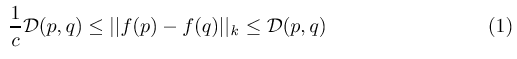Before describing our many-to-many matching framework, some
definitions are in order. To begin, a graph is a pair
, where is a finite set of vertices and is a set of
connections (edges) between the vertices. An edge consists
of two vertices such that
. A graph
is
edge-weighted, if each edge has a weight,
. Let
denote an edge-weighted graph with real edge
weights , . We will say that is a metric for
if, for any three vertices
,
, with
if and only if , and
.
One way of defining metric distances on a weighted graph is to use the
shortest-path metric on the graph or its
subgraphs, i.e.,
, the shortest path distance
between and for all
. We will say that the edge
weighted tree
is a tree metric for , with
respect to distance function , if for any pair of vertices
in , the length of the unique path between them in
is equal
to .
An ultra-metric is a special type of tree metric defined on
rooted trees, where the distance to the root is the same for all
leaves in the tree, an approximation that introduces small distortion.
A metric is an ultra-metric if, for all points , we have
Unfortunately, an ultra-metric
does not satisfy all the properties of a tree metric distance. To create a
general tree metric from an ultra-metric, we need to satisfy the
4-point condition (see [4]):
, for all . A metric
that satisfies the 4-point condition is called an additive
metric.
A metric embedding is a mapping
, where
is a set of points in the original metric space, with distance
function , is a set of points in the (host)
-dimensional normed space , and for any pair
we have
for a certain parameter , known as the distortion.
Intuitively, such an embedding will enable us to reduce problems
defined over difficult metric spaces,
, to problems
over easier normed spaces,
. As can be observed
from Equation 1, the distortion parameter is a
critical characteristic of embedding , i.e., the closer is to
, the better the target set mimics the original set .
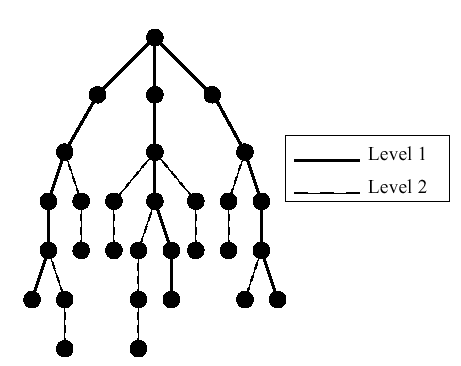
To capture the topological structure of a tree, we use the concept of
caterpillar decomposition and caterpillar dimension. We
illustrate the caterpillar decomposition of a rooted tree with no edge
weights in Figure 2. The three
darkened paths from the root represent three edge-disjoint paths,
called level 1 paths. If we remove these three level 1 paths from the
tree, we are left with the 7 dashed, edge-disjoint paths. These are
the level 2 paths, and if removing them had left additional connected
components, the process would be repeated until all the edges in the
tree had been removed. The union of the paths is called the
caterpillar decomposition, denoted by
, and the number of levels
in
is called the caterpillar dimension, denoted by .
Figure 2:
Path partition of an example tree. The three level 1 paths are
bold, while the seven level 2 paths are dashed (there are no other levels
in this particular case - see text).
The caterpillar decomposition
can be constructed using a
modified depth-first search in linear time. Given a caterpillar
decomposition
of
, we will use to denote the number of
leaves of
, and let represent the unique path between the
root and a vertex . The first segment of of weight
follows some path of level 1 in
, the second segment
of weight follows a path of level 2, and the last segment
of weight follows a path of level . The
sequences
and
will be referred to as the
decomposition sequence and the weight sequence of ,
respectively.
Finally, we introduce the notion of spherical codes in our
embedding procedure. A spherical code is the distribution of a finite
set of points on the surface of a unit sphere such that the
minimum distance between any pair of points is
maximized [6]. Equivalently, one can try to minimize the
radius of a -dimensional sphere such that points can be
placed on the surface, where any two of the points are at angular
distance 2 from each other. Recall that the angular distance between
two points is the acute angle subtended by them at the origin.
Next:Metric Embedding of Graphs Up:Many-to-Many Feature Matching Using Previous:Related Work