In an access and control decoupled architecture, the CU ``runs ahead'' of the AU and DU, and the AU ``runs ahead'' of the DU. It is conceivable for the CU and the DU to be separated in space and time by many thousands of program statements. When the system is fully decoupled, the AU will typically be ahead of the DU by a time equal to the largest memory latency experienced by any load operation since the last recoupling of the AU and DU. The CU, AU and DU therefore constitute an elastic pipeline, with the dispatch queue linking the CU to the AU and DU, and the memory system linking the AU to the DU.
There are a number of specific events that will cause an interruption in the pipeline flow. These occur whenever information travels against the normal direction of flow for the decoupling pipeline. At such points in the program some degree of decoupling is lost, and we therefore refer to these as Loss of Decoupling (LOD) points. In a decoupled architecture, LOD events are the principal cause of execution time penalties. When the system is fully decoupled, the entire physical address space appears to be accessible within one cycle; at an LOD point however a large penalty is paid. Optimizing a decoupled architecture is largely a process of minimizing the frequency of LOD events.
The calling standard of the ACRI-1, and thus the standard adopted by our experimental compiler, defines a common shared stack for the CU, the AU and the DU. This has implications for data synchronization across function call and return boundaries. If the CU and DU are decoupled when a function is called, the CU will reach the stack frame manipulation code before the DU finishes using the current stack frame. To prevent stack frame corruption, the CU must wait for the DU to reach the call point before the stack frame is modified. Again, this constitutes an LOD. In table of baseline LOD frequencies, we term this a ``call LOD'' (or C-LOD). A similar situation may occur if the units are uncoupled at a function return point. Again, the CU is ready to relinquish a stack frame, but the DU may not yet have finished using some of the local variables allocated in that frame. The CU must therefore wait for the DU to reach the return point, and then perform the return sequence. This is a ``return LOD'' (or R-LOD).
Calls to external routines, such as I/O and timer calls, must also be synchronized. However, by appropriate engineering it is possible to avoid LODs across the call boundaries with intrinsic functions (information on the use and modification of parameters is more clearly specified, and intrinsics do not modify global variables). In this analysis, LODs due to calls to external routines do not lead to LODs.
To summarize, when a program is executing in a decoupled mode the perceived memory latency is zero; effectively the entire physical memory has an access time equivalent to the processor's register file, and latency is completely hidden. However, when an LOD occurs, the penalty is significant. Our modelled results assume a nominal penalty of 150 cycles, and this means that the frequency of LODs is of paramount importance when determining the expected application performance.
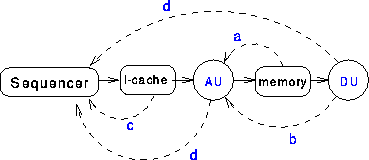
Figure 1: Events that may destroy decoupling
Figure 1 shows an execution pipeline for a typical decoupled architecture. The solid arrows show the normal direction of flow, and the broken arrows represent inter-unit dependencies that cause decoupling to break down. In the normal forward flow, the sequencer presents an instruction address to the instruction cache, which supplies the instruction to the AU. The AU executes this instruction, which generates an address, and initiates a memory read operation. The AU then proceeds to its next operation. When the read operation terminates, a datum is passed to the DU, which can execute an operation using that operand.
Although different architectures may have different ways of issuing instructions to the units we call AU and DU, the pipeline shown in figure 1 is representative of all schemes. We may regard the sequencer shown at the left of the diagram as the Instruction Splitter (as in the ZS-1), an instruction fetch unit for the Address Unit, or as a Control Unit, as described in [6]. The various forms of pipeline disruption, indicated by broken arrows in figure 1, are discussed below.