The execution time 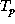 for program p on a decoupled architecture
can be modelled by equation 1,
for program p on a decoupled architecture
can be modelled by equation 1,
where 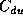 is the number of execution cycles on the DU,
n is the number of LODs executed, d is the nominal penalty induced by
each LOD, and
is the number of execution cycles on the DU,
n is the number of LODs executed, d is the nominal penalty induced by
each LOD, and 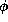 is the clock period of the machine.
is the clock period of the machine.
In this paper we assume a nominal value of d = 150 cycles. This is a value that has been verified by register-transfer level simulation of the ACRI-1 architecture. A value of 150 cycles is typical of the synchronization cost for a machine with a 4 to 6ns cycle time which obtains all operands from a relatively distant DRAM memory system.
Without actually executing a program is it hard to predict
values for 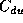 , but it is possible to define a lower bound
, but it is possible to define a lower bound 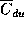 as
as 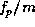 , where
, where 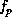 is the number of floating point operations
executed by program p, and m is the number of floating point pipelines.
This must be an absolute minimum execution time for any processor with m
floating point pipelines. It permits us to put a lower bound on execution time
as follows:
is the number of floating point operations
executed by program p, and m is the number of floating point pipelines.
This must be an absolute minimum execution time for any processor with m
floating point pipelines. It permits us to put a lower bound on execution time
as follows:
Similarly, we can define a lower bound on decoupling efficiency, i.e. the fraction of time that the DU is guaranteed to be busy compared to the DU time spent waiting for memory operands.
In the ACRI-1 architecture m=2, and only pipeline startup and shutdown delays,
and occasional register spillage costs,
on the DU will introduce any discrepancy between 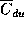 and
and
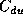 . In a DU with hardware support for modulo-scheduled
software pipelining, we would expect startup and shutdown costs to be relatively
low. Detailed measurements of startup and shutdown costs for loop schedules
are beyond the scope of this paper.
. In a DU with hardware support for modulo-scheduled
software pipelining, we would expect startup and shutdown costs to be relatively
low. Detailed measurements of startup and shutdown costs for loop schedules
are beyond the scope of this paper.


