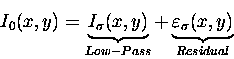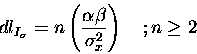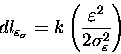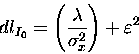Physical discontinuities, discretised as intensity variations, are particularly important in many vision tasks, such as edge detection, segmentation, and denoising. Detecting such image features can narrow the search space prior to higher layers. However it is not a straightforward task. Discontinuities are related to different imaging sources, ambient light, colour, shadows, etc. Moreover, there is a big conceptual gap in the image processing community's ideas of what are edges and regions. Unfortunately, early vague ideas addressing these definitions were left so open that a plenty of ``better'' and ``optimal'' algorithms were created, and none could see any way to assess their claims.
Therefore, the idea of denoising, keeping edges and smoothing within regions has been easily said than done. Here we present an interesting concept which encompass the idea of filtering out noise, whilst preserving discontinuities. This concept does not follow the traditional path of stating what is a ``real edge'', rather we ingeniously code both smoothing and noise estimation in a MDL framework.
We present an adaptive Gaussian filter that computes directly the local amount of Gaussian smoothing in terms of variance. It is not iterative, it is stable, does not require a gradient stopping function nor any threshold.
There is a vast amount of publications in image processing on noise reduction and edges. Among the more interesting proposals are [4,9,10,19]. Traditional algorithms like median or midpoint are usually competitive up to certain degree of Gaussian noise, however after crossing such a boundary these basic algorithms return poor images.
Anisotropic diffusions [10,11,19,20] and adaptive smoothing [14,15] are algorithms that apply successive masks, which are functions of local gradient. However, both algorithms share some drawbacks, such as: (i) a behaviour difficult to predict (e.g. similar initial values return different images), (ii) useless convergence (thus, we need to fit carefully the number of iterations), and (iii) noise and data are combined at every iteration, which in turn complicates a formal analysis. Further improvements to anisotropic diffusion have not supplied better perceptual results than the original idea [11], and new edge stopping functions have become more complex, and slower to compute.
Obviously, there is seldom a single scale that is appropriate for a complete image. However, there is one proposal [4] that computes a single global scale. Hence it cannot cope with spatially correlated noise (i.e. not adaptive). Moreover, it also cannot deal with low signal-to-noise ratios due to a high threshold on the ``confidence''. Another approach [9] computes a local estimate by maximising a measure of edge strengh over a scale space. However this estimation is based on high-order derivatives which are very sensitive to noise. Thus, the algorithm has local stability troubles, which enforces to apply a second algorithm. Therefore, it lacks robustness, and at the same time, hides the real output of the scale selection step.
Mathematicians have been working in the similar topic, that is
boundary preserving
smoothers, and robust estimation, where local M-smoothers and W-smoothers
from robust statistics have created promising lines. Although, smoothing with local M-estimators
is a cumbersome optimisation problem, it has been shown
[16]
that M-estimates converges to a robust W-estimator. Further research
has shown
[18]
a bijective relation between M-smoothers and ![]() -filters
(e.g. [3]).
Nevertheless, in the definition of a
-filters
(e.g. [3]).
Nevertheless, in the definition of a ![]() -filter we need to define two
variances (same case as bilateral filtering [17]),
which in turn
complicates
the problem by tuning not only one, but two variances. Moreover, it has been
proposed a chain of
-filter we need to define two
variances (same case as bilateral filtering [17]),
which in turn
complicates
the problem by tuning not only one, but two variances. Moreover, it has been
proposed a chain of ![]() -filters [1], where one is expected to
supply not only two variances but
a serie of pairs (stages) in certain ad-hoc order.
-filters [1], where one is expected to
supply not only two variances but
a serie of pairs (stages) in certain ad-hoc order.
Despite these developments, few
works have been addressing the point on when to stop the filtering, since all
last estimators have a piecewise constant image as fixed point. Instead, we
shall explain how to estimate a local ![]() with a non-interative
algorithm.
with a non-interative
algorithm.
There are many other interesting approaches which are less known in image processing, however a more complete but larger account of this work will be published elsewhere.
Many existing algorithms in image processing assume a scale for feature detection. This scale represents a compromise between localisation accuracy and noise sensitivity. Prior knowledge of scale is often not available or vary unpredictibly on scenes. Hence, several ideas build over this assumption fail when these filters face real images, instead we should not assume a fixed global variance (e.g. in Gaussian filtering). Here we present a method for estimating the local variance with no assumptions on scale.
Although the problem can be formulated from other points of view (e.g. [6]), in terms of Bayesian estimation is set as follows: maximising the likelihood of the observed image given the local scale, and minimising the residual.
Consider a stack of smoothed images in a linear scale-space,
![]() ,
which are computed by
convolving the initial image I0 with a serie of increasing Gaussian kernels
,
which are computed by
convolving the initial image I0 with a serie of increasing Gaussian kernels
![]() ,
where
,
where
![]() .
Thus, the objective is to choose the appropriate index (
.
Thus, the objective is to choose the appropriate index (![]() )
from the
scale-space, at each pair x,y. The criterion for such selection
is based on the Minimal Description Length principle [13,2], i.e. the less
complex or minimal, and, at the same time, effective for describing the
model.
)
from the
scale-space, at each pair x,y. The criterion for such selection
is based on the Minimal Description Length principle [13,2], i.e. the less
complex or minimal, and, at the same time, effective for describing the
model.
A Gaussian filtering can be seen as:
where the residual, called
![]() ,
is the original image minus the smoothed image.
,
is the original image minus the smoothed image.
The idea of selecting the minimal description length has been successfully applied [5,6,8,12,22] in machine vision for balancing simplicity and accuracy. The minimal description length states that the optimal model deal with the minimum number of bits that are necessary for maximising the information associated to the model. That is, the maximum smoothness with a minimal residual. Rewriting (1) as description length (dl):
It is not difficult to see that a measure of
information, in bits, for I0 is greater than
![]() ,
for
,
for
![]() .
That is, any smoothed image has less information that the
original one.
Notice that a given image at the end
is piecewise constant due to a large
.
That is, any smoothed image has less information that the
original one.
Notice that a given image at the end
is piecewise constant due to a large ![]() .
Thus, when
.
Thus, when
![]() ,
the measure of information over
,
the measure of information over
![]() is minimal.
is minimal.
In order to calculate a fast approximation of the amount of information in
![]() ,
we start with an ideal model of low-pass filtering.
Considering the behaviour of amplitude (a) in space (x) and frequency (f)
through the Scaling-Uncertainty Principle we get:
,
we start with an ideal model of low-pass filtering.
Considering the behaviour of amplitude (a) in space (x) and frequency (f)
through the Scaling-Uncertainty Principle we get:
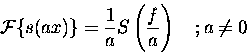
Therefore, a Gaussian distribution in space and frequency takes the form:
It is clear that the relation between the spatial domain
(
![]() )
is inversely proportional to frequency
(
)
is inversely proportional to frequency
(
![]() ), then
), then
![]() .
Further, the sampling
theorem states that for any signal of frequency f, the number of samples s(i.e. Nyquist rate) needed for reconstructing accurately the original signal is, at
least, 2f.
As we know
.
Further, the sampling
theorem states that for any signal of frequency f, the number of samples s(i.e. Nyquist rate) needed for reconstructing accurately the original signal is, at
least, 2f.
As we know
![]() given a constant (
given a constant (![]() )
to
a Gaussian band-width, which is
controlled by its variance
)
to
a Gaussian band-width, which is
controlled by its variance
![]() .
Thus, our sampling rate
could be rewritten as
.
Thus, our sampling rate
could be rewritten as
![]() .
.
Then, as a consequence of the inverse relation (2), we get that the amount of samples needed for describing a smoothed image is controlled by the spatial variance of a Gaussian kernel. That is:
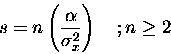
Although we cannot compute in advance how many bits represents each s, we
effectively see that it is proportional (
![]() )
to the amount of
information, given a constant
)
to the amount of
information, given a constant
![]() .
Where
.
Where ![]() is the precision, in bits, used to represent
is the precision, in bits, used to represent
![]() .
We can now summarise the above
relations in the following equation:
.
We can now summarise the above
relations in the following equation:
Equation (3) estimates the description length, in bits, of a
smoothed image given the spatial variance of a Gaussian filter.
In addition, equation (3) shows that a correct description length of
![]() is valid only within a range. The fact that n is
unknown, does not, of course, mean that is not possible to estimate.
Since
is valid only within a range. The fact that n is
unknown, does not, of course, mean that is not possible to estimate.
Since ![]() we can inspect (visually) the number where n start.
In this way, if we find the starting range,
our algorithm becomes completely stable.
Having calculated the first part of
equation (1) we can compute the residual.
we can inspect (visually) the number where n start.
In this way, if we find the starting range,
our algorithm becomes completely stable.
Having calculated the first part of
equation (1) we can compute the residual.
where
![]() is the noise variance, and
is the noise variance, and
![]() means the local quadratic residual1 between the original image, I0, and the filtered image
means the local quadratic residual1 between the original image, I0, and the filtered image
![]() .
As we have learnt from
Shannon and Rissanen [13] works,
the measure of information is closely related to the probability.
Then, we can compute a measure of information in bits of equation
(4),
applying logarithm (log2). Thus, the description
length of the residual takes the form of:
.
As we have learnt from
Shannon and Rissanen [13] works,
the measure of information is closely related to the probability.
Then, we can compute a measure of information in bits of equation
(4),
applying logarithm (log2). Thus, the description
length of the residual takes the form of:
where
![]() .
Once a
.
Once a
![]() and
and
![]() have been
definited, we may, therefore, write the local description length as
the sum of both terms, (3) and (5):
have been
definited, we may, therefore, write the local description length as
the sum of both terms, (3) and (5):
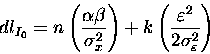
Grouping terms, we have:
where
![]() .
It is positive since that
.
It is positive since that ![]() from equation (3), and the
other constants are also positive.
It is convenient to distinguish in equation
(6), that
from equation (3), and the
other constants are also positive.
It is convenient to distinguish in equation
(6), that ![]() represents, principally, the assumed noise
variance
represents, principally, the assumed noise
variance
![]() and precision used to represent
and precision used to represent
![]() .
Thus, if we visually set
.
Thus, if we visually set ![]() to a high value, it will assume a
high noise variance and precision, together to the starting range of n.
Say, it is possible to recognise the
starting range where
to a high value, it will assume a
high noise variance and precision, together to the starting range of n.
Say, it is possible to recognise the
starting range where ![]() becomes useful.
becomes useful.
Once equation (6) is defined, one may use it to estimate directly the
local amount of smoothing in terms of variance, which is in fact
an adaptive Gaussian filter.
For every pair x,y compute2
![]() .
Then, based in the MDL principle, we choose the minimal value of
.
Then, based in the MDL principle, we choose the minimal value of
![]() at each location x,y. This
at each location x,y. This
![]() estimates
the optimal smoothness (
estimates
the optimal smoothness (
![]() )
in x,y.
)
in x,y.
The local variance ![]() of a Gaussian at x,y, allows us
the possibility of making an adaptive Gaussian filter. Each
point x,y is smoothed as
of a Gaussian at x,y, allows us
the possibility of making an adaptive Gaussian filter. Each
point x,y is smoothed as
![]() .
That is,
.
That is,
Note that in the definition of equation (6) does not appear an
edge stopping function nor gradient threshold. The minimal and maximal amount of
smoothness are controlled by the
![]() and
and
![]() in the scale
space. Moreover, an adaptive Gaussian filter (from 6) changes its shape
(
in the scale
space. Moreover, an adaptive Gaussian filter (from 6) changes its shape
(![]() )
in the next way: if the filter is close to discontinuities,
the MDL
selects a
)
in the next way: if the filter is close to discontinuities,
the MDL
selects a ![]() closed to
closed to
![]() ;
otherwise, if the filter is
located in a uniform structure, the MDL selects a variance close to
;
otherwise, if the filter is
located in a uniform structure, the MDL selects a variance close to
![]() .
Notice that, a Gaussian shape (
.
Notice that, a Gaussian shape (![]() )
changes as a
function of MDL. This is, in the neighbourhood of
discontinuities the residual
)
changes as a
function of MDL. This is, in the neighbourhood of
discontinuities the residual
![]() grows much faster
with respect to
grows much faster
with respect to ![]() than in a relatively uniform region.
As a result, the local scale selected will be small close to discontinuities, and
large
over uniform regions, which permits an effective noise elimination and
an accurate discontinuity preservation.
than in a relatively uniform region.
As a result, the local scale selected will be small close to discontinuities, and
large
over uniform regions, which permits an effective noise elimination and
an accurate discontinuity preservation.
As an example, we filtered four images, figures (1a), (2a), (3a) and (4a) depict the
input images which have been corrupted with Gaussian noise.
Figures
(1b), (2b), (3b) and (4b)
depict the local scale map computed with equation (6).
A value close to
![]() is darker.
Following two panels (``c'' and ``d'') of every figure show the initial image
after several iterations of a
standard anisotropic diffusion
algorithm3.
Following panels (``e'') depict the correponding output of a chain of
is darker.
Following two panels (``c'' and ``d'') of every figure show the initial image
after several iterations of a
standard anisotropic diffusion
algorithm3.
Following panels (``e'') depict the correponding output of a chain of
![]() -filters (so called non-linear Gaussian filters in [1]). The filter
was tuned to five stages4 (chain length),
-filters (so called non-linear Gaussian filters in [1]). The filter
was tuned to five stages4 (chain length),
![]() ,
and
,
and
![]() ,
after spending a reasonable time over the
three examples shown.
Finally, panels ``f'' depic the adaptive Gaussian filter output after applying
the
scale map (panels ``b'') on the respective original image.
Notice that the adaptive filter does not blur beyond regions nor across
discontinuities. Moreover, it does not requiere any parameter nor threshold.
,
after spending a reasonable time over the
three examples shown.
Finally, panels ``f'' depic the adaptive Gaussian filter output after applying
the
scale map (panels ``b'') on the respective original image.
Notice that the adaptive filter does not blur beyond regions nor across
discontinuities. Moreover, it does not requiere any parameter nor threshold.
Images show that the adaptive Gaussian
filter is very competitive or better than
anisotropic diffusion or a chain of
![]() -filters
at a low computational cost, and with no supplying variables.
As mentioned earlier, the algorithm is stable, i.e. not too dependent on the
value of
-filters
at a low computational cost, and with no supplying variables.
As mentioned earlier, the algorithm is stable, i.e. not too dependent on the
value of ![]() .
For instance,
.
For instance, ![]() can be within a large range with the same
performance. Presumably, the range where
can be within a large range with the same
performance. Presumably, the range where ![]() start is 3000,
which is the value always used in our experiments.
The algorithm took 3 seconds per image on an IBM H50 workstation, including
disk access.
start is 3000,
which is the value always used in our experiments.
The algorithm took 3 seconds per image on an IBM H50 workstation, including
disk access.
We have presented an adaptive Gaussian filter that computes directly
the local smoothing in terms of its variance. Which is by itself
more intuitive than a successive application of weighted averaging masks or
partial differential equations.
The smoothness is computed in such a way that keeps the main discontinuities.
Experiments show that the adaptive Gaussian
filter is very competitive or better than
anisotropic diffusion or a chain of
![]() -filters
at a low computational cost.
In fact, our technique is not iterative, it is very stable nor requires
any threshold.
-filters
at a low computational cost.
In fact, our technique is not iterative, it is very stable nor requires
any threshold.
These findings also suggest that this algorithm can contribute to the perception of different approaches, perhaps based on the MDL principle, to deal with local smoothing and feature extraction. Moreover, the MDL approach shows accurate results and could be a good way to substitute undesirable magic variables or thresholds in other low-level techniques.