In this section we develop an example ![]() Prolog program
which demonstrates how to encode a simple language with names, binding,
and capture-avoiding substitution.
Prolog program
which demonstrates how to encode a simple language with names, binding,
and capture-avoiding substitution.
For our first example, consider the typed ![]() -calculus (a notation for
anonymous function definitions). Its syntax is summarized by the
following grammar
-calculus (a notation for
anonymous function definitions). Its syntax is summarized by the
following grammar
id : name_type. exp : type. var : id -> exp. app : (exp,exp) -> exp. lam : id\exp -> exp. tid : name_type. ty : type. tvar : tid -> type. arrow : (ty,ty) -> ty.
Since identifiers, expressions, and types are just terms,
![]() Prolog can be used to define interesting functions and
relations among such terms. These definitions tend to be
significantly closer to their
``paper'' presentations than is usual for either functional or logic languages.
For example, the following rules express the syntax and typability relation
for simply-typed
Prolog can be used to define interesting functions and
relations among such terms. These definitions tend to be
significantly closer to their
``paper'' presentations than is usual for either functional or logic languages.
For example, the following rules express the syntax and typability relation
for simply-typed
![]() -terms:
-terms:
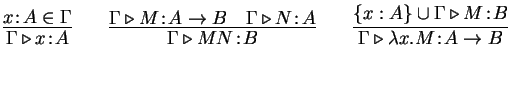
pred of([(id,ty)],exp,ty)
of(Gamma,var(X),A) :- mem((X,A),Gamma).
of(Gamma,app(M,N),B) :- of(Gamma,M,arrow(A,B)),
of(Gamma,N,A).
of(Gamma,lam(x\M),arrow(A,B)) :- x # Gamma,
of([(x,A)|Gamma],M,B).
In Prolog, we might instead encode a binding
![]() as
a term
as
a term
![]() ``x''
``x''![]() ``x''
``x''![]() , that is, using strings or
some other data for variables.
In
, that is, using strings or
some other data for variables.
In ![]() Prolog, we think of
Prolog, we think of
![]() as a term constructor mapping abstraction terms
as a term constructor mapping abstraction terms
![]() to
to
![]() . This view of the world is somewhat similar to that adopted in
higher-order abstract syntax, where
. This view of the world is somewhat similar to that adopted in
higher-order abstract syntax, where ![]() is (somewhat circularly)
defined as a constructor with type
is (somewhat circularly)
defined as a constructor with type
![]() . But
although there are similarities (for example, both function variables
and abstracted names admit equality up to
. But
although there are similarities (for example, both function variables
and abstracted names admit equality up to ![]() -equivalence), the
abstraction type is quite distinct
from the function type: for example, there is no built-in application of
abstractions, and names are ground terms that can escape the scope of
abstractions in limited ways (as does "x" in the last clause of "of").
-equivalence), the
abstraction type is quite distinct
from the function type: for example, there is no built-in application of
abstractions, and names are ground terms that can escape the scope of
abstractions in limited ways (as does "x" in the last clause of "of").
Another interesting relation (or function) on ![]() -terms is
substitution. For example,
-terms is
substitution. For example,
![]() .
In the
.
In the ![]() -calculus, we ask that
substitution not essentially change the ``meaning'' of a term (as a function).
To illustrate this point, consider the following flawed
definiton of substitution:
-calculus, we ask that
substitution not essentially change the ``meaning'' of a term (as a function).
To illustrate this point, consider the following flawed
definiton of substitution:
The classical approach to this problem is to assume that bound variables are
always ``renamed away'' from the all free variables (this is called
Barendregt's variable convention). Subject to this convention, the above naive
definition becomes correct: equivalently, we can write the fourth clause as
However, there are problems with turning this definition into a Prolog-style
declarative program. For example, the choice of ![]() is very open-ended,
and to choose fresh variables
is very open-ended,
and to choose fresh variables ![]() efficiently it is necessary to maintain
a ``store'' of unused variable names. This store is passed as an extra
argument and return value of
efficiently it is necessary to maintain
a ``store'' of unused variable names. This store is passed as an extra
argument and return value of ![]() . Also, this definition causes multiple
passes to be made over the term because of the renaming. To reduce this to
a single pass, we would have to add an additional argument mapping renamed
variables to their renamings.
. Also, this definition causes multiple
passes to be made over the term because of the renaming. To reduce this to
a single pass, we would have to add an additional argument mapping renamed
variables to their renamings.
In ![]() Prolog, on the other hand, we are able to write a definition that
is essentially the same as the declarative definition, yet correct:
Prolog, on the other hand, we are able to write a definition that
is essentially the same as the declarative definition, yet correct:
func subst(exp,exp,id) = exp. subst(var(x),E,x) = E. subst(var(y),E,x) = var(y) :- y # x. subst(app(E1,E2),E,x) = app(subst(E1,E,x),subst(E2,E,x)). subst(lam(y\E1),E,x) = lam(y\subst(E1,E,x)) :- y # E, y # x.where we read