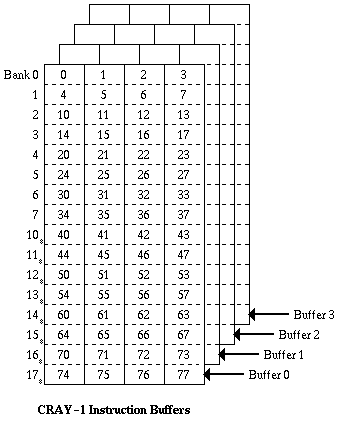
Figure 1 Cray-1 Instruction Buffers
The overall structure and instruction set of the CRAY-1 are largely derived from the CDC 6600 and 7600, with instructions being executed by a set of parallel functional units. The processor obtains all its instructions directly from a set of instruction buffers, however, and does not send a stream of instruction requests to the main store. These buffers are organised as shown in Figure 1. Each of the four buffers holds 64 consecutive 16-bit instruction parcels, and if an instruction request cannot be satisfied from within these buffers, a full 64-parcel block of instructions is transferred from main store into one of them.
Figure 1 Cray-1 Instruction Buffers
The CRAY-1 uses a 22-bit instruction address and the first instruction parcel in a buffer always has an address starting on a 64-parcel address boundary. Any one buffer is therefore defined by the 16 most significant bits of a parcel address, and for each buffer there is a 16-bit starting address register containing this value. At each clock cycle the high order bits of the program address counter are compared with the contents of these registers, and if a match occurs the required instruction parcel is selected from within the appropriate buffer either immediately, if the buffer concerned is the same as the one which supplied the previous parcel, or after a two clock period delay if a change of buffers is involved.
If no match occurs, instructions must be loaded into one of the instruction buffers before execution can continue. A two-bit counter is used to determine which buffer is to be loaded; this counter is incremented by one whenever a load operation occurs, thus implementing a cyclic replacement algorithm. The 64-bit main store in the CRAY-1 is an 8-way or 16-way interleaved bipolar semiconductor store having a 50 ns cycle time. During a block transfer all other store requests are inhibited, and sequential accesses can be made at a rate of one per 12.5 ns clock period. In the case of transfers to an instruction buffer, four storage banks can be accessed in parallel, giving access to 16 instruction parcels in one cycle and allowing all 16 banks in a 16-bank configuration to be accessed in four clock periods. Since the cycle time is also equal to four clock periods, the first four banks are then ready to accept a further request, and a complete block transfer to an instruction buffer occupies four cycles of each bank. The total time required to access the first group of instruction parcels is nevertheless quite long, and a 14 clock period delay is incurred whenever a buffer has to be loaded. This delay is constant regardless of the position of the first parcel required from the buffer, since a technique is employed similar to that in the IBM System/360 Model 85 cache, whereby the first group of 16 parcels delivered to the buffers is always the one required immediately by the processor. Subsequent groups arrive at a rate of 16 parcels per clock period and fill the buffer circularly.
When a branch is taken the new value in the program address counter is compared with the contents of the buffer starting address registers in exactly the same way as it is following the execution of each instruction in normal sequence. If a match occurs the required instruction is selected from the appropriate buffer, and if not a block transfer is initiated. Separate subroutines, or even non-contiguous segments of code within a loop, may be held concurrently in separate buffers. The buffer contents are only invalidated, by having their starting addresses set to all ones, when an Exchange Jump occurs.