 Introduction
Introduction

Two-dimensional images of intensity do not give explicit information
about depth,
and hence do not relate directly to a three-dimensional environment.
Although there are many applications of computer vision which are
specifically two-dimensional, for example microscope slide scanning
and to a certain extent printed circuit board inspection, there are
many other applications which require knowledge of the three-dimensional
world, for example robotic assembly.
Humans are able to infer a great deal of depth information directly
from two-dimensional photographs, but machine inference of these properties
has proved difficult.
Where two-dimensional images have been used in three-dimensional applications,
a set of rigid body models is almost invariably used to deduce 3D geometry
from one or more 2D projections.
The first objective of a 3D vision system is to acquire a
depth map,
that is a two dimensional array of ``pixels'' which encodes
the depth of the viewed scene element from the point of view
of the sensor.
In recent years, digitised depth data has been derived from both active and
passive systems; the active systems have been dominated by the laser
time-of-flight and triangulation techniques,
whereas the principal passive techniques have been
stereo ranging and depth from motion,
which employ more than one 2D image and make comparisons
between them.
There has also been work on passive techniques to derive depth
information from single 2D images, notably
shape-from-shading and shape-from-texture.
In a 3D image, the shape of the visible image regions should approximate
the shape of the corresponding object surfaces in the field of view.
In contrast to 2D brightness data, the 3D depth data depends only on
the object and viewing geometry, and may be independent of the level
of illumination and surface reflectance and markings; problems of shadows
and specular reflections may be eliminated.
Therefore the problem of recognising objects by their shape should be
less problematic than in 2D images.
An intermediate goal of many 3D vision systems is to produce a
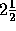 D sketch
of the viewed scene, as illustrated in figure 1.
This is a viewer centred representation, which uses surface primitives of
uniform small size.
Each dot represents the depth of the object, z, with
respect to the sensor
field of view, usually defined as a rectangular region
D sketch
of the viewed scene, as illustrated in figure 1.
This is a viewer centred representation, which uses surface primitives of
uniform small size.
Each dot represents the depth of the object, z, with
respect to the sensor
field of view, usually defined as a rectangular region 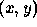 .
The orientation of the needles denotes the direction of a unit surface
normal at each point in the
.
The orientation of the needles denotes the direction of a unit surface
normal at each point in the 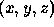 grid.
In addition to the explicit depth and surface information, the description
includes a representation of contours of surface discontinuity, which
may correspond to changes in object boundary curvature ( which are explicit
in a 3D object model ), or occluding surface boundaries ( which may not be
explicit in the 3D boundary model if the surface is curved ).
grid.
In addition to the explicit depth and surface information, the description
includes a representation of contours of surface discontinuity, which
may correspond to changes in object boundary curvature ( which are explicit
in a 3D object model ), or occluding surface boundaries ( which may not be
explicit in the 3D boundary model if the surface is curved ).
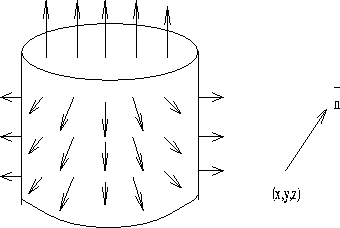
Figure 1: The 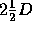 sketch
sketch



[ Contents |
Stereo imaging ]
Comments to: Sarah Price at ICBL.