1 The Discrete Kalman Filter
In 1960, R.E. Kalman published his famous paper describing a recursive solution to the discrete-data linear filtering problem [Kalman60]. Since that time, due in large part to advances in digital computing, the Kalman filter has been the subject of extensive research and application, particularly in the area of autonomous or assisted navigation. A very "friendly" introduction to the general idea of the Kalman filter can be found in Chapter 1 of [Maybeck79], while a more complete introductory discussion can be found in [Sorenson70], which also contains some interesting historical narrative. More extensive references include [Gelb74], [Maybeck79], [Lewis86], [Brown92], and [Jacobs93].
The Probabilistic Origins of the Filter
The justification for
(1.7)
is rooted in the probability of the a priori estimate 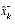 conditioned on all prior measurements
conditioned on all prior measurements 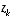 (Bayes' rule). For now let it suffice to point out that the Kalman filter maintains the first two moments of the state distribution,
(Bayes' rule). For now let it suffice to point out that the Kalman filter maintains the first two moments of the state distribution,
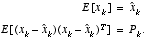
The a posteriori state estimate
(1.7)
reflects the mean (the first moment) of the state distribution-- it is normally distributed if the conditions of
(1.3)
and
(1.4)
are met. The a posteriori estimate error covariance
(1.6)
reflects the variance of the state distribution (the second non-central moment). In other words,
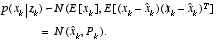 .
.
For more details on the probabilistic origins of the Kalman filter, see [Maybeck79], [Brown92], or [Jacobs93].
The Discrete Kalman Filter Algorithm
We will begin this section with a broad overview, covering the "high-level" operation of one form of the discrete Kalman filter (see the previous footnote). After presenting this high-level view, we will narrow the focus to the specific equations and their use in this version of the filter.
The Kalman filter estimates a process by using a form of feedback control: the filter estimates the process state at some time and then obtains feedback in the form of (noisy) measurements. As such, the equations for the Kalman filter fall into two groups: time update equations and measurement update equations. The time update equations are responsible for projecting forward (in time) the current state and error covariance estimates to obtain the a priori estimates for the next time step. The measurement update equations are responsible for the feedback--i.e. for incorporating a new measurement into the a priori estimate to obtain an improved a posteriori estimate.
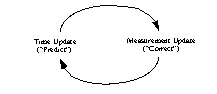
The time update equations can also be thought of as predictor equations, while the measurement update equations can be thought of as corrector equations. Indeed the final estimation algorithm resembles that of a predictor-corrector algorithm for solving numerical problems as shown below in
Figure 1-1
.
Figure 1-1.
The ongoing discrete Kalman filter cycle. The time update projects the current state estimate ahead in time. The measurement update adjusts the projected estimate by an actual measurement at that time.
The specific equations for the time and measurement updates are presented below in
Table 1-1
and
Table 1-2
.
Table 1-1:
Discrete Kalman filter time update equations.
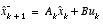 (1.9)
(1.9)
|
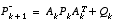 (1.10)
(1.10)
|
Again notice how the time update equations in
Table 1-1
project the state and covariance estimates from time step k to step k+1. 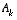 and B are from
(1.1)
, while
and B are from
(1.1)
, while 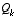 is from
(1.3)
. Initial conditions for the filter are discussed in the earlier references.
is from
(1.3)
. Initial conditions for the filter are discussed in the earlier references.
Table 1-2:
Discrete Kalman filter measurement update equations.
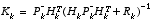 (1.11)
(1.11)
|
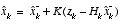 (1.12)
(1.12)
|
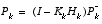 (1.13)
(1.13)
|
The first task during the measurement update is to compute the Kalman gain, 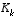 . Notice that the equation given here as
(1.11)
is the same as
(1.8)
. The next step is to actually measure the process to obtain
. Notice that the equation given here as
(1.11)
is the same as
(1.8)
. The next step is to actually measure the process to obtain  , and then to generate an a posteriori state estimate by incorporating the measurement as in
(1.12)
. Again
(1.12)
is simply
(1.7)
repeated here for completeness. The final step is to obtain an a posteriori error covariance estimate via
(1.13)
.
, and then to generate an a posteriori state estimate by incorporating the measurement as in
(1.12)
. Again
(1.12)
is simply
(1.7)
repeated here for completeness. The final step is to obtain an a posteriori error covariance estimate via
(1.13)
.
After each time and measurement update pair, the process is repeated with the previous a posteriori estimates used to project or predict the new a priori estimates. This recursive nature is one of the very appealing features of the Kalman filter--it makes practical implementations much more feasible than (for example) an implementation of a Weiner filter [Brown92] which is designed to operate on all of the data directly for each estimate. The Kalman filter instead recursively conditions the current estimate on all of the past measurements.
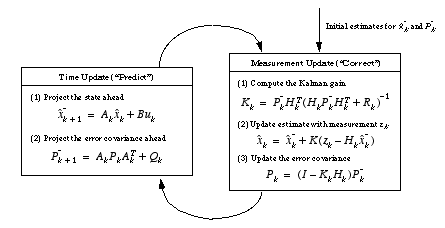
Figure 1-2
below offers a complete picture of the operation of the filter, combining the high-level diagram of
Figure 1-1
with the equations from
Table 1-1
and
Table 1-2
.
Filter Parameters and Tuning
In the actual implementation of the filter, each of the measurement error covariance matrix 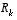 and the process noise
and the process noise 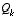 (given by
(1.4)
and
(1.3)
respectively) might be measured prior to operation of the filter. In the case of the measurement error covariance
(given by
(1.4)
and
(1.3)
respectively) might be measured prior to operation of the filter. In the case of the measurement error covariance 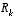 in particular this makes sense--because we need to be able to measure the process (while operating the filter) we should generally be able to take some off-line sample measurements in order to determine the variance of the measurement error.
in particular this makes sense--because we need to be able to measure the process (while operating the filter) we should generally be able to take some off-line sample measurements in order to determine the variance of the measurement error.
In the case of 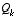 , often times the choice is less deterministic. For example, this noise source is often used to represent the uncertainty in the process model
(1.1)
. Sometimes a very poor model can be used simply by "injecting" enough uncertainty via the selection of
, often times the choice is less deterministic. For example, this noise source is often used to represent the uncertainty in the process model
(1.1)
. Sometimes a very poor model can be used simply by "injecting" enough uncertainty via the selection of 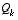 . Certainly in this case one would hope that the measurements of the process would be reliable.
. Certainly in this case one would hope that the measurements of the process would be reliable.
In either case, whether or not we have a rational basis for choosing the parameters, often times superior filter performance (statistically speaking) can be obtained by "tuning" the filter parameters 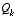 and
and 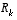 . The tuning is usually performed off-line, frequently with the help of another (distinct) Kalman filter.
. The tuning is usually performed off-line, frequently with the help of another (distinct) Kalman filter.
Figure 1-2.
A complete picture of the operation of the Kalman filter, combining the high-level diagram of Figure 1-1
with the equations from Table 1-1
and Table 1-2
.
In closing we note that under conditions where 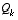 and
and 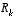 .are constant, both the estimation error covariance
.are constant, both the estimation error covariance 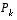 and the Kalman gain
and the Kalman gain 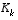 will stabilize quickly and then remain constant (see the filter update equations in
Figure 1-2
). If this is the case, these parameters can be pre-computed by either running the filter off-line, or for example by solving
(1.10)
for the steady-state value of
will stabilize quickly and then remain constant (see the filter update equations in
Figure 1-2
). If this is the case, these parameters can be pre-computed by either running the filter off-line, or for example by solving
(1.10)
for the steady-state value of 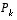 by defining
by defining 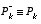 and solving for
and solving for 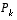 .
.
It is frequently the case however that the measurement error (in particular) does not remain constant. For example, when sighting beacons in our optoelectronic tracker ceiling panels, the noise in measurements of nearby beacons will be smaller than that in far-away beacons. Also, the process noise 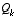 is sometimes changed dynamically during filter operation in order to adjust to different dynamics. For example, in the case of tracking the head of a user of a 3D virtual environment we might reduce the magnitude of
is sometimes changed dynamically during filter operation in order to adjust to different dynamics. For example, in the case of tracking the head of a user of a 3D virtual environment we might reduce the magnitude of 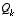 if the user seems to be moving slowly, and increase the magnitude if the dynamics start changing rapidly. In such a case
if the user seems to be moving slowly, and increase the magnitude if the dynamics start changing rapidly. In such a case 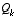 can be used to model not only the uncertainty in the model, but also the uncertainty of the user's intentions.
can be used to model not only the uncertainty in the model, but also the uncertainty of the user's intentions.
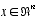 of a discrete-time controlled process that is governed by the linear stochastic difference equation
of a discrete-time controlled process that is governed by the linear stochastic difference equation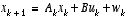 ,
,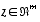 that is
that is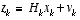 . (1.2)
. (1.2)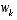 and
and 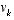 represent the process and measurement noise (respectively). They are assumed to be independent (of each other), white, and with normal probability distributions
represent the process and measurement noise (respectively). They are assumed to be independent (of each other), white, and with normal probability distributions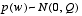 , (1.3)
, (1.3)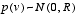 . (1.4)
. (1.4)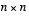 matrix A in the difference equation
(1.1)
relates the state at time step k to the state at step k+1, in the absence of either a driving function or process noise. The
matrix A in the difference equation
(1.1)
relates the state at time step k to the state at step k+1, in the absence of either a driving function or process noise. The 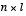 matrix B relates the control input
matrix B relates the control input 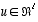 to the state x. The
to the state x. The 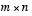 matrix H in the measurement equation
(1.2)
relates the state to the measurement zk.
matrix H in the measurement equation
(1.2)
relates the state to the measurement zk.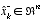 (note the "super minus") to be our a priori state estimate at step k given knowledge of the process prior to step k, and
(note the "super minus") to be our a priori state estimate at step k given knowledge of the process prior to step k, and 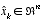 to be our a posteriori state estimate at step k given measurement
to be our a posteriori state estimate at step k given measurement 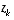 . We can then define a priori and a posteriori estimate errors as
. We can then define a priori and a posteriori estimate errors as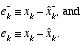
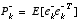 , (1.5)
, (1.5)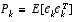 . (1.6)
. (1.6)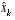 as a linear combination of an a priori estimate
as a linear combination of an a priori estimate 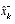 and a weighted difference between an actual measurement
and a weighted difference between an actual measurement 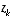 and a measurement prediction
and a measurement prediction 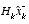 as shown below in
as shown below in 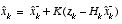 (1.7)
(1.7)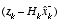 in
in 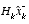 and the actual measurement
and the actual measurement 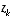 . A residual of zero means that the two are in complete agreement.
. A residual of zero means that the two are in complete agreement.  matrix K in
matrix K in 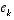 , substituting that into
, substituting that into 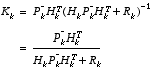 . (1.8)
. (1.8)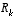 approaches zero, the gain K weights the residual more heavily. Specifically,
approaches zero, the gain K weights the residual more heavily. Specifically,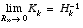 .
.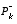 approaches zero, the gain K weights the residual less heavily. Specifically,
approaches zero, the gain K weights the residual less heavily. Specifically,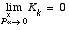 .
.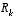 approaches zero, the actual measurement
approaches zero, the actual measurement 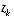 is "trusted" more and more, while the predicted measurement
is "trusted" more and more, while the predicted measurement 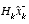 is trusted less and less. On the other hand, as the a priori estimate error covariance
is trusted less and less. On the other hand, as the a priori estimate error covariance 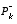 approaches zero the actual measurement
approaches zero the actual measurement 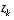 is trusted less and less, while the predicted measurement
is trusted less and less, while the predicted measurement 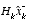 is trusted more and more.
is trusted more and more.