The architecture model we assume has decoupled memory access and decoupled control flow, similar to the ACRI-1 architecture described in [6] and [16]. In a decoupled access/execute (DAE) architecture, the processes of accessing memory and performing computations on values fetched from memory can be thought of as micro-threads implemented on separate asynchronous units. In ACRI-1 terminology, the Address Unit (AU) computes addresses and issues memory requests. The Data Unit (DU) receives data from memory, computes new values, and sends new data back to memory. The AU and DU execute a program containing the instructions that are specific to each unit. The only constraint on the AU and DU programs is that the order in which operand addresses are issued by the AU must match precisely the order in which operands are used by the DU.
The AU tags each memory fetch request with a location in a load queue within the DU where the incoming data will be buffered. This tag permits the physical memory system to process requests in any order; the DU load queue re-orders them as they arrive, ensuring that the AU-DU ordering constraint is always satisfied. In the ACRI-1 architecture there are two independent load paths to memory, and two independent load queues in the DU.
The AU is optimized to implement the most common operations on
induction variables. Thus, it has a simple integer instruction set and instruction
modes which permit operations of the form 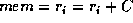 . In a single
instruction an induction variable
. In a single
instruction an induction variable 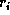 can be incremented by some constant
value C (or the contents of a register) and the result can be stored back to
the induction variable as well as being sent to memory as a load or store
address.
can be incremented by some constant
value C (or the contents of a register) and the result can be stored back to
the induction variable as well as being sent to memory as a load or store
address.
Control transfers are partitioned into two groups; those which implement leaf-level loop control (leaf-level loops are those without internal cycles or subroutine calls), and those which implement all other control transfers. The AU and DU have the capability to implement simple looping constructs, and this permits the compiler to target leaf-level loop control directly on to the AU and DU. All remaining control transfers are executed by a third unit, the Control Unit (CU). Effectively the CU controls the sequencing of the program through its flow graph, dispatching leaf-level loops intact to the AU and the DU.
Control decoupled architectures share some similarities with vector processors, in which a scalar unit dispatches vector instructions to a vector load pipeline and vector arithmetic pipelines, however, the differences are significant. Firstly, the body of the leaf loop on the AU and the DU is derived directly from the source code without any need to vectorize. Secondly, the compiler's partitioning of code between units is driven by data dependencies and not by what instructions can or cannot be vectorized. Thirdly, there is a high degree of asynchrony between the three units, and this permits the CU, for example, to enqueue loop dispatch blocks for the AU and DU well in advance of their being executed. The CU is, in many ways, a natural extension of the virtual pipeline connecting the AU to the DU through memory.
Memory operations can be initiated by the CU, by the AU on behalf of the DU, and
by the AU on behalf of itself. As the three units execute asynchronously, there
exists the possibility of thru-memory data dependencies. The compiler must detect
all such dependencies and synchronize appropriate subsets of units at certain
points in the program. In practice the dependencies which cause such synchronization
events are often widely separated in terms of source code position, so a global
dataflow approach is taken. One such dependence, from the OLDA subroutine in
program TRFD from the Perfect Club is
illustrated graphically.
When compiling for a vector processor there are occasions when the compiler must determine whether to compile scalar code or vector code. Often both cases will be compiled and the most efficient version chosen at run time. In a decoupled architecture, the compiler must choose the unit to execute each instruction, with the principal goal being to decouple memory accesses and control transfers. However, provided that each store instruction is executed on a single unique unit, there is no reason why two or more units may not execute the same instruction. This replication of instructions typically does not increase execution time, and will often reduce the frequency with which inter-unit data traffic causes performance penalties.
In the target architecture there is no data cache. The architecture obtains all memory operands directly from main memory. The omission of a data cache is made possible by the latency hiding effect of access decoupling, and this omission helps to reduce costs. However, caches can sometimes improve the performance of decoupled architectures, particularly when applications do not decouple well. Further information on the behaviour of caches in decoupled systems can be found in [13].