ASR in Interspeech 2020
This note summarizes my initial pass over papers in Interspeech 2020 aiming to improve ASR. A total of 122 papers has been skimmed. Similar to the summary for this year's ICASSP, I will focus on affiliations, data sets, and models.
Unlike last time, I will not discuss research questions posed in the papers. It is disappointing that, out of the 122 papers, 50 of them do not have a clear motivation, and within the rest, many of them have either circular or vague motivations. For example, it is common to see these types of research questions in the abstracts: “it is unclear how approach X affects model Y,” “few studied the problem X,” “few compared systems X and Y,” “performance degrades in senario X.” These types of questions do not provide properties of the problem for others to build on, and obscure what the proposed approach is actually solving. We would all gain more clarity if every paper includes some amounts of deductive reasoning on the research questions being studied. Two great examples to learn from are Bruguier et al. and Inaguma et al.
Here are the sessions with papers aiming to improve ASR.
- ASR neural network architectures I
- ASR neural network architectures II - Transformers
- Automatic speech recognition for non-native children's speech
- Noise robust and distant speech recognition
- ASR neural network architectures and training I
- ASR neural network architectures and training II
- Topics in ASR I
- ASR model training and strategies
- Cross/multi-lingual and code-switched speech recognition
- Acoustic model adaptation for ASR
- Feature extraction and distant ASR
- Search for speech recognition
- Streaming ASR
- Training strategies for ASR
- General topics in speech recognition
The first observation is that there are many more ASR sessions compared to the this year's ICASSP. Streaming and transformers continue to be the two special foci.
Affiliations
Let's look at paper counts from companies. Same as before, internship papers are counted towards the companies.
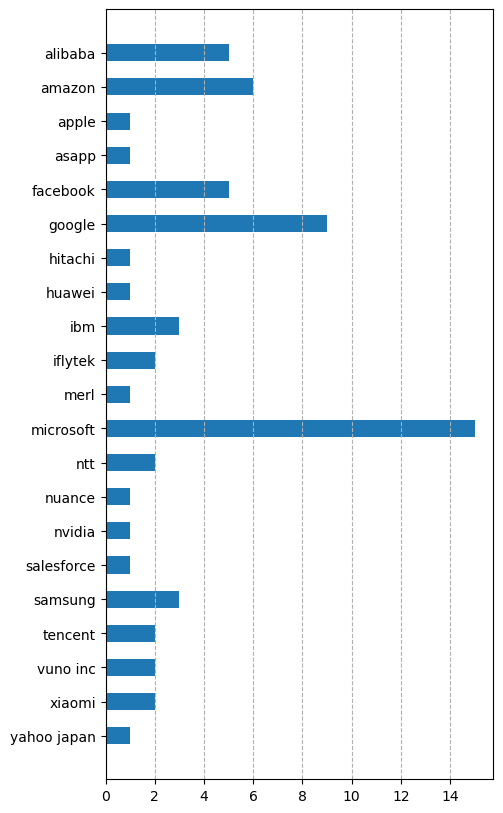
In North America, Amazon, Facebook, Google, and Microsoft are (not surprisingly) the dominant players.
The following figure is the number of papers associated to an institute in academia.
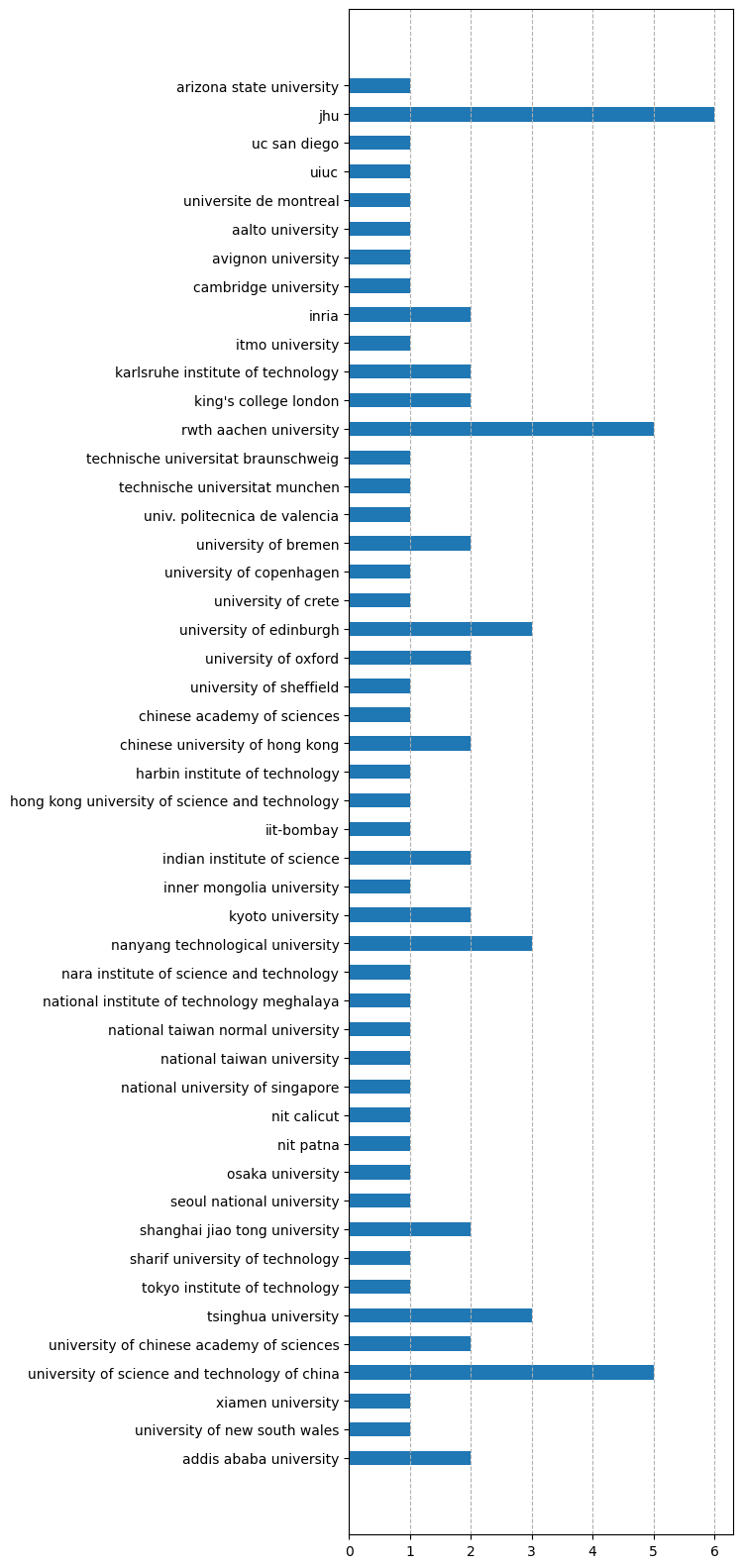
Johns Hopkins University and RWTH Aachen University continue to be the major player in ASR. University of Science and Technology of China is also having good success.
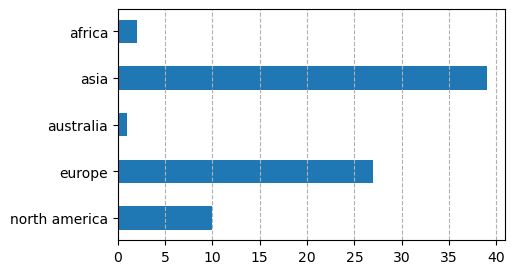
If we count academia papers based on continents, it is clear that the bulk of research coming out of academia are from Asia and Europe, while in North America, the research in ASR is mainly done in industry.
Finally, 65 papers are counted towards companies, while 79 paper are counted towards academia.1
Data sets
The following figure shows the number of times each data set is used.
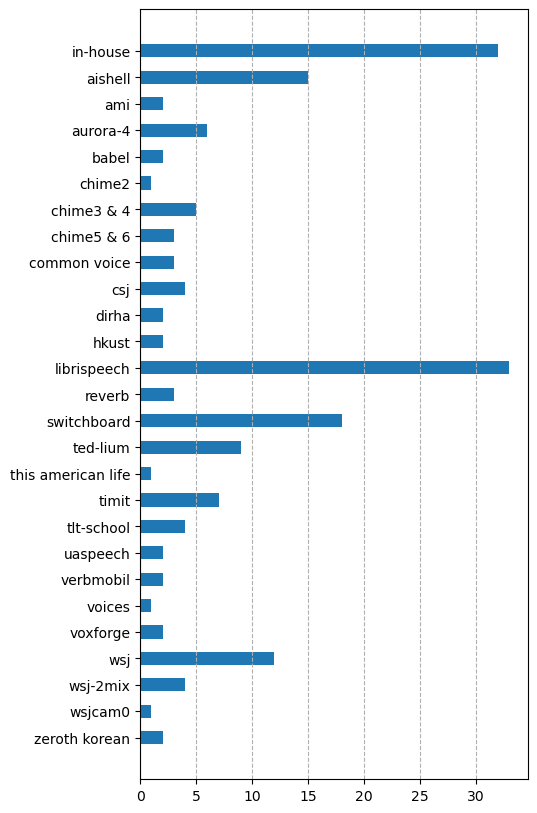
There is no surprise that a large amount of papers work on in-house data sets. Librispeech and Switchboard continue to be the dominant data sets for English ASR, while AISHELL is the main data set for Mandarin ASR. One thing worth noting is that the Common Voice data set has now started to be used for multilingual ASR.
Models
The following figure counts the number of times an architecture is used in a paper. Note that it is getting harder to count architectures, because it is common to see a combination of architectures, for example, an LSTM on top of a few layers of convolution. Some papers don't even bother mentioning the convolutions. If multiple types of architectures are used, they are all counted.
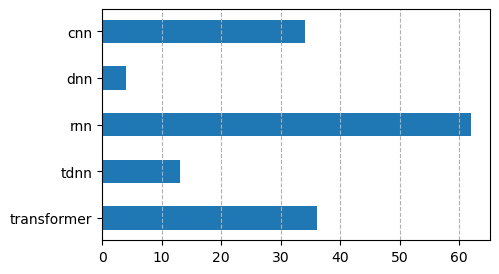
Recurrent neural networks (in particular LSTMs) are still the dominant architecture, but transformers are getting increasingly more common.
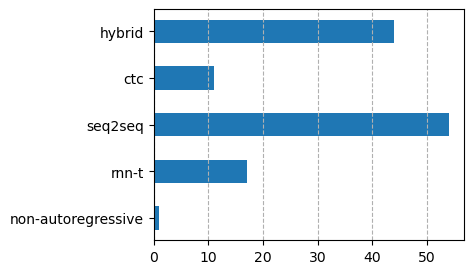
In terms of systems, seq2seq continues to be the dominant target of research, while hybrid systems are still going strong. The boundary between hybrid systems and CTC has becomed blurred. Many systems trained with CTC are now called hybrid systems due to the use of FSTs for lexicons and LMs. Many seq2seq systems are trained alongside a CTC loss, and those are counted towards seq2seq.
Unlike machine translation, non-autoregressive approaches have not caught up in ASR. It is at its infancy and probably cannot compete with other approaches, but non-autoregressive approaches provide an interesting alternative.
Another interesting observation is that the majority of, if not all, papers in the special session on non-native Children's speech use a hybrid system.2
Final thoughts
Two papers catch my eye while preparing this summary—Tuske et al. achieves the state of the art on Switchboard with seq2seq and LSTMs, and Zhang et al. achieves the state of the art on Librispeech with CTC and transformers. They question the need of all the fancy new techniques, and send a strong signal that perhaps there is a simpler and cleaner model waiting to be discovered.
| 1 | The two don't add up to 122 because some papers have authors from both sides. |
| 2 | People don't seem to have faith in end-to-end approaches for low-resource tasks. |