Model-based Rendering usually recovers the geometry of the real scene and then render it from desired virtual view points. Methods for the automatic construction of 3D models have found applications in many field, including Mobile Robotics, Virtual Reality and Entertainment. These methods generally fall into two categories, active and passive methods.
Active methods often require laser technology and structured lights or video, which might result in very expensive equipments. However, new technologies have extended the range of possible applications, (Levoy et al. [29], Hogg et al. [24], Fisher et al. [18]), and new algorithms have improved the ability to cope with problems inherent to laser scanning, (Castellani, Livatino and Fisher [7], [6], Stulp [46], Davis et al. [14]).
Passive methods usually concerns the task of generating a 3D model given multiple 2D photographs of a scene. In general they do not require a very expensive equipment, but quite often a specialized set-up, (e.g. Kanade et al. [25], Fuch et al. [20], Tseng and Anastassious [49]). Passive methods are commonly employed by Model-Based Rendering techniques.
Some of the research contributions in the field have proposed fully working systems for specific applications, some other have instead mostly focused on one or some of the involved aspects but provided a general application context. For example, Moezzi et al. [34], [35], propose an entire specific system for image-acquisition, model-construction and play-back interactive rendering, while Ofek et al. [36], mostly focus on extraction of textures from a generic video sequence for high-fidelity model-based texture mapping.
There can well be different ways of generating 3D models from photographs, from simple 3D silhouette models dynamically cut-out and texture-mapped from video-sequences, (Livatino and Hogg, [31]), to polyhedral visual hulls generated by multiple-view silhouettes 2and estimated stereo disparities, (Li, Schirmacher and Seidel, [30]). A survey of image-based volumetric scene reconstruction can be found in the works of Slabaugh et al. [45], Dyer [17], and Forsyth and Ponce [19].
In this section summaries of some representative works in Model-Based Rendering are presented. The authors name at the top of each summary identifies presented approach together with a "pioneer" reference publication.
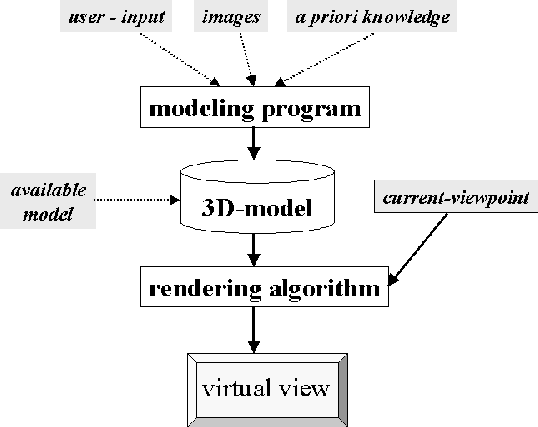
Figure 2 represents typical computational steps in presented works.
Kanade-Narayanan-Rander [25]
Kanade et al. coin the term Virtualized Reality to characterize a system that is able to capture dynamic scenes and render them from different virtual viewpoints. This in order to immerse viewers in a virtual reconstruction of real-world events.
A visual event such as an actor motion is captured using many cameras (from six cameras to many more) placed all around a hemispherical dome 5 meters in diameter that cover the action from all sides. Consequently, several real-images of the scene are acquired.
The 3D structure of the event, aligned with the pixels of the image, is computed from a few selected directions using a stereo technique. In particular, depth information are recovered by stereo matching and the combination of depth/color data converted into a triangle mesh model on graphics rendering engine.
The authors use a multi baseline stereo algorithm to compute time-varying 2.5-D depth maps representing the scene geometry. Stereo-based depths are aligned with the pixels of their corresponding images.
Based on the viewer's position, the depth map from the closest camera is used to render the scene. Triangulation and texture mapping enable the placement of a "soft-camera" to reconstruct the event from any new viewpoint. Virtualized reality allows a viewer to move freely in the scene, independently from the angles used to record the scene.
Among the advantages: the system provides 3D structure of events for virtual reality applications, safe training, user guided visualization of events (for entertainment).
Among the disadvantages: the system does not allow for an on-line processing, (but only play-back) due to the high computational cost.
Class of Approaches: volumetric reconstruction [19].
Fuchs-Bishop-Arthur-McMillan-Bajcsy-Lee-Farid-Kanade [20]
This paper proposes the use of image data acquired by many stationary cameras installed around a small environment such as a conference room and the use of stereo methods to compute time-varying 2.5-D depth maps representing the scene geometry.
The authors propose to reconstruct the real world scene from a large amount of fixed cameras by applying a correlation based depth from stereo. Wide baseline stereo is used to extract depths maps, which are updated, maintained, and then combined to create a virtual scene from viewer current position and orientation. The data can be acquired in a remote site while the viewer position and orientation is local.
In shown results a depth image of a human subject is calculated from 11 closely spaced video camera positions. The user is wearing a head-mounted display and walks around the 3D data that has been inserted into a 3D model of a simple room.
Among the advantages: the system is suitable for teleconferencing applications, provide 3D structure of events for virtual reality applications, safe training, user guided visualization of events (for entertainment).
Among the disadvantages: only play-back is allowed, (the speed of the stereo algorithm was much limited by the poor machine performance).
Tseng-Anastassiou [49]
This paper proposes the use of images captured simultaneously by a set of equi-distant cameras with parallel axis, in vertical and horizontal lineups and the use of stereo methods to compute time-varying 2.5-D depth maps representing the scene's geometry. Virtual images are generated by interpolating real views scanline-by-scanline based on disparity information.
Within the MPEG standardization the transmission of a stereoscopic (left and right views) sequence is possible by utilizing the proposed high profile double layer structure of temporal scalable coding. The left stereo sequence is coded on the lower layer and provides the basic non-stereoscopic signal. The right stereo bitstream is then transmitted on the enhancement layer and when combined with the left view results in the full stereoscopic video. After decoding the two extreme views, an "intelligent" scheme is proposed to interpolate the intermediate views.
Among the advantages: MPEG can be applicable to two sequences of stereoscopic signals through the use of spatial and temporal scalability extensions, easy and direct implementation convenience, graceful stereo image degradation, and high SNR reconstructions, compression, and improvement in image reconstruction.
Moezzi-Tai-Gerard [35]
This paper proposes to recreate the original dynamic scene in 3D, the system allows photo-realistic interactive playback from arbitrary viewpoints using video streams of a given scene from multiple perspectives.
The idea is to capture multiple images of an object and then construct a 3D textured model of an object and use view-dependent texture mapping for rendering (from any view angle). The authors use 17 cameras surrounding a stage area to record various performances. The 3D model is extracted by an accurate recovery of the 3D shapes of dynamic or foreground objects by means of a volume occupancy method.
This work is based on Moezzi et al. [34] who construct a visual hull, i.e. a conservative shell that envelops the true geometry of the objects, consisting in the shape obtained from silhouette image data. The visual hull is constructed using voxels in a off-line processing system. The shape of the visual hull can be determined from object silhouettes in multiple images taken from different viewpoints, (the silhouette information is obtained by background subtraction).
In order to render the obtained model from a virtual camera point of view, a true 3D model is created with fine polygons, each separately colored. There is no need for texture rendering support and the viewing position plays no role in the modeling process.
The proposed approach can use standard object formats such as VRML delivered through the Internet and viewed with VRML browsers. Hence, the approach is suitable to the client-server scenario because real views do not need to be transferred to the client.
Among the advantages: accurate 3D model reconstruction, no texture rendering support needed, use of VRML format for browsing, suitable for transmission.
Among the Disadvantages: need for a off-line processing.
R. Szeliski proposes different ways of computing image warping and he recovers a 3D model depending on the application: 2D planar image mosaicing, partial 3D model recovery and fully 3D model recovery. When recovering a full 3D model the utilized techniques are: volumetric description from silhouette or stereo matching from image sequence.
In volumetric description, the 3D model is recovered from a binary silhouette of an object against its background, local optical flow is computed and converted into sparse 3D point estimates, and the occluding contours of an object are tracked to generate 3D space-curves.
These techniques are suitable to reconstruct an isolated object undergoing known motion. Similar techniques can however be used to solve a more general 3D scene recovery problem where the camera motion is unknown. In particular, it is proposed the projective motion algorithm for determining an object motion based on recovering "projective depths".
Among the advantages: possibility for automatically creating large panorama images of arbitrary shape and detail.
Among the Disadvantages: limited 3D rendering.
CohenOr-Rich-Lerner-Shenkar [13]
The paper proposes the use of a textured mapped voxel-based model to represent terrains and 3D objects.
The use 3D voxels-model is proposed because this fits better a high-detailed real-object, such as a real terrain, than a polygonal-model. Terrains are textured from b/w photographs and some objects (e.g. house buildings) are textured by a more detailed texture. The author uses b/w photographs because of the applications on Missile cameras. This leads to generate a less realistic rendering than using colors but it allows for real-time performance.
The system is based on a portable software rendering able to generate photo-realistic images in real-time (on a parallel machine). This performance is due to an innovative rendering algorithm based on discrete optimized ray-casting algorithm, accelerated by ray-coherence and multiresolution transversal.
Among the Advantages: real-time fly-through, portable software rendering, photo-realism.
As mentioned above, some of the research works have mostly focused on one or few aspects involved in realistic visualization of virtual-views. These works are also relevant for model-based rendering. For example, an automatic extraction of textures from a generic video sequence could represents a convenient approach to model-based texture-mapping, as proposed by the research work following summarized.
Ofek-Shilat-Rappoport-Werman [36]
The proposed method focus on automatically deriving realistic 2D textures from video sequences for texture mapping purposes. The term realistic is here used to indicate textures free of disturbing effects such as highlights, reflections, shadows, etc.
The recorded scene is a video-sequence where the object of interest is viewed in different resolutions and different perspectives. A simple 3D model may also be provided by the user to improve system performance. The authors propose a model given by hand from five point at least. The authors also discuss an automatic model generation through a mask.
A multiresolution texture is proposed and for each pixel the color is computed by a weighted average from correspondent pixels in the video sequence. The multiresolution texture is proposed to be exploited for generation of virtual views of recorded scenes.
The proposed approach allows for identification of undesired features like highlights, reflections and shadows. The system is able to recognize the above features by looking at patches which contain very sharp step edges, since these are most likely to occur with depth discontinuities or reflective highlights. The system is then able to conveniently remove the disturbing features from the texture.
The image quality in resulting textures is as high as the original video-stills and so suitable to be used as reference-views. During visualization reference-views can be selected view-dependently based on current observation viewpoint, and the closer reference-view can be used for the mapping.
Among the advantages: suitable for mapping textures on 3D models from video-sequences, suitable for merging texture appearing in different resolutions, efficient storage of the resulting texture in a multiresolution data structure.
The following two methods are related to both model- and image- based rendering, but they represent different implementations. In the first work, the authors propose both the two approaches one at a time, for the same application contexts. In the second more complex approach, the system generates virtual views based on both, a reconstructed geometric model and an image-based texture-mapping (view-dependent).
The authors present a methods allowing for the exploration of a 3D scene based on triangular-mesh model recovered from 2D views. A comparison between the proposed method for virtual view-synthesis based on a sparse match and a view-synthesis based on a dense match, [4], is also proposed, (earlier in [3] and later in [5]).
The 2D views are photographs of a real scene and proposed as reference views. From these references either a projective model ([4]) or a triangular 3D mesh ([3]) is estimated. Hence, virtual views can be generated to allow a user to virtually navigate inside the scene and appreciate the tri-dimensional structure.
The method based on a dense match uses point reprojection. This method starts with a dense matching between the reference views and then each matched couple is reprojected using the trilinear relations to generate a new view from arbitrary viewpoints.
The method based on sparse matches uses model-based rendering (based on textured triangles). First, a sparse match (e.g. corner points) between the reference views is computed. Then, a textured filtered triangular mesh is calculated based on an initial Delaunay triangulation. Eventually, new views are synthesized by a model-based rendering.
The realistic effect in the first method is due to the fact that each pixel is directly re-projected from the real references views to the virtual view. In the second method the realistic effect is due to the fact that triangles are filled in with the texture from the reference views.
Among the advantages: no camera calibration, no 3D-model of the scene with the first method (a projective model is enough), fast synthesis, applications to high-rate video compression (only the references views and the displacement of the camera need to be transmitted and transmitted data does not depend on image size), fast sparse matching and no "holes" in the synthesized views with the second method as well as a mostly automated fast and realistic scene modeling.
Among the disadvantages: not real-time matching phase because of the computed dense-matching (first method), "holes" in the synthesized images arising from unmatched points and from adjacent pixels in the reference views which are not adjacent in the synthesized view (first method), more than two reference views are needed because of the trilinear tensor (first method), false matches are exacerbated if visualization is required from viewpoints distant from the original viewpoint (second method).
Debevec-Taylor-Malik [15]
The system developed by the authors use photographs and an approximate geometry to create and render realistic models of architectures.
The system requires only a small number of photographs, i.e. fews different views of the object, and a few indications to specify an approximate geometry and rough correspondences between the photographs. A method for photogrammetric modeling implemented on an interactive modeling program (called "Façade") is proposed for this purpose.
The model is then refined by means of proposed model-based stereo, which exploits estimated geometry (a coarse object model) and epipolar relations, to match stereo views on a wide baseline. In particular, by re-projecting one image of the stereo pair from the other image viewpoint. In this way, the foreshortening problem for the wide baseline stereo pair is eliminated and the stereo reconstruction can be done more robustly.
When an object is rendered, this is textured by proposed view-dependent texture-mapping technique which interpolates textures coming from photographs which are closer to current viewpoint. In particular, the interpolation is performed using a geometric model to determine which pixel from each input image corresponds to the desired ray in the output image. Among the corresponding rays, those that are closer in angle to the desired ray are weighted to make the greatest contribution to the interpolated result.
A method for averaging textures of neighboring regions in case when regions are textured from different image-sources is also proposed, in order to avoids seams and abrupt transitions of textures.
A view-dependent texture mapping is later proposed in [16] to further reduce the computational cost and have smoother blending, by means of visibility processing, polygonal view-maps, and projective texture-mapping.
Among the Advantages: sparse set of reference images, wide-baseline stereo matching, realistic response.
Among the Disadvantages: projective texture mapping involves expensive computation, the visibility problem needs to be addressed, texture seams may arise.
Class of Approaches: explicit-geometry rendering [44], volumetric reconstruction [19].