ASR in ICASSP 2020
This note summarizes my quick pass over the papers in the ASR sessions of ICASSP 2020. We will look at four different aspects, namely research questions, institutes, data sets, and models. Since “a problem well put is half-solved”,1 in contrast to other conference reviews, the note will not discuss the proposed approaches. Instead, we will focus on research problems. The goal of the note is not to be comprehensive, but to give a sense of the current state of ASR, i.e., the playing field, the major players, the threshold of publishing, and open questions.
Below is a list of ASR-related sessions in ICASSP 2020. As an aside, this ICASSP is the first virtual conference for the speech community, and the presentations are all recorded and online.
- End-to-end Speech Recognition I: Streaming
- End-to-end Speech Recognition II: New Models
- End-to-end Speech Recognition III: General Topics
- Speech Recognition: Acoustic Modelling
- Speech Recognition: Acoustic Modelling II
- Speech Recognition: General Topics
- Speech Recognition: Representation and Embeddings
- Speech Recognition: Adaptation
- Speech Recognition: Confidence, Errors and OOVs
- Robust Speech Recognition
Research Questions
Research problems and questions are two sides of the same coin, and a research question is typically motivated by an existing problem. It is relatively easy to identify the research questions in a paper if there is one. The sentences that start with “however” are the usual suspects.
The following is a list of research questions collected (manually) based on the abstracts. Though the session names mention speech recognition, not all papers actually use ASR, and those are excluded.
- Latency issues in seq2seq (Sainath et al.; Inaguma et al.; Li et al.; Dong and Xu; Tian et al.)
- Latency issues in transformers (Moritz et al.)
- High computational cost in transformers (Winata et al.; Fujita et al.)
- TTS as data augmentation (Wang et al.)
- Training seq2seq as a rescoring model (Sainath et al.)
- Flat attention in long sequences (Xue et al.)
- Pre-training the decoder of seq2seq (Pham et al.)
- Memory issues when training RNN-T (Hu et al.)
- Tuning and computational issues for LSTMs (Bozheniuk et al.)
- Overfitting in large seq2seq (Nguyen et al.)
- Speaker scarcity for low resource languages (Du and Yu)
- Data scacity for many applications and locales (Singh et al.)
- Accent variability (Chen et al.)
- Learning representation from unlabeled audio (Ravanelli et al.)
- Time-domain source separation for ASR (von Neumann et al.)
- Speech enhancement for ASR (Kinoshita et al.)
- Robustness in noisy conditions (Zhang et al.)
First, I am surprised that the majority of papers simply start off by saying “We present ...” or “We propose ...” without pointing out problems or questions at all. While reverse engineering a problem or a question from the proposed approach can be done, the above list only includes papers with an explicit problem or question stated.
Even though the list is limited, it does reflect the concerns on latency, computation and memory requirements, overfitting, utilizing unlabeled data, low-resource settings, and robustness. Some problems are more concrete than others. Solutions usually become straightforward once the problems are clearly stated, such as those in Xue et al. and Pham et al. Other problems are general and broad, and are mostly used to narrow the scope of a paper.
Latency is one major theme this year, with a dedicated session on streaming. Coincidentally (or not), all but one paper in the streaming session have a clear problem statement.
Institutes
The following figure lists the number papers accepted from an institute or a company. With or without a problem statement, the papers are included, except those that do not involve ASR.
Instead of going through all affiliations, I only assign a paper to its “major” affiliation. For example, if the paper is a result of an internship, the paper is assigned to the company where the internship happened. If a paper has two major affiliations, I assign the paper to the two institutes. If a paper has multiple affiliations without a clear majority, I assign it to the first author's institute.
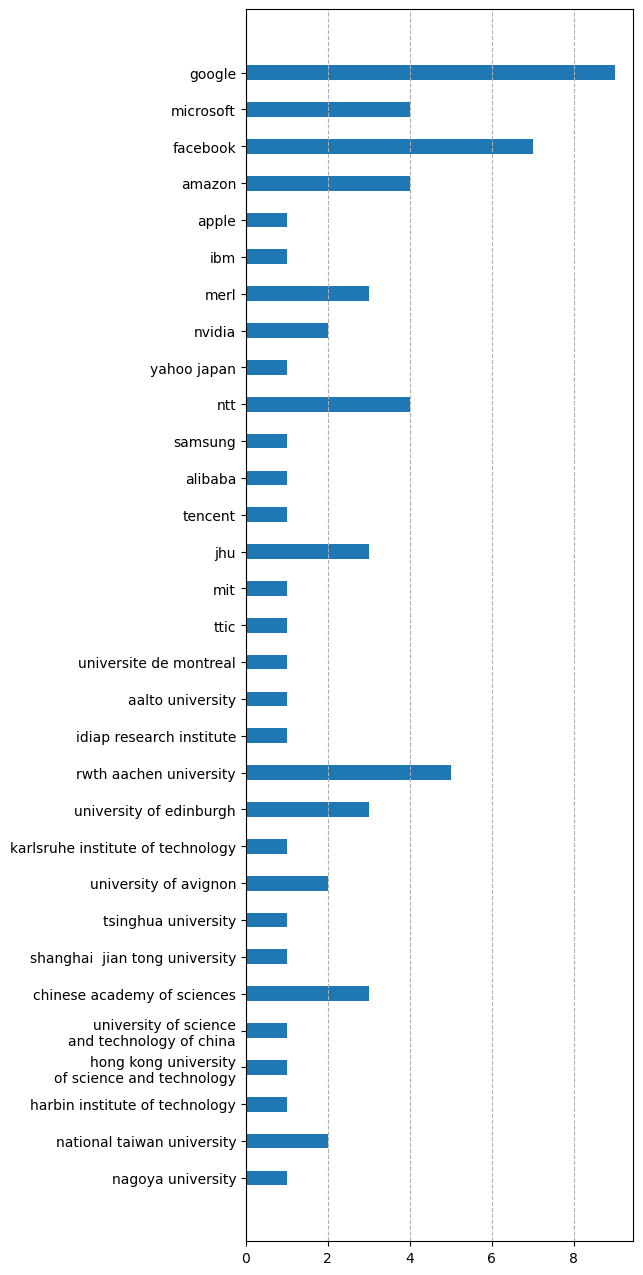
It is clear from the figure that the majority of ASR research happens in companies in the North America. Other companies working on ASR are from Japan, South Korea, and China.
Compared to companies, only few institutes are (still) working on ASR in the North America, with most of the papers coming from JHU. In Europe, RWTH Aachen University and University of Edinburgh are the two major institutes that work on ASR. Other institutes working on ASR are from China, Taiwan, and Japan.
Data Sets
The following figure shows the number of times a data set is used in these papers.
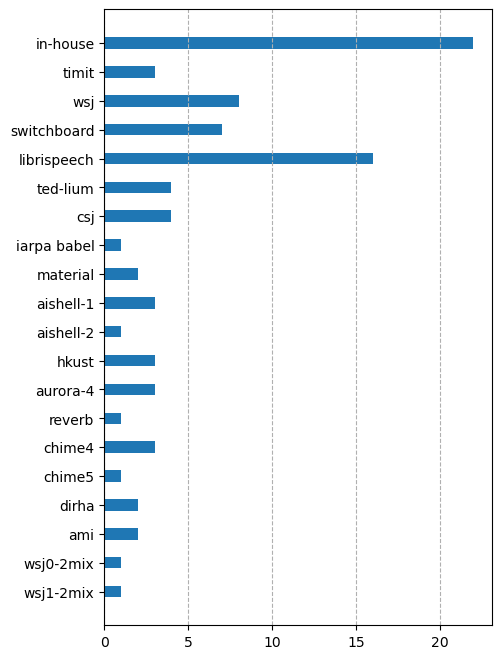
A large number of papers, particularly those from companies, report results on their in-house data. This is not surprising given how many papers are now from companies.2 It is not the first time companies report numbers only on their own in-house data, and the practice becomes more prominent ever since 2012, when deep learning took over ASR. You also do not need to talk to industry people to realize the reason. Companies worry results coming out of small data sets do not generalize in the industrial setting. On the other hand, academia is having trouble accessing large quantities of data, and even if they do have the data, the amount of compute in individual labs is certainly not comparable to companies.3
LibriSpeech, the largest publicly available English speech corpus, comes second. Other standard corpora for ASR, such as TIMIT, WSJ, Switchboard, are still being used. Outside of English, there are CSJ for Japanese, AISHELL-1, AISHELL-2, and HKUST for Mandarin Chinese. AURORA4, Reverb, Chime4, Chime5, and DIRHA are used for robust speech recognition. AMI is typically used for distant speech recognition. WSJ0-2mix and WSJ1-2mix are synthetic data sets for multi-talker ASR.
Models
The following figure shows the number of times a neural architecture is used in these papers. The LSTM bar is used to exclusively denote unidirectional LSTMs, which are heavily used in the streaming setting to minimize latency. The CNN bar includes all CNN variants, such as ResNet and time-depth separable convolutions.
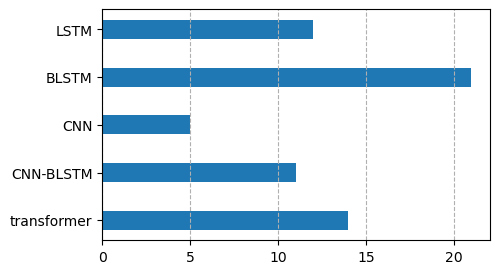
The most popular architecture is bidirectional LSTM. Transformers enter ASR relatively recently, but are steadily building up momentum.
As opposed to architecture families, it is hard to have a clear chart showing different configurations used in the papers. Even within the same architecture family, there is no single configuration that works across data sets. The configuration typically depends on the data set size and the type of speech in the data set. Regardless, it is not hard to see papers using six (if not more) layers of bidirectional LSTMs.4
The following figure shows the number of times a model is used in these papers. For some reason, some papers that use hybrid models do not explicitly mention HMMs. Some papers use CTC in a hybrid manner, while some use CTC without a lexicon and a language model.
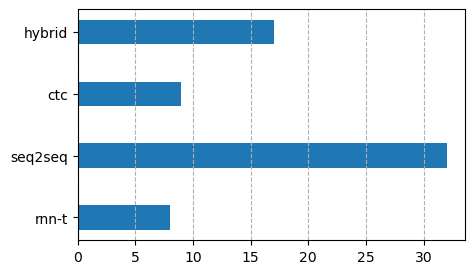
Sequence-to-sequence models are currently the popular ones. Many still use hybrid models because they are tough to beat. RNN transducer seems to be gaining momentum.
There is a correlation behind the community's preference. Just like Kaldi, ESPnet provides a suite of recipes for most ASR data sets. Its default configuration, seq2seq with CNN-BLSTM (and now transformers), is heavily built upon, and that partly explains the popularity of CNN-BLSTM, seq2seq, and even transformers.
| 1 | John Dewey, “Logic: Theory of Inquiry,” 1938 |
| 2 | The field of speech has always had strong ties to the industry. The first paper from Google involving ASR is surprisingly the famous one by Mohri, Piereira, and Riley (Speech Recognition with Weighted Finite-State Transducers, in Springer Handbook on Speech Processing and Speech Communication, 2007). Another early paper from Google is “Deploying GOOG-411: Early Lessons in Data, Measurement, and Testing” by Bacchiani, Beaufays, Schalkwyk, Schuster, and Strope, in 2008. Bacchiani et al. were already reporting results on in-house data. Other companies in the field before Google are BBN, IBM, Nuance, AT&T, and Microsoft, each of which has a preference on what data to report results on. |
| 3 | A potential solution is to increase the size and the diversity of the test sets. |
| 4 | Not that I recommend it, but I have seen papers using 6-layer BLSTM on TIMIT. |