nearest local optimum of the
mutual information (with effective escape from "small local minima") in
a reasonable time, just using this empirical entropy. We have implemented
a multi-scale method which prevent the algorithm of being lost too often
in local minima.
Click on the diagram to see the enlarged
version