Given the initial location estimates and the geometric model, it is easy to predict where a visible surface should appear. This prediction simplifies direct search for image evidence for the feature. This is, in style, like the work of Freuder [75], except that three dimensional scenes are considered here.
To select good image evidence for an uninstantiated model feature, the oriented
model is used to predict roughly where the surface data should appear.
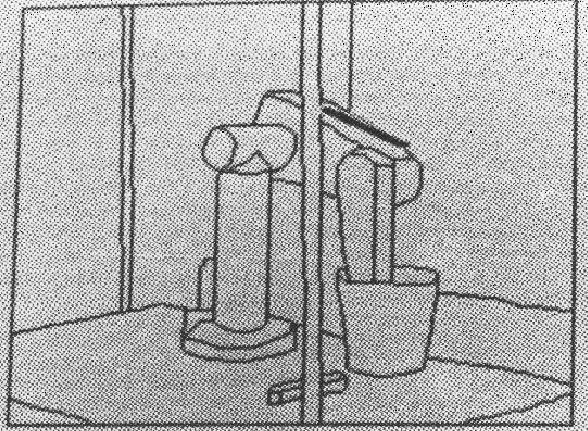
Figure 9.20 shows the predicted location for the robot upper arm
![]() panel superimposed on the original image
using the initial parameter estimates for
panel superimposed on the original image
using the initial parameter estimates for ![]() .
.
Other constraints can then be applied to eliminate most inappropriate surfaces from the predicted area. The constraints that a potential surface must meet are:
The implemented algorithm used the constraints 1 to 5, with some
parameter tolerances on 3, 4 and 5.
The ![]() was not used because likely causes for not finding the surface
during invocation were: it was partially obscured, it was incompletely segmented
or it was merged during the surface reconstruction process (Chapter 4).
The result of these would be incorrect shapes.
These factors also affect the area constraint (6), so this was used only to
select a single surface if more than one met the first five constraints
(but this did not occur in the test scene).
was not used because likely causes for not finding the surface
during invocation were: it was partially obscured, it was incompletely segmented
or it was merged during the surface reconstruction process (Chapter 4).
The result of these would be incorrect shapes.
These factors also affect the area constraint (6), so this was used only to
select a single surface if more than one met the first five constraints
(but this did not occur in the test scene).
The implemented algorithm is:
| Let: | |
| S = {all surfaces in the surface cluster not previously used in the hypothesis} = { |
|
| If: | ||
| (constraint 3) | ||
|
|
( |
|
| (constraint 4) | ||
|
|
( |
|
| (constraint 5) | ||
|
|
( |
|
| Then: | ||
The surface selected is the acceptable ![]() whose area is closest
to that predicted, by minimizing:
whose area is closest
to that predicted, by minimizing:

In the test image, the only missing SURFACEs were the two side surfaces on the upper arm and the inside surface at the back of the trash can. For the trash can, the only potential image surfaces for the trash can back surface were the two visible surfaces in the surface cluster. The front surface was already used in both cases, and the rear surface met all the other constraints, so was selected. A similar process applied to the upper arm side panels.