
Figure 13: Matching the view model to segmented depth data


Assuming object recognition or location is based on primitive matching, several constraints may be employed to limit combinatorial complexity, including type definition, unary properties such as surface area, pairwise geometric constraints or concentration on local primitive groups. Feature grouping by CVs may be used to reduce the combinatorial complexity of matching and pose estimation.
Each scene or model primitive may be represented by a point vector, so that a minimum of two matching primitives is required to solve for the pose. Normal and axis vectors, and central and central axis points are used for planes and cylinders respectively. Pose determination is based on minimisation of the least square error between the model and scene point vectors using singular value decomposition. For example, Figure 13, below, illustrates pose definition on the basis of 5 matched primitives between a segmented depth image and a CV. This shows some error in the computed pose, due to the inaccurate definition of the scene control points.
Figure 13: Matching the view model to segmented depth data
Comparative accuracy of pose determination: we have compared pose estimates by matching a full object model to random 3D rotations of that model subject to random movement of the feature point vectors. From sets of 1000 trials on a number of modelled objects, we were able to conclude that there was no significant difference between the mean accuracy of the full set of object features and the reduced sets of the CVs, although the standard deviation was greater in the latter case.
The complexity of viewpoint modelling: considering an object with n features, we can define an upper limit of  ways of choosing m model features to match m features in the scene data, as order is important.
The probability of finding a correct solution within p random selections, assuming further that the same selection may be chosen more than once, is
ways of choosing m model features to match m features in the scene data, as order is important.
The probability of finding a correct solution within p random selections, assuming further that the same selection may be chosen more than once, is  , which implies that it would take 145 selections of 2 features from a 15 feature model to obtain a 50 per cent chance of the correct selection. Clearly, this is not a sensible strategy, but it does provide a baseline for comparison.
, which implies that it would take 145 selections of 2 features from a 15 feature model to obtain a 50 per cent chance of the correct selection. Clearly, this is not a sensible strategy, but it does provide a baseline for comparison.
If we assume a known CV model which corresponds to a given view, then this reduces the number of features which may be chosen. For example, if n=8 and m=2, then this leads to a 50 per cent chance of the solution after 38 selections. Thus, if the correct CV is known or may be indexed by a view-specific property of the scene, a reduction in matching complexity is expected.
If the correct CV is not known, the situation is more complicated, since all CV's may have some features in common with an arbitrary view, but the appropriate CV is most similar. Assuming pessimistically that the correct pair only occurs in one CV, then we require 194 selections, but this is an unlikely, worst-case model. In general, we might anticipate no advantage over a full object model.
Figure 14 shows histograms from matching an object model and a randomly selected CV of the stand against 1000 random scenes. The horizontal axis depicts the number of hypotheses generated before successful pose definition. The vertical axis shows the number of trials. As anticipated there is no significant difference between the two histograms.
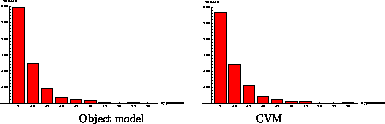
We have also generated similar data for pre-selected view models, anticipating a reduction in complexity. In fact this did not occur as the histograms were substantially the same as those in Figure 13, above. To explain this, consider the stand model.
The model has 15 features, but the choice is further constrained. Hypotheses may only be generated for matches between features of similar type, i.e. cylinder to cylinder or plane to plane, and similar radius of curvature for cylinders. There are 55 plane-plane (pp), 6 cylinder-cylinder (cc), and 44 plane-cylinder (pc) choices, each of which may occur in either order, making 210 in all. Of the 110 pp possibilities, there are 86 with non-parallel vectors, but each plane with a vector other than v1 through the central axis has a symmetric pair. Hence there are 2 out of 86 possible correct solutions. Of the cc cases, only those using the lower, largest cylinder, have non-parallel vectors, and these are constrained by radius compatibility, so that there are 3 out of 3 possible correct solutions. For pc cases, the order is determined by type compatibility, and 17 possibilities are eliminated by parallel vectors, leaving 8 out of 27 correct solutions, allowing for symmetry. Hence, the probability of selecting 2 point vectors which allow a pose solution at random is 13 out of 116, or 0.112. Thus, a correct match is expected within the first 5 hypotheses in 55 per cent of the cases. This analysis corresponds closely to the data of the leftmost Figure 13 in which about 59 percent are located in the first five hypotheses; the mean number of hypotheses is 6.22.
A similar result is obtained in the rightmost histogram. Although there is a considerable variation in the number of visible features, e.g from four (2 planes, 2 cylinders) to ten (6 planes, 4 cylinders) in , Figure 12 the mean number of hypotheses is 6.64.
Finally, we consider the case where model invocation has occurred, i.e. there is some characteristic within the view which allows pre-selection of the correct CV. A reduction in complexity was expected, but does not occur. (The mean number of hypotheses is 6.67). In fact, the possible gain of feature grouping by viewpoint is eliminated by two factors. First the constraints imposed by type and value checking are dominant in reducing the complexity of the other cases, and second the object is symmetric, so that it is (almost) invariably possible to find a pair of matching features between a random view and a CV model.



[ Viewer Centred Representations: Contents |
Computing and using inspection-oriented VCRs ]