 Fundamentals:
Fundamentals:
Models of Image Formation

In the context of image formation, a sensor registers information about radiation that has interacted with physical objects. For
example, an electronic camera converts reflected light of varying intensity and hue into a two-dimensional matrix of luminance and
chrominance values, a laser rangefinder converts received laser radiation reflected from the scene when a transmitter is scanned
across it into a ``depth map'' constructed from the receiver's viewpoint. A model of the imaging process has several different components :-
- (a)
-
The image function is a mathematical representation of the image. In particular we are concerned primarily with a discrete ( digitised ) image function, by nature of the electronic processing involved. Most image functions are expressed in terms of two spatial variables,
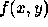 , where x and y are the two spatial coordinates.
, where x and y are the two spatial coordinates. 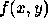 might be intensity in a range from 0 ( black ) to 255 ( white ), or colour, where
might be intensity in a range from 0 ( black ) to 255 ( white ), or colour, where
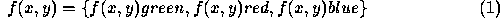
or depth, where 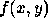 refers to the z coordinate, or distance to
an imaged point from the sensor.
In Figure 3: Intensity and depth images, the depth data is encoded by intensity, the brighter the point the nearer the viewer.
refers to the z coordinate, or distance to
an imaged point from the sensor.
In Figure 3: Intensity and depth images, the depth data is encoded by intensity, the brighter the point the nearer the viewer.
Colour spaces are a way of organising the colours perceived by humans in the range 400nm.(blue) to 700nm.(red) approx. The colour signal perceived by an electronic system may be a weighted combination of three signal channels, i.e. red, green, and blue, but this does not give any direct correspondence to the human capability to see things in black-and-white, effectively deriving intensity information from colour receptors. There are various 3-variable colour combinations in use throughout the world, e.g. IHS (intensity-saturation-hue) and YIQ respectively red-cyan, magenta-green, white-black.
- (b)
-
A geometrical model describes how the 3 world dimensions are translated into the dimensions of the sensor. In the context of a TV or still camera having a single 2D image plane, perspective projection is the fundamental mechanism whereby light is projected into a single
monocular view.
This type of projection does not yield direct information about the z-coordinate ( although several indirect ``clues'' are available ), and introduces some interesting distortions - 3D objects are more shrunken as they get further from the viewpoint, parallels converge etc.
Binocular imaging uses a system with two viewpoints, in which the eyes do not normally converge, i.e. the eyes are aimed in parallel at
an infinite point in the z direction. The depth information is encoded by it's different positions ( disparity ) in the two images.
- (c)
-
A radiometric model illustrates the way in which the imaging geometry, the light sources and the reflectance properties of objects influence the light measured at the sensor. The brightness of the image at a point, the image intensity or image irradiance where irradiance defines the power per unit area falling on a surface
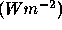 depends on the following factors.
depends on the following factors.
First, there is the radiant intensity of the source, i.e. the power per unit area emitted into a unit solid angle 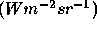 . Second there is the the reflectance of the objects in the scene, in terms of the proportion, spatial distribution and spectral variation of light reflected. The reflectance of a surface is generally somewhere between specular,
i.e. mirror-like, and Lambertian, i.e. reflecting light ``evenly'' in all directions according to a cosine distribution.
Of course, a distinction between sources and objects is over-simplistic, objects may radiate light and there will in general be multiple reflections.
It is also worth noting that most electronic light transducers do not have a linear intensity response, or more markedly they have a very non-uniform spectral response ( like humans ! ).
. Second there is the the reflectance of the objects in the scene, in terms of the proportion, spatial distribution and spectral variation of light reflected. The reflectance of a surface is generally somewhere between specular,
i.e. mirror-like, and Lambertian, i.e. reflecting light ``evenly'' in all directions according to a cosine distribution.
Of course, a distinction between sources and objects is over-simplistic, objects may radiate light and there will in general be multiple reflections.
It is also worth noting that most electronic light transducers do not have a linear intensity response, or more markedly they have a very non-uniform spectral response ( like humans ! ).
- (d)
-
The digitising model implies that the analogue scene data which varies continuously in intensity (say) and space, must be transformed into a discrete representation. Digitised images are sampled, i.e. only recorded at discrete locations, quantised , i.e. only recorded with respect to the nearest amplitude level, for example 256 levels of intensity, and windowed, i.e. only recorded to a finite extent in x and y etc. All these processes change fundamentally the world as seen by the camera or other sensor.
- (e)
-
A spatial frequency model describes how the spatial variations of the image may be characterised in the spatial frequency domain, the more rapid the variations in the image, the higher the spatial frequency. An extension of Fourier analysis from a single dimension, e.g. time,
to 2 or 3 spatial dimensions may be made, i.e.
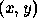 or
or 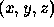 instead of t.
This type of analysis is fundamental to image processing, and since computer vision usually involves low level image processing operations
such as convolutions it is dangerous to be unaware of the implications of the recording mechanism and the effects of this and subsequent processing on the space-spatial frequency duality.
instead of t.
This type of analysis is fundamental to image processing, and since computer vision usually involves low level image processing operations
such as convolutions it is dangerous to be unaware of the implications of the recording mechanism and the effects of this and subsequent processing on the space-spatial frequency duality.
There are many different mediums for image acquisition, including ultrasound, visible light, infra-red light, X-rays etc. Of these, visible light is the most widely used, and there are many acquisition systems based on TV cameras, spot rangers, laser scanners and solid state devices.
To scan the image in two dimensions a raster scan system is commonly used, in which the scanning mechanism may be electrical, mechanical or a combination of both. Generally, access to the stored image data is on a random basis.


[ Introduction |
Models of Geometric Projection ]

Comments to: Sarah Price at ICBL.
(Last update: 4th July, 1996)