Invocation is Suggestion
Invocation is the result of the directed convergence of clues that suggest identities for explaining data. On the street, one occasionally sees a person with a familiar figure, face and style, but who on closer inspection turns out not to be the acquaintance. The clues suggest the friend, but direct examination contradicts the suggestion.
Invocation also supports the "seeing" of nonexistent objects, as in, e.g.,
Magritte's surrealist paintings, where configurations of features give
the impression of one object while actually being another.
Figure/ground reversals and ambiguous interpretations such as the vase and
faces illusion could occur when multiple invocations are possible, but
only a single interpretation is held at any instant, because of
mutual inhibition, as suggested by Arbib [9] and others.
Invocation is Mediated by Relationships
Invocation is computed through associations or relationships with other objects. The effect is one of suggestion, rather than confirmation. For example, a red spheroid might suggest an apple, even though it is a cherry. Another example is seen in the Picasso-like picture drawn in Figure 8.1. Though many structural relationships are violated, there are enough suggestions of shapes, correct subcomponents and rough relationships for invoking a human face.
While there are many types of relationship between visual concepts, two key
ones are mediated by class and component relationships as discussed below.
Other relationship types include context (robots are more often found in
factories than in trees) or temporal (a red traffic light is often seen after
a yellow traffic light).
Altogether, the work here integrates eight different evidence types:
subcomponent, supercomponent, subclass, superclass, description (i.e. generic
shape), property, general association and inhibiting (i.e. competing).
Associations Have Varying Importances
The importance of a particular feature in invoking a model is a function of the feature, model, context and viewing system.
Some objects share common features, such as planar faces in blocks world scenes. Other objects have distinct features, such as the shape of the Eiffel Tower, an ear or the characteristic blue light used by emergency vehicles. Hence, some features may dramatically reduce the set of potential models.
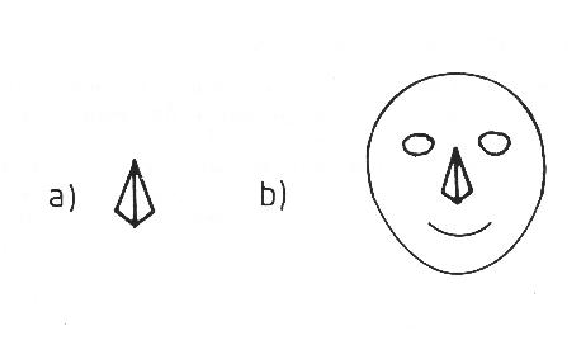
Context is also important, because the a priori likelihood of discovering an object influences the importance of a feature. Wheels (generic) when seen in a garage are more likely cues for automobiles than when seen in a bicycle shop. Part (a) of Figure 8.2 shows is a standard pyramid that is unlikely to invoke any models other than its literal interpretation. Yet, in Figure 8.2 part (b), the same pyramid invokes the "nose" model acceptably. Obviously, the context influences the likely models invoked for a structure. The viewing system is also a factor, because its perceptual goals influence the priorities of detecting an object. For example, industrial inspection systems often concentrate on a few distinctive features rather than on the objects as a whole.
Statistical analysis could determine the likelihood of a feature in a
given context, but is unhelpful in determining the importance of the feature.
Further, because contexts may change, it is difficult to estimate the object and
feature a priori distributions needed for statistical classification.
Finally, feature importance may change over time
as factors become more or less significant (e.g. contexts can change).
Hence, importance assessment seems more properly a learning than
an analysis problem.
Evidence Starts with Observed Properties
Property evidence is based on properties extracted from the input data. Here, the evidence will be common unary or binary properties. An example is surface shape evidence, which may have zero, one or two magnitudes and axes of curvature.
The properties are absolute measurements constrained by bounds (like ACRONYM [42]). Some properties must lie in a range, such as expected surface area. Others are merely required to be above or below a limit, as when requiring positive maximum principal curvature. Other property values may be excluded, such as zero principal curvature.
Evidence is acquired in "representative position" [51].
Features that remain invariant during data acquisition over all
observer positions are few (e.g. reflectance, principal curvatures).
As this research is concerned with surface shape properties, the potential
evidence is more limited and
includes angles between structures, axis orientations, relative feature
sizes and relative feature orientations.
Invocation features should be usually visible.
When they are not, invocation may fail, though there may be alternative
invocation features for the privileged viewing positions.
Evidence Comes from Component Relationships
The presence of an object's subcomponents suggests the presence of the object. If we see the legs, seat and back of a chair, the whole chair is likely although not guaranteed to be there, as we could be seeing an unassembled set of chair parts. Hence, verified or highly plausible subcomponents influence the plausibility of the object's presence. The reverse should also occur. If we are reasonably sure of the chair's presence (e.g. because we have found several subcomponents of the chair), then this should enhance the plausibility that nearby leg-like structures are chair legs. This information is useful when such structures are partially obscured, and their direct evidence is not as strong.
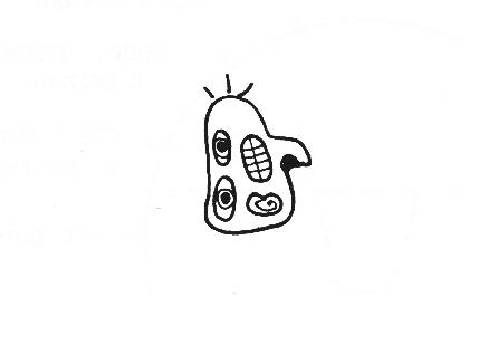
Figure 8.3 shows an abstract head. While the overall face is unrepresentative, the head model is invoked because of the grouping of correct subcomponents.
Configurations of subcomponents affect invocation in two ways: (1) only a subset of subcomponents is visible from any particular viewpoint, and (2) the spatial distribution of subcomponents can suggest models as well. The first case implicates using visibility groups when integrating evidence. For a chair, one often sees the top of the seat and the front of the back support, or the bottom of the seat and back of the back support, or the top of the seat and the back of the back support, but seldom any of the other twelve groupings of the four subcomponents. These groupings are directly related to the major visibility regions in the visual potential scheme suggested by Koenderink and van Doorn [103]. They showed how the sphere of all potential viewing positions of an object could be partitioned according to what components were visible in each partition and when various features became self-obscured. Minsky [116] suggested that distinguishable viewer-centered feature groupings should be organized into separate frames for recognition.
It is well known that the many small features of a normal object lead to a great many regions on the view potential sphere. To avoid this problem, two ideas were adopted here. First, rather than creating a new visibility region whenever an occlusion event occurs (i.e. when an edge is crossed), the regions are formed only according to changes in the visibility of large-scale features (i.e. SURFACEs and ASSEMBLYs). That is, a new group is formed whenever new subcomponents are seen, or when feature ordering relationships are different. Second, the visibility and feature ordering analysis only applies to the immediate subcomponents of the object, and disregards any visibility relationships between their own subcomponents. Thus, visibility complexity is reduced by reducing the number of features and the details of occlusion relationships considered, by exploiting the subcomponent hierarchy, and by ignoring less likely visibility groupings.
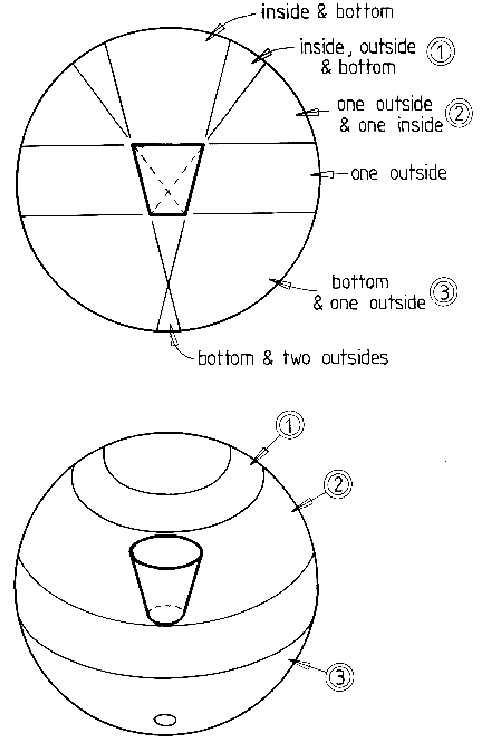
Figure 8.4 shows the sphere of viewpoints partitioned into the topologically distinct regions for a trash can. At a particular scale, there are three major regions: outside bottom plus adjacent outside surface, outside surface plus inside surface and outside, inside and inner bottom surfaces. There are other less significant regions, but these are ignored because of their minor size.
During invocation, these visibility groupings are used to collect subcomponent evidence, and the invocation of a group implies a rough object orientation. Here, invocation is the important result, which will lead to initial structure assignments for hypothesis construction (Chapter 9), from which orientation is estimated directly.
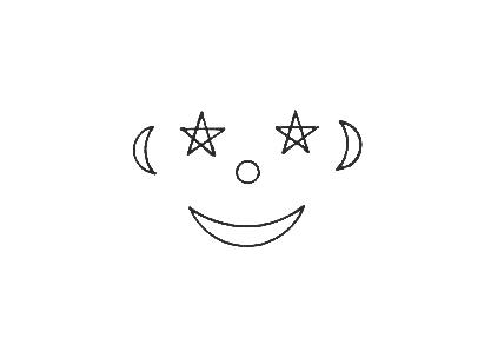
The second aspect of spatial configurations is how the placement of components, rather than their identity, suggests the model. Figure 8.5 shows the converse of Figure 8.3, where all subcomponents have the wrong identity but, by virtue of their position, suggest the face model.
Spatial configuration evidence is represented by binary evidence types
that constrain relationships like relative position, orientation or size.
The evidence for these relationships should probably be stronger if the
features involved in the relationship also have the correct types.
That is, the two eye-like features in Figure 8.5 help suggest a face,
but they would do so more strongly if they were individually more like
eyes.
Evidence Comes from Class Relationships
An object typically has several generalizations and specializations, and evidence for its invocation may come from any of these other hypotheses. For example, a generic chair could generalize to "furniture", or "seating structure", or specialize to "dentist chair" or "office typing chair". Because of the unpredictabilities of evidence, it is conceivable that any of the more generalized or specialized concepts may be invoked before the generic chair. For the more general, this may occur when occlusion leaves only the seating surface and back support prominent. Conversely, observation of a particular distinguishing feature may lead to invocation of the more specific model first. In either case, evidence for the categorically related structures gives support for the structure.
Class prototypes are useful when a set of objects share a common identity, such as "chair". General properties of an object class are more important for invocation (as compared to verification, which needs the details of shape).
There are some superficial relationships with the generic identification
scheme in ACRONYM [42], where identification proceeds by descent through
a specialization hierarchy with increasingly stringent constraints.
Here, the hierarchy and notion of refining constraints are similar,
but: (1) the goal is suggestion, not verification, so the property
constraints are not strict, and (2) the flow of control is not general
to specific: identification could locally proceed in either
direction in the hierarchy.
There is a Low-Level Descriptive Vocabulary
There is a vocabulary of low level, object independent and special intermediate shapes and configurations. The purpose of the descriptions is to introduce generic, sharable structures into the invocation process. Examples of the symbols include: "positive-cylindrical-surface" and "square-planar-polygon". However, this vocabulary does not usually refer to identifiable real objects, but instead to ideal generalizations of some particular aspects of the object. For the "positive-cylindrical-surface", it does not say anything about the identity of the patch, nor the extent or curvature, but concisely characterizes one aspect of the object.
The symbols structure the description of an object, thus simplifying any direct model-to-data comparisons and increase efficiency through shared features. A description hierarchy arises from using subdescriptions to define more complex ones. An example of this is in the chain of descriptions: "polygon" - "quadrilateral" - "trapezoid" - "parallelogram" - "rectangle" - "square", where each member of the chain introduces a new property constraint on the previous. The hierarchy helps reduce the model, network and matching complexity. Rather than specify all properties of every modeled object, the use of common descriptions can quickly express most properties and only object-specific property constraints need be added later.
This is important to invocation efficiency, because of the filtering effect on recognitions, whereby image data invoke low level visual concepts, which then invoke higher level concepts.
If object descriptions are sufficiently discriminating, a vision
system may be able to accomplish most of its interpretation through
only invocation with little or no model-directed investigation.
Invocation is Incremental
Evidence can come from a variety of sources and as more supporting evidence accumulates the desirability of invoking a model increases. The invocation process must continue even though some evidence is missing because of occlusion or erroneous descriptions. Complementary evidence should contribute to plausibility and conflicting evidence should detract from it. The process should degrade gracefully: less evidence should lower the desirability of invocation rather than prevent it totally.
These factors suggest that invocation is mediated by a continuous plausibility.
Invocation Occurs in Image Contexts
There must be contexts for grouping property evidence
and for associating subcomponents, so that related evidence is integrated
and unrelated evidence is excluded.
Individual Evidence Values Need to be Integrated
Evidence needs to be integrated several times: when individual properties are merged to provide a total property evidence value, when individual subcomponent evidence values are combined and when all eight evidence types are combined. This integration is complicated by the different implications of the evidence types and their relative importances. Moreover, the quantity of evidence associated with different evidence types implies evidence weighting is required.