Presence-Only Geographical Priors for Fine-Grained Image Classification
Oisin Mac Aodha, Elijah Cole, Pietro Perona
ICCV 2019
[paper] [code] [video]
Abstract
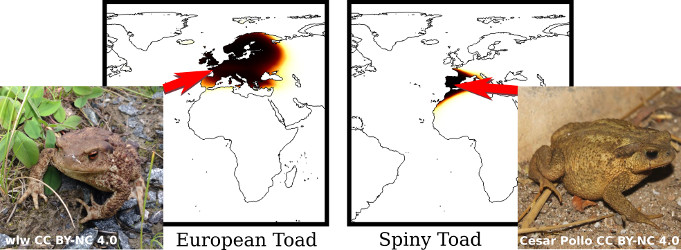 Appearance information alone is often not sufficient to accurately differentiate between fine-grained visual categories.
Human experts make use of additional cues such as where, and when, a given image was taken in order to inform their final decision.
This contextual information is readily available in many online image collections but has been underutilized by existing image classifiers that focus solely on making predictions based on image contents.
Appearance information alone is often not sufficient to accurately differentiate between fine-grained visual categories.
Human experts make use of additional cues such as where, and when, a given image was taken in order to inform their final decision.
This contextual information is readily available in many online image collections but has been underutilized by existing image classifiers that focus solely on making predictions based on image contents.
We propose an efficient spatio-temporal prior, that when conditioned on a geographical location and time, estimates the probability that a given object category occurs at that location. Our prior is trained from presence-only observation data and jointly models categories, their spatio-temporal distributions, and photographer biases. Experiments performed on multiple challenging image classification datasets show that combining our prior with the predictions from image classifiers results in a large improvement in final classification performance.
Overview
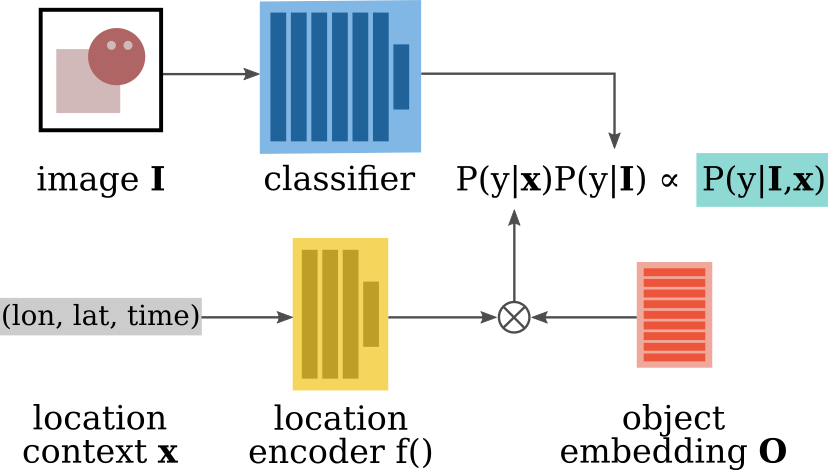 Our goal is to estimate if an object category y is present in an input image I.
At training time we make use of the fact that many image collections contain additional metadata such as where and when the image was taken, along with who captured it.
This additional data can be commonly found in citizen science datasets such as iNaturalist and eBird.
Our goal is to estimate if an object category y is present in an input image I.
At training time we make use of the fact that many image collections contain additional metadata such as where and when the image was taken, along with who captured it.
This additional data can be commonly found in citizen science datasets such as iNaturalist and eBird.We propose a spatio-temporal prior that models locations, objects, and people in a shared embedding space. The challenge here is that we have observations of where objects tend to occur i.e. where the images in our training set have been captured. However, we have no explicit information regarding where objects are not found. In species distribution modeling this is commonly referred to as presence-only data.
Given an image at test time, along with where and when it was taken (i.e. the location context x), we can query our prior to evaluate how likely it is for a given object category to be present at that location. We can combine this prediction with the output of an image classifier to better predict the object category that is present in the input image.
Results
We perform experiments on several fine-grained visual classification datasets and show a significant improvement in classification accuracy by combining the predictions of our model with the outputs of a deep image classifier.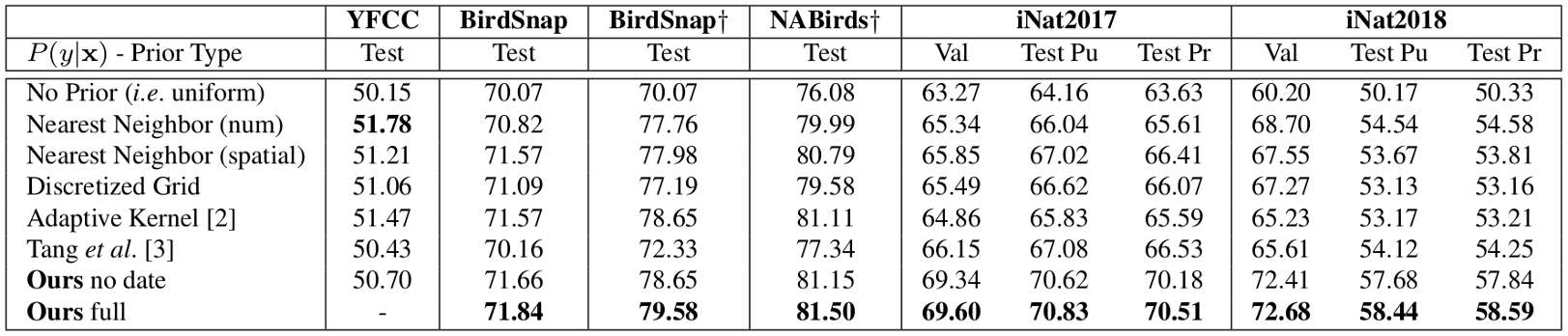
In addition to improving downstream classification performance we observe that our shared embedding space captures semantically meaningful relationships such as that 1) nearby locations are likely to harbor similar objects and 2) objects that are close in the embedding space have an affinity for similar spatio-temporal locations. The following images show embeddings on the iNaturalist 2018 dataset [1].
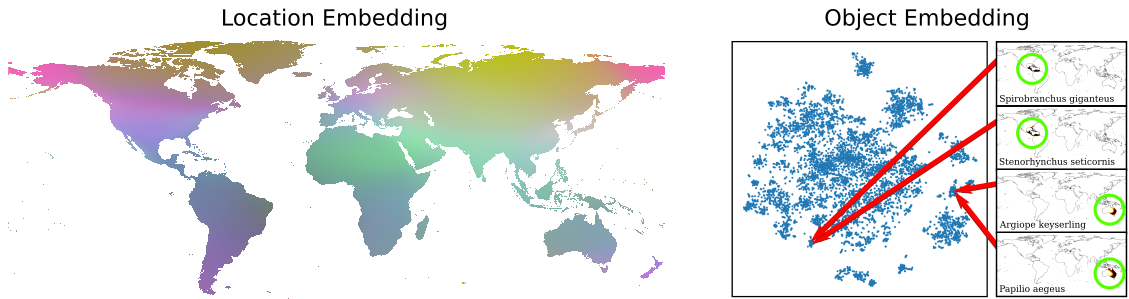
Our model also captures individual photographer affinity for specific object categories.
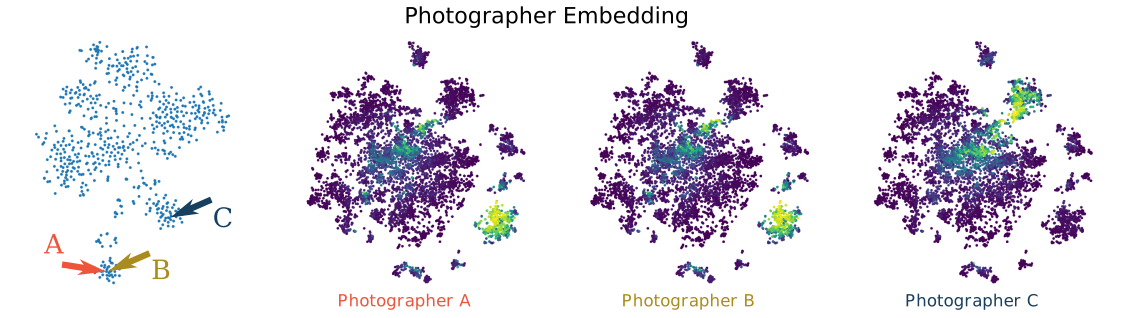
Our model also represents time-varying properties such as migratory behaviors.
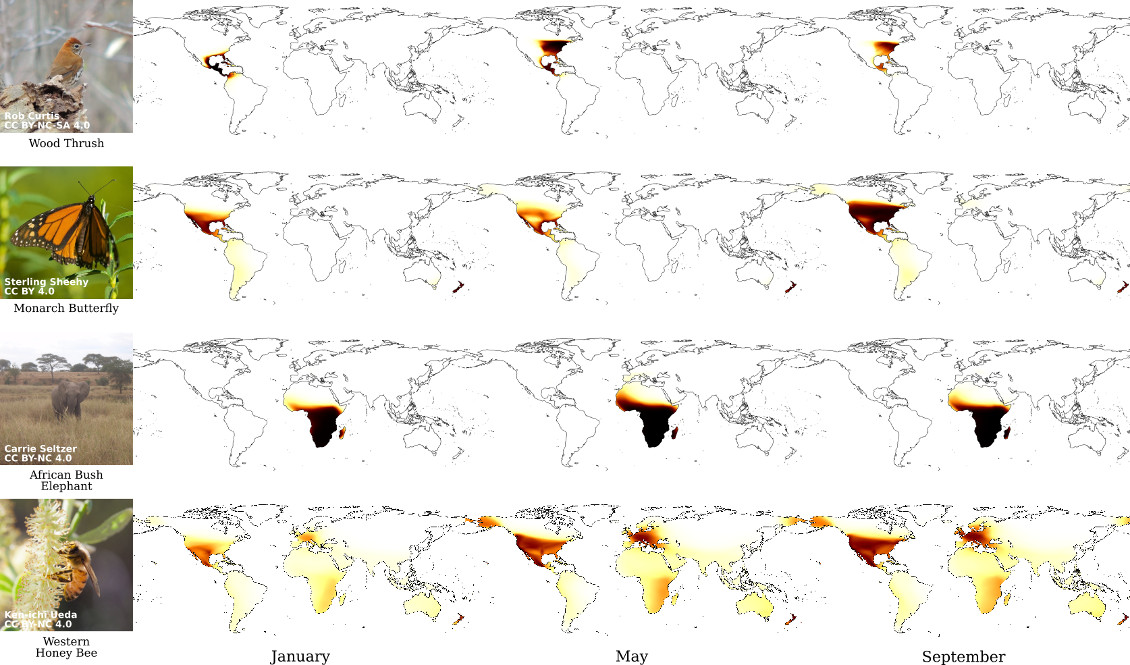
For additional results please consult our paper.
Demo
There is code here that allows you to run your own interactive demo locally. For location on the globe we evaluate the probablity that a given species appears there using our spatio-temporal prior.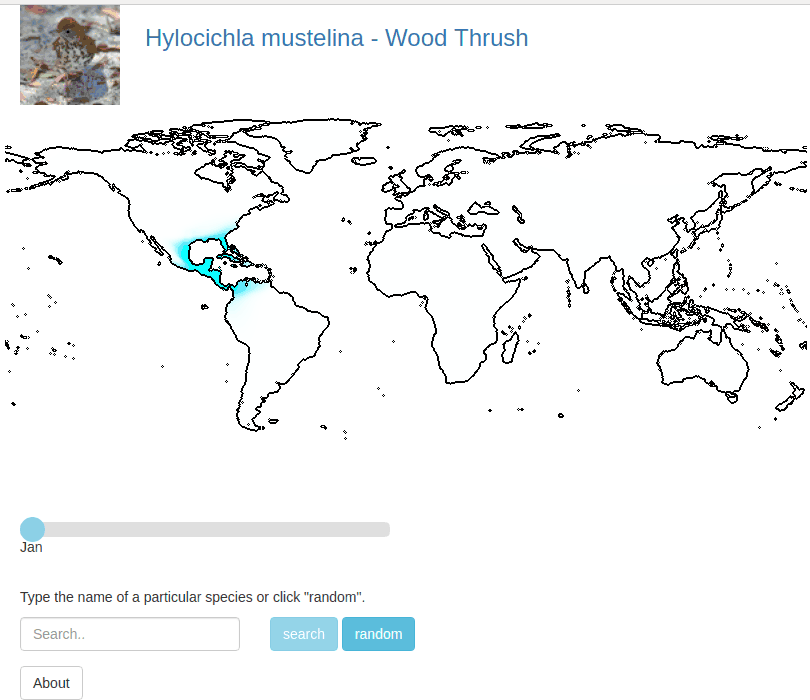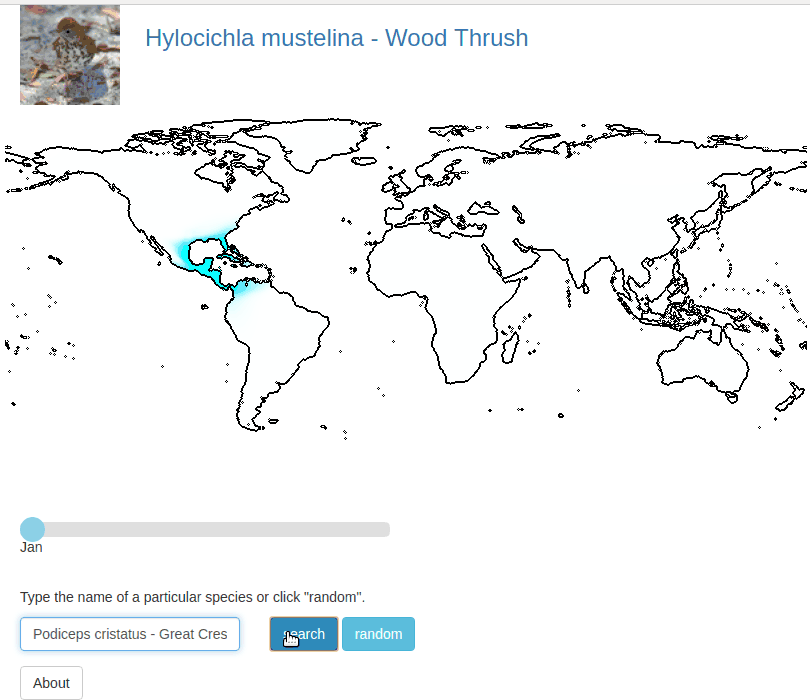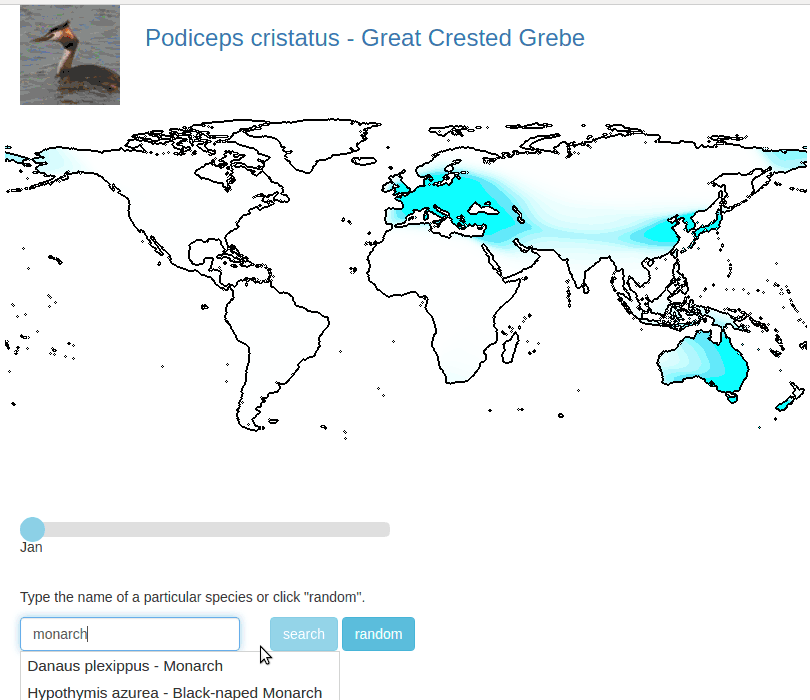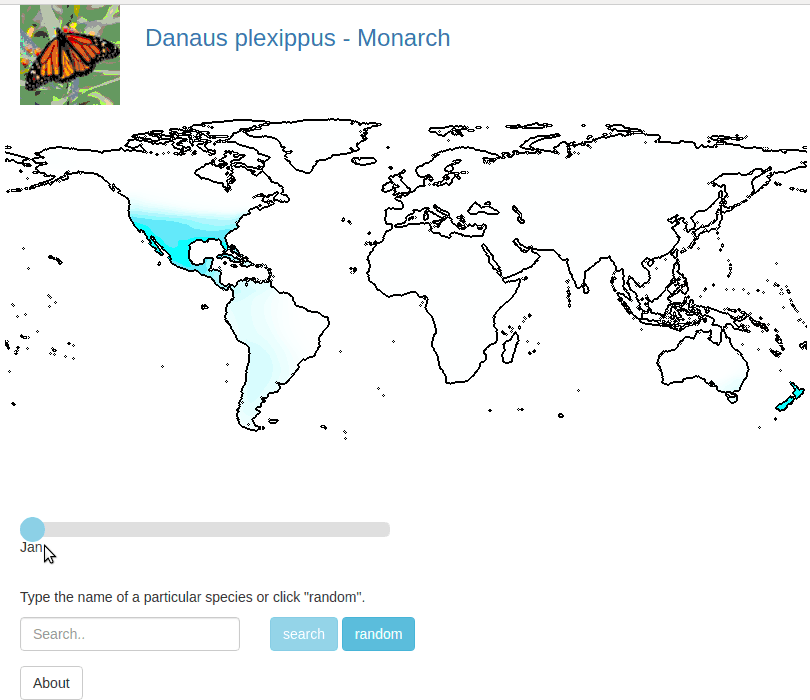
Code and Data
You can find the location metadata, CNN predictions, and CNN features for each of the datasets used in the paper here. This zip file is 22.3GB and unzips to 24.9GB. If you runmd5sum geo_prior_data.zip you should get 08b0db89332e551b9338d88b8c86782f.
It make take some time to unzip the file.
The full source code to train models and to recreate all the results in the paper is available here.