

As shown in Fig. 2, a spatiotemporal event includes two kinds of information: the object of interest, and the movement of the object. The movement of the object can be further decomposed into two components: global and local motions. The global motion captures gross motion in terms of position change. The local motion characterizes deformation, orientation and gesture changes. In the case of sign language, the hand is the object of interest. The position change of the hand is a global movement and the change of the hand gesture and orientation is a local movement.
Figure 3:
The three-stage framework for spatiotemporal event recognition
In this paper, we propose a three-stage framework for spatiotemporal event recognition, as illustrated in Fig. 3. The first stage, sequence acquisition, acquires image sequences representing the event. This involves motion detection and motion-based visual attention. The start and end of motion identify the temporal attention window in which the event occurs. We map this temporal window to a standard temporal length (e.g., 5) to form what is called motion clip, while the speed information is available from the mapping performed in this stage. In a motion clip, only the temporal dimension is normalized. Here, we assume that a hand sign starts and ends with a static hand.
The second stage is visual attention and object segmentation. This stage directs the system to focus on the object of interest in the image. If we assume that the object of interest is moving in a stationary environment, it is not very difficult to roughly determine the position of a moving object in the image using motion information. However, it is not simple if the task is to extract the contour of the object from various backgrounds. In [17], we presented a prediction-and-verification segmentation scheme to locate hands from complex backgrounds. The scheme uses the information learned from past experience to predict the valid segmentation based on particular views. It is more efficient and effective than other stochastic approaches such as simulated annealing.
After Stage 2, the object of interest in each image of a sequence is segmented and mapped to a fovea image of a standard fixed size. Segmented fovea images at different times form a standard spatiotemporal fovea sequence, in which both temporal and spatial dimensions are normalized. The global motion information of the object of interest is placed in a global motion vector, which records the size and position information of the segmented object in the original image. This vector is necessary because once the object is segmented and mapped to a fovea sequence with a standard spatiotemporal size, the global motion information is lost.
Let a fovea image f with m rows and n columns be
an (mn)-dimensional vector.
For example, the set of image pixels
![]() can be
written as a vector
can be
written as a vector ![]() where
where
![]() and d=mn.
Note that although pixels in an image are lined up to form a 1-D
vector
and d=mn.
Note that although pixels in an image are lined up to form a 1-D
vector ![]() this way, the 2-D neighborhood information between
pixels will be
characterized by the scatter matrix of
this way, the 2-D neighborhood information between
pixels will be
characterized by the scatter matrix of ![]() to be discussed later.
Let p be the standard temporal length and
to be discussed later.
Let p be the standard temporal length and ![]() be the hand fovea image
corresponding to the frame i. Then we create a new vector
be the hand fovea image
corresponding to the frame i. Then we create a new vector ![]() , called
the fovea vector, which consists of
the hand fovea subimages and global
motion vector G,
, called
the fovea vector, which consists of
the hand fovea subimages and global
motion vector G,
The third stage, which is the focus of this paper, is to recognize the spatiotemporal event from the fovea vector.
An automatic hand gesture recognition system accepts an input fovea vector
![]() and outputs the recognition result
and outputs the recognition result ![]() which
indicates the class to which
which
indicates the class to which ![]() belongs.
Thus, a recognition system can be denoted
by a function f that maps each element in the space of
belongs.
Thus, a recognition system can be denoted
by a function f that maps each element in the space of ![]() to
an element in
the space of
to
an element in
the space of ![]() . Our objective of constructing a recognition system
is equivalent
to approximating function
. Our objective of constructing a recognition system
is equivalent
to approximating function ![]() by another function
by another function
![]() .
The error of a approximation can be indicated by certain measure of the error
.
The error of a approximation can be indicated by certain measure of the error
![]() . One such measure is the mean square error:
. One such measure is the mean square error:
![]()
where ![]() is the probability distribution function
is the probability distribution function ![]() in S. In other
words,
in S. In other
words, ![]() can defer a lot from f in parts where
can defer a lot from f in parts where ![]() never
occurs,
without affecting the error measure. Another measure is the pointwise
absolute error
never
occurs,
without affecting the error measure. Another measure is the pointwise
absolute error
![]() for any point
for any point ![]() in S',
where
in S',
where ![]() is a subset of S that is of interest to a certain problem.
is a subset of S that is of interest to a certain problem.
Of course, f is typically high-dimensional and highly complex. A powerful
method
of constructing ![]() is using learning. Specifically, a series of cases is
acquired as the learning data set:
is using learning. Specifically, a series of cases is
acquired as the learning data set:
![]()
Then, the learning task is to construct ![]() based on L.
For notational convenience, the sample
points in L is denoted by X(L):
based on L.
For notational convenience, the sample
points in L is denoted by X(L):
X(L) should be drawn from the real situation so that the underlying distribution of X(L) is as close to the real distribution as possible.
One popular solution to approximating f is to use the nearest neighbor approximator in the eigenspace based on Karhunen-Loeve projection [32]. Following the notation of our earlier paper [15], we refer the features extracted by Karhunen-Loeve projection as the most expressive features (MEFs). The approach which uses the nearest neighbor approximator in the MEF space has been applied to the problems of face recognition [41] and 3D object recognition [35]. Weng & Chen have shown that the nearest neighbor approximator in the eigen subspace approaches f pointwise in probability. However, the features extracted by Karhunen-Loeve projection, in general, not the best ones for classification, because the features that describe some major variations in the class are typically irrelevant to how the subclasses are divided as illustrated in Fig. 4.
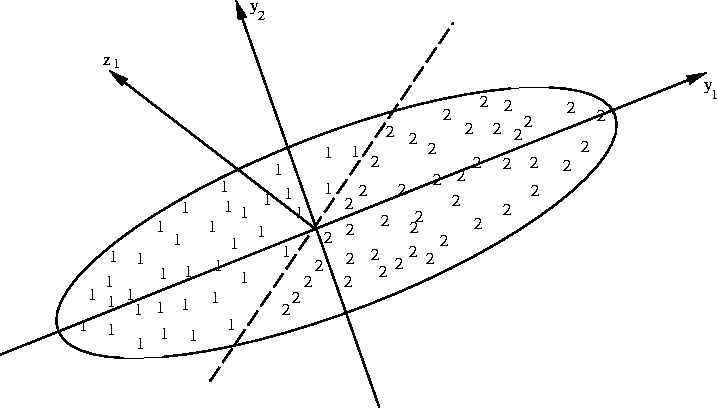
Figure 4:
A 2D illustration of the most discriminating features (MDF).
The MDF is projection along ![]() . The Karhunen-Loeve projection
along
. The Karhunen-Loeve projection
along ![]() can not
separate the two subclasses.
can not
separate the two subclasses.
In this paper, we use the multiclass, multivariate discriminant analysis [42] to select the most discriminating features (MDF's). In the MDF space, we build a recursive partition tree to approximate the function f. The details of the algorithm are in the following section. In the next section, we also show the convergence property of our new recursive partition tree approximator. Our experiments illustrate the better performance of the recursive partition tree approximator in the MDF space than the nearest neighbor approximator in the eigenspace.