


Next: Bibliography
Discontinuous Event Tracking
Jamie Sherrah and Shaogang Gong
Tracking objects in space over time is generally approached using
spatio-temporal models of movement, such as Kalman filters or Hidden
Markov Models. However, in some cases a continuous stream of
observations is not available. Rather, one obtains a series of
checkpoints showing the location of the object at successive time
instants. The tracking problem becomes one of temporal association of
objects over time based on a series of information sources rather than
spatio-temporal association alone.
An example of discontinuous motion occurs when performing real-time
tracking of a human's head and hands from a single camera
view [1]. Often body motion may appear
discontinuous since the hands can move quickly and seemingly
erratically, or undergo occlusion by other body parts. Therefore
methods such as Kalman filtering that are strongly reliant upon
well-defined dynamics and temporal continuity are generally
inadequate. However, a wide range of domain knowledge beyond the
visual input is typically utilised by a human observer to reduce
reliance on spatio-temporal consistency.
To illustrate the nature of the discontinuous body motions under
these conditions, Figures 1 and 2
show the head and hands positions and accelerations (as vectors) for
two video sequences, along with sample frames. The video frames were
sampled at 18 frames per second. Even so, there are many
significant temporal changes in both the magnitude and orientation of
the acceleration of the hands. It is unrealistic to attempt to
model the dynamics of the body under these circumstances.
Figure 1:
First example of behaviour sequences and their tracked head and hand positions and accelerations. At each time frame, the 2D acceleration is shown as an arrow with arrowhead size proportional to the acceleration magnitude. From left to right, the plots correspond to the head, left hand and right hand.
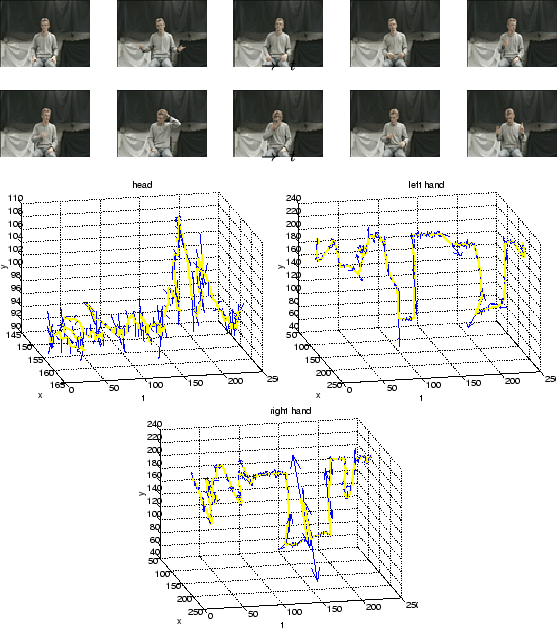 |
Figure 2:
Second example of behaviour sequences and their tracked head and hand positions and accelerations. At each time frame, the 2D acceleration is shown as an arrow with arrowhead size proportional to the acceleration magnitude. From left to right, the plots correspond to the head, left hand and right hand.
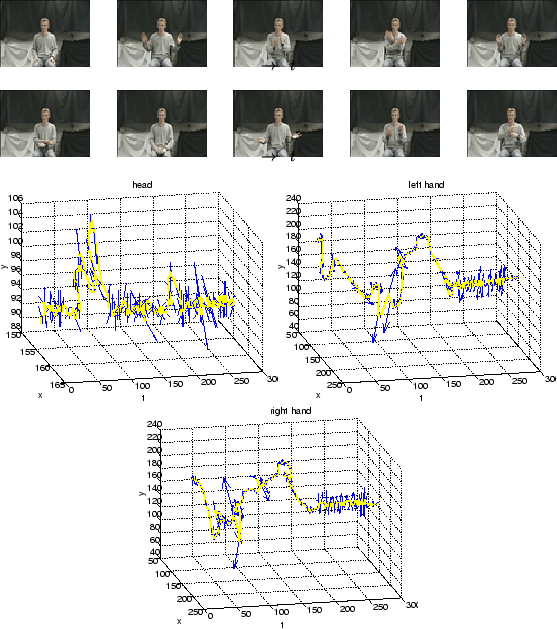 |
Let us consider the tracking problem to be equivalent to watching a
mime artist wearing a white face mask and white gloves in black
clothing against a black background. In Figure 3, for
example, given that the subject is facing the camera, it is easy for a
human to see that he is touching his face with the right hand. The
reader can accomplish this without the benefit of depth information or
spatio-temporal continuity, but rather by exploiting considerable
prior knowledge. We suggest that there is sufficient information in
the two-dimensional image to perform consistent and robust tracking of
the head and hands. A method is required that can bring our domain
knowledge to bear on the problem.
Figure 3:
Example binary skin image frames from a video sequence of a person facing the camera and scratching his nose. This representation can be contrasted with a mime artist wearing white gloves and mask against a black background.
 |
Under the assumption that the head and hands form the largest moving
connected skin coloured regions in the image, tracking the head and
hands reduces to matching the previously tracked body parts to the
skin clusters in the current frame. However, skin clusters can be
indistinguishable, and only discontinuous information is available as
though a strobe light were operating, creating a ``jerky'' effect.
Under these conditions, explicit modelling of body dynamics inevitably
makes too strong an assumption about image data. Rather, the tracking
can be performed better and more robustly through a process of
deduction. This requires full exploitation of both visual cues and
high-level contextual knowledge.
Robust, real-time human tracking systems must be
designed to work with a source of discontinuous visual
information. Any vision system operates under constraints that
attenuate the bandwidth of visual input. In some cases the data may
simply be unavailable, in other cases computation time is limited due
to finite resources. In [1], the benefits of
using contextual knowledge to track discontinuous motion by inference
rather than temporal continuity are found to be significant. In that
work, a Bayesian Belief Network (BBN) is used to encode high-level
domain knowledge about the tracking task. The BBN is used to
probabilistically infer the body part associations over time. The
commonly-encountered problem of motion discontinuities means that
consistent temporal dynamics cannot be relied upon, rather the network
fuses spatio-temporal information with a number of other cues, giving
them equal importance. Observations from the whole spatial domain are
considered during inference so that ``unexpected'' observations do not
cause the system to lose track.
Next: Bibliography
Shaogang Gong
2001-05-29