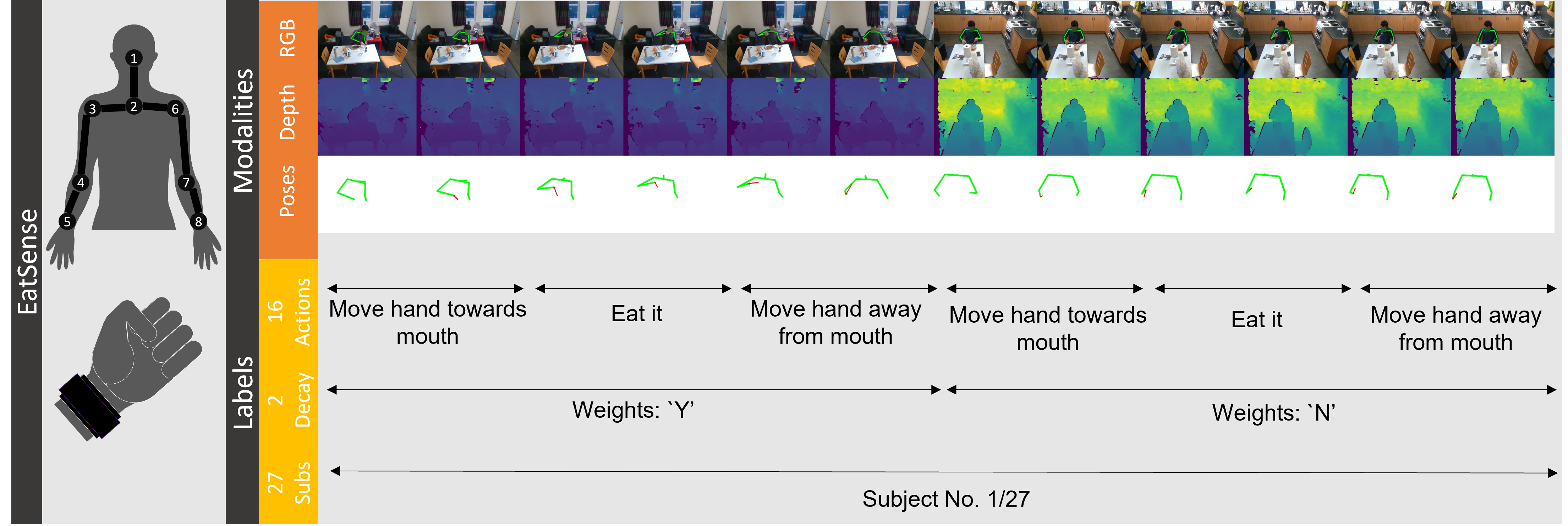
EatSense
Human Centric, Action Recognition and Localization Dataset for Understanding Eating Behaviors and Quality of Motion Assessment.
Introduction
This webpage introduces a new dataset EatSense that targets both 1) the computer vision community with challenging fine-grained atomic actions for recognition, and hugely varying length of actions making it nearly impossible for current temporal action localization frameworks to detect the atomic actions, and 2) the health-care community with the aim to detect changes in motion with low-level features. The dataset consists of 135 RGBD videos, averaging 11 minutes each, captured at 15 FPS. Each frame is labeled with the main atomic action primitive. A single person is in each video, eating a variety of foods, with a variety of styles.
In order to preserve privacy, all original faces in the videos have been replaced by a deep-fake variation on the face created by the algorithm given in paper 'DeepPrivacy'. Each frame has an independent new face. As a consequence, there is flickering on the faces. The original 2D joint positions are estimated on the original videos using the algorithm presented in paper 'HigherHRNet'. The 'True Faces' 3D joint positions are estimated by back-projecting the original 2D joint positions onto the depth image associated with each frame. The 'Fake Faces' 3D joint positions are estimated by back-projecting the re-estimated 2D joint positions onto the depth image associated with each frame.
Each video was captured with the volunteer either wearing 0kg (no weight), 1 kg, 1.8kg or 2.5kg weight on each wrist.
The data associated with each RGBD frame are the action primitive and the 2D and 3D upper positions of 8 upper-body joints. More details are below.
Properties & Statistics
- on average 114.1 action instances in each of the 135 untrimmed videos
- atomic actions such as move hand away from mouth that last for 0.625 seconds (on average - 9.3 frames @ 15 fps)
- four levels of abstraction in annotations with dense frame-wise labels
- it can be effectively used for applications where low-level information such as individual joints is required
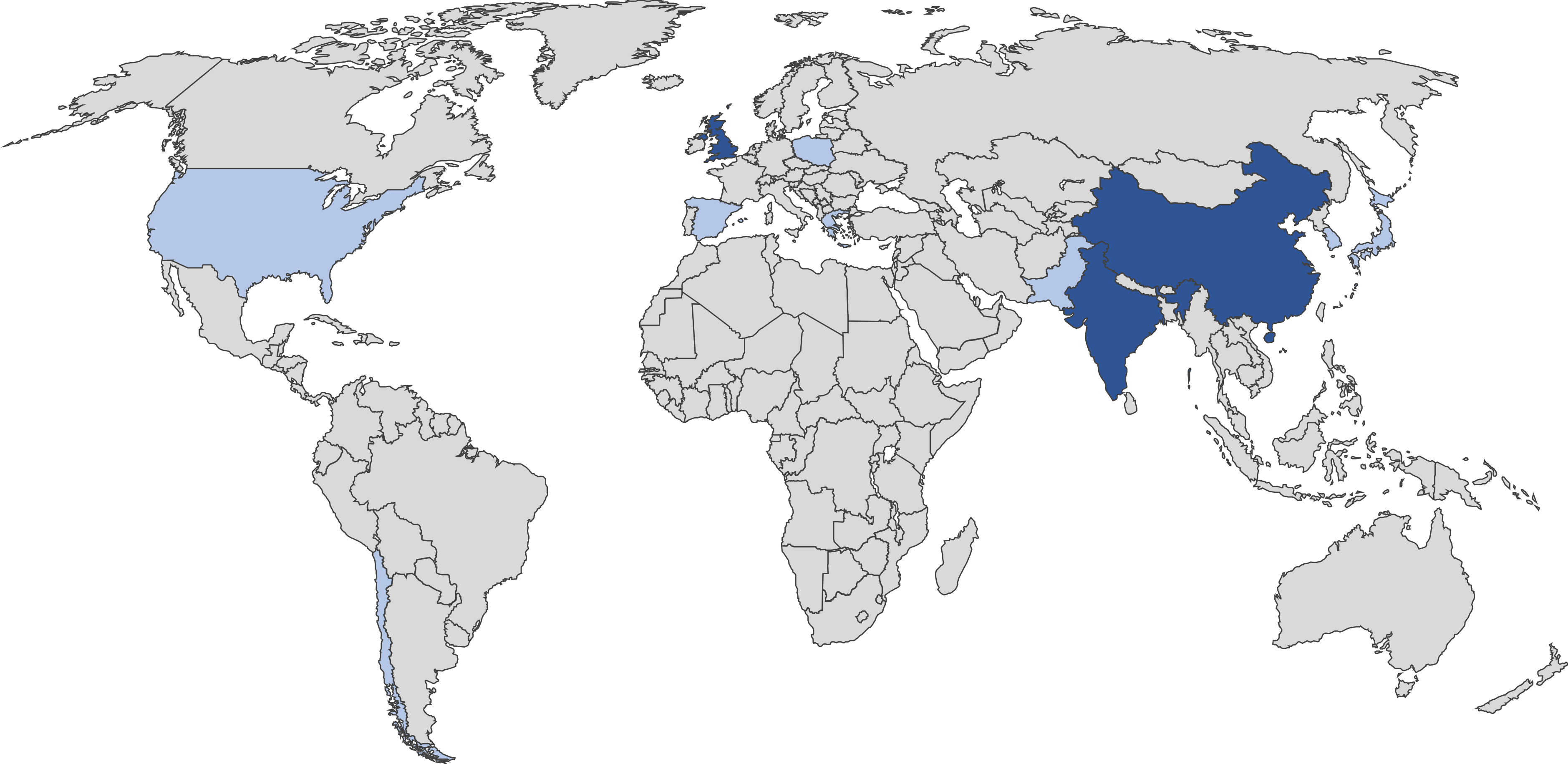
- 27 subjects of 12 different nationalities (shown in the map) to ensure diversity in eating styles, tools and foods
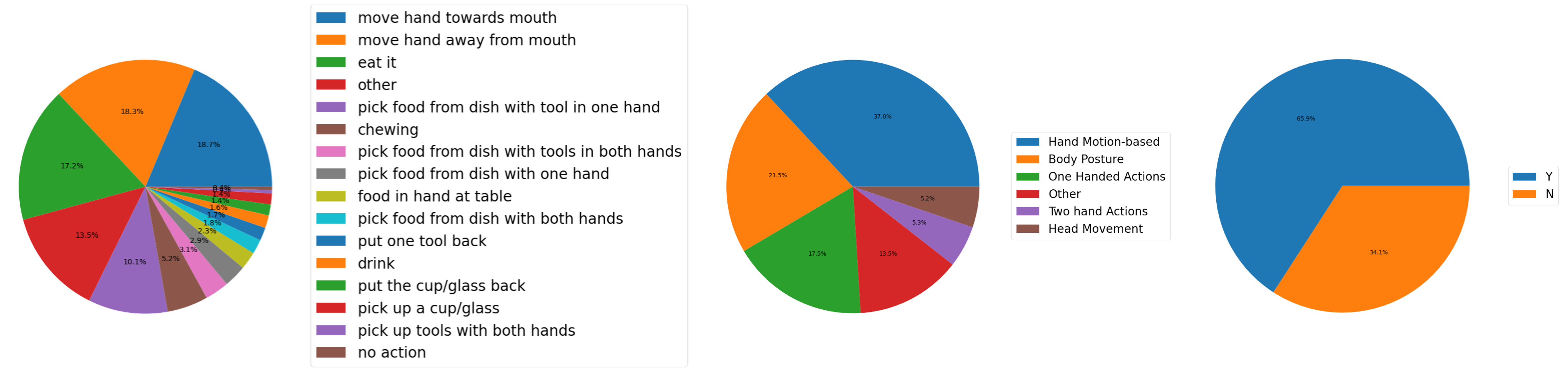
Caption: Distribution (in percentages) of various labels according to their occurrence in the dataset. Left) distribution of individual 16 sub-actions. Middle) distribution of actions based on abstraction-level 1 for the labels. Right) occurrence percentage of videos with weights `Y' and `N'.
| Action | Avg. Time per Instance | Total Number of Instances |
|---|---|---|
| chewing | 795 | 6.165 |
| drink | 247 | 2.723 |
| eat it | 2630 | 0.717 |
| food in hand at table | 344 | 3.868 |
| move hand away from mouth | 2792 | 0.625 |
| move hand towards mouth | 2851 | 0.844 |
| no action | 64 | 9.007 |
| other | 2057 | 7.043 |
| pick food from dish with both hands | 282 | 5.342 |
| pick food from dish with one hand | 440 | 3.741 |
| pick food from dish with tool in one hand | 1548 | 3.943 |
| pick food from dish with tools in both hands | 467 | 6.449 |
| pick up a cup/glass | 213 | 1.218 |
| pick up tools with both hands | 65 | 1.880 |
| put one tool back | 253 | 1.067 |
| put the cup/glass back | 214 | 1.618 |
Sample Data
These are the sample files (links in the 'downloadables' column) of how the data for each individual subject looks like. Please note that the sample poses are the True poses of the subjects.
| Video | Pid | Age-Grp | Difficulty | Gender | Food | No-of-tools | Tool | Downloadables |
|---|---|---|---|---|---|---|---|---|
| 20210804_145925 | 0 | 60+ | 1 | M | Wafers | 0 | No tool | [video] [2Dposes] [3Dposes] [depth] |
| 20210620_150313 | 1 | 30- | 0 | M | Roti | 0 | No tool | [video] [2Dposes] [3Dposes] [depth] |
| 20211029_144948 | 2 | 30- | 0 | F | Rice | 1 | Spoon | [video] [2Dposes] [3Dposes] [depth] |
| 20210923_163801 | 3 | 30- | 1 | F | Soup | 1 | Spoon | [video] [2Dposes] [3Dposes] [depth] |
| 20210923_161107 | 4 | 30- | 1 | M | Noodles | 1 | Fork | [video] [2Dposes] [3Dposes] [depth] |
Download Complete Dataset
To download complete zip files containing RGB/Depth/poses.
File Structure and Usage Instructions
This section explains the naming conventions and file structure of the downloadable files. Please refer to MetaData Summary for a table summarizing the gender/tools/foods/age group/difficulty information for all videos.
Sample Data
To download a small subset of videos and poses to see how the data looks like please refer to Sample Data section above. Sample downloadable data has four files linked to it.
- RGB-Videos ({Video}_deepfaked.mp4)
- Depth-Videos ({Video}_all_depth.mp4)
- 2D poses in pixels ({Video}_True2D.csv)
- 3D poses ({Video}_True3D.csv)
Full data download
We provide direct download links for a complete dataset download (courtesy University of Edinburgh DataShare). Please refer to section Download Complete Dataset above. Full downloadable data contains four zip files. The nested list show the naming conventions of the files in each of the zip file.
- RGB-Videos (File: deepfaked.zip)
- {Video}_anonymized.mp4
- ...
- Depth-Videos (File: all_depth.zip)
- {Video}_depth.mp4
- ...
- 2D and 3D poses with True Faces (File: True2D3D.zip)
- True2D/{Video}.mp4_preds_HigherHRNet.csv
- True3D/{Video}.csv
- ...
- 2D and 3D poses with Fake Faces (File: Faked_2D3D.zip)
- Faked2D/{Video}_preds_HigherHRNet.csv
- Faked3D/{Video}.csv
- ...
- Test Set (File: testset.zip)
- Folders: deepfaked, depthmaps, Faked2D, Faked3D, True2D, True3D
A readme.txt file explaining the example file structure of individual CSV files is available on this link.
Note: The {Video} refers to the name of video file. For example in row 1 of the table with video name as '20210804_145925', the files will be named (1) 20210804_145925_anonymized.mp4 (2) 20210804_145925_depth.mp4 (3) 20210804_145925.mp4_preds_HigherHRNet.csv (4) 20210804_145925.csv.
Related Publications
All publications using data from the "EatSense" database should cite the following paper:
- [1] M. A. Raza, L. Chen, L. Nanbo, R. B. Fisher; EatSense: Human Centric, Action Recognition and Localization Dataset for Understanding Eating Behaviors and Quality of Motion Assessment, Image and Vision Computing, 2023.
Interesting Publications using EatSense
- [2] Raza, Muhammad Ahmed, and Robert B. Fisher. "Vision-based approach to assess performance levels while eating." Machine Vision and Applications 34.6 (2023): 124.
Acknowledgement
Firstly, we would like to thank the dataset developers Muhammad Ahmed Raza, Longfei Chen and Robert Fisher. Secondly, thanks to Higher Education Commission (HEC), Pakistan for funding the PhD thesis and Advanced Care Research Centre (ACRC) for their valuable connections and resources.
Lastly, a shout out to the all the anonymous volunteers who participated in the collection of the dataset (and got a free lunch).
Terms and Conditions of Use
Following are the T & Cs:
- The dataset can be used for academic purposes only.
- For the privacy of subjects, their names are replaced with a subject number, by which each of these are referred to in the dataset. Additionally, images of the subjects in the dataset are only allowed for demonstation in academic publications.
- Any use of the dataset in a publication must cite: [Reference] M. A. Raza, L. Chen, L. Nanbo, R. B. Fisher; EatSense: Human Centric, Action Recognition and Localization Dataset for Understanding Eating Behaviors and Quality of Motion Assessment, Image and Vision Computing, 2023.
