Figure 1 Cache systems
The Model 85 cache is (or was) an example of a fully associative cache. In a subsequent IBM machine, the System/370 Model 165, a set associative cache was used. Set associative caches perform better in a multiprogramming environment and have better hardware cost-performance characteristics.
Most modern systems used direct mapped caches which avoid the need for associative hardware.
Figure 1 Cache systems
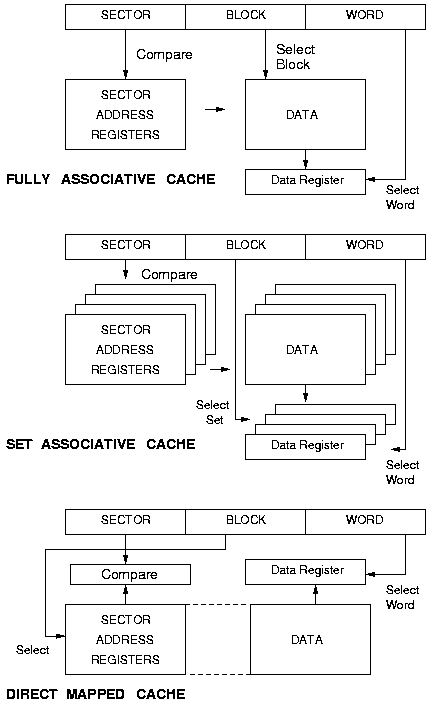
An example of each type is shown in Figure 1. In each case the address is made up of three separate fields, the sector address, the block address and the word address. In each case the word address field is used to select the word within a block of data read out from the data memory. In a fully associative cache the sector address field is compared with all the entries in the set of Sector Address Registers and the block address field selects the block of data to be read out from the corresponding sector in the data memory. In a set associative cache there are multiple sets of Sector Address Registers, with the sector address field being presented to all of them, while the block address field selects the required data register. In a direct mapped cache the block address field is used to select a Sector Address Register, the contents of which are compared with the sector address field of the address being presented to the cache. In each case data can only be read out if a match is found with the sector address field presented to the cache, otherwise the cache is updated from the main memory.
Each sector within the cache is made up of 16 blocks of 64 bytes and each block is marked with a validity bit. Whenever a cache sector is re-assigned to a different main storage sector, all its validity bits are re-set, and the block containing the required store word in the new sector is accessed from main storage. The validity bit for this block is then set and the sector address register updated. Further blocks are accessed and their validity bits set as required.
The sector address registers constitute an associative store. Whenever an address is generated which requires an operand to be fetched from store, the sector bits within the address are presented for association. If a match occurs a 4-bit tag is produced indicating the cache sector address, and this is used in conjunction with the block bits to select the appropriate validity bit for examination. If a match occurs in the sector field, and the validity bit is set, the appropriate 16-byte word is read out in the next machine cycle and returned to the processor. Throughput is maintained at one access per cycle by overlapping association and reading for successive instructions.
If a match occurs in the sector field, but the validity bit is not set, the required block is read from main storage. Reading one 64-byte block involves one access to each of the four interleaved storage modules making up the main store, since each is 16 bytes wide. The delay experienced by the processor as a result of these main storage accesses is minimised by always accessing the required 16-byte word first in the cycle of four, and by sending this word directly to the processor at the same time as loading it into the cache.
If a match does not occur, then a cache sector must be re-assigned to the main storage sector containing the failing address. A mechanism is therefore required to select a cache sector for re-assignment. The problem is similar to that involved in page rejection algorithms, except that in order to maintain performance, the algorithm must be implemented in hardware. The Model 85 cache implements a least recently used algorithm by maintaining an activity list with an entry for each cache sector. Whenever a sector is referenced it is moved to the top of the list by having its entry in the activity list set to the maximum value, while all intervening entries are decremented by one. The sector with the lowest activity list value is the one chosen for re-assignment.
Re-assignment does not involve copying back to main storage values in the cache updated by the action of write-to-store orders. Whenever such an order is executed, both the value in the cache and that in main storage are updated, a technique known as store-through. Furthermore, if the word being updated is not held in the cache, the cache is not affected at all, since no sector re-assignment or block fetching takes place under these circumstances. While the store-through technique has the advantage of not requiring any copying back of cache values at a sector re-assignment, it also has the disadvantage of limiting the execution rate of a sequence of write orders to that imposed by the main storage cycle time. The store-through principle was rejected by the designers of MU5 (see under The MU5 Name Store) and abandoned by IBM in the design of the 3090.
Simulation studies of the Model 85 cache showed that the average performance of the cache/main storage hierarchy over 19 different programs corresponded to 81 per cent of a hypothetical system in which all accesses found their data in the cache. The average probability of an access finding its data in the cache for these programs (the hit rate) was 96.8 per cent. There do not appear to have been any subsequent measurements on real Model 85 systems to confirm or deny these predictions, but certainly a different arrangement was introduced in the System/360 Model 195 [2] and carried through into the System/370 Models 165 and 168. The average hit rate in the Model 195 cache was shown to be 99.6 per cent over a range of 17 job segments covering a wide variety of processing activities.
Each column in the cache store contains 4 blocks and each column in main storage 512 blocks (in a 1 Mbyte version of the model). The block address registers constitute an address array made up of 64 columns, each containing four 13-bit entries. Thus of the 19 bits of an incoming address used to access a block, the 6 low order bits are used to select a column, and the 13 high order bits are presented for association in the selected column of the address array. This arrangement is referred to as set associative mapping; two adjacent blocks from main storage contained within the cache will be referenced by identical entries in adjacent columns of the address array.
A validity bit associated with each block indicates whether or not an address giving a match on association refers to valid data; if not the required data is accessed from main storage. Apart from the factor of two difference in store widths, data paths and block sizes, the arrangements for transferring data between the cache and main storage are identical in the 370 Model 165 to those in the 360 Model 85. The cache replacement algorithm is also the same, except that in the 370 Model 165 a replacement array is required containing a separate activity list for each of the 64 columns.
Access to central storage from the processors in a 3090 system is provided through a system control element. Using the store-in-cache principle, any lines in a cache that have been stored into become, in effect, part of the central storage system. Thus the latest copy of a variable may be in the processor's local cache, in central storage, or in the cache of another processor. The design of the system control element must therefore take this into account. Further discussion of the problems of cache consistency in multiprocessor systems can be found in Computer Architecture II.