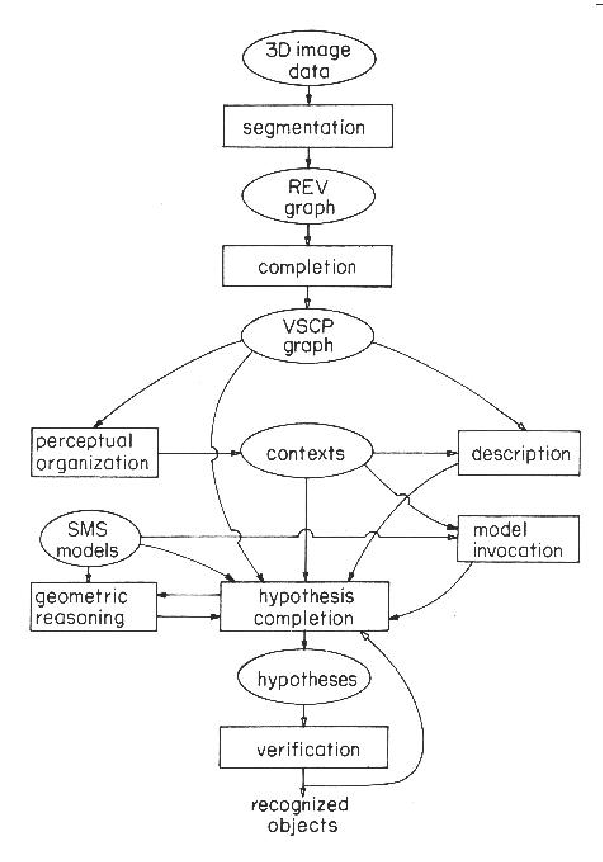
Experience with the IMAGINE I program has led to a redesign embodied in the IMAGINE II system. Though the re-implementation is not complete, the design of the system and its key representations and processes are summarized here. Figure 11.1 shows a block diagram of the main modules of the IMAGINE II system. The system is intended to interpret data deriving from scenes containing self and externally obscured complex, non-polyhedral man-made objects including possible degrees-of-freedom (e.g. robot joints).
As in IMAGINE I, data comes from a segmented
![]() sketch,
except that curve and volumetric scene features may be part of the input, too.
The data may be fragmented or incomplete.
The input data structure is a REV (Region, Edge, Vertex) graph.
The system output is, as before, a list of object hypotheses with position
and parameter estimates and a set of image evidence and justifications
supporting the object hypothesis.
sketch,
except that curve and volumetric scene features may be part of the input, too.
The data may be fragmented or incomplete.
The input data structure is a REV (Region, Edge, Vertex) graph.
The system output is, as before, a list of object hypotheses with position
and parameter estimates and a set of image evidence and justifications
supporting the object hypothesis.
The first new representation is the VSCP structure (Volume, Surface, Curve, Point), which is constructed from the REV by knowledge-based structure completion processes. The goal of this process is to group curve and surface features from the REV to overcome fragmentation and occlusion effects and to remove non-structural artifacts (e.g. reflectance edges). The original raw data might be interrogated to help verify deductions.
An example of an occlusion rule is:
An example of a fragmentation rule is:
Invocation and matching occur in data contexts, only now contexts exist for curves and volumes as well as surfaces and surface clusters. Contexts improve matching efficiency by grouping related data and thereby isolating irrelevant data, and create a structure that can accumulate plausibility for model invocation.
The context structures are hierarchical in that contexts can be grouped to form larger contexts. Contexts are designed to support recognition of curves, surfaces, volumes and larger groupings of features. For example, the information contained in a surface context might link to both curve fragments and surface patches, because either might help define a complete surface.
Examples of context-forming rules are:
Structure Description
Model invocation and hypothesis construction require property estimates for image features, and because we are using 2 1/2D sketch data, three dimensional properties can be directly measured. These properties are similar to those used for IMAGINE I (Chapter 6), and include:
Model Invocation
Model invocation is nearly the same as in IMAGINE I (Chapter 8).
A network implements the computation in a manner suitable for parallel
evaluation.
Nodes represent the pairing between individual model and data
features, and are connected to other nodes according to the type of
relation.
Relations include: structural (e.g. "subcomponent of"), generic
(e.g. "visual specialization of"), class (e.g. "non-visual specialization of"),
inhibiting and general association.
Direct evidence comes from a measure of the fit between data and model
properties.
Object Models
The SMS models are used, as described in Chapter 7. They are primarily structural with model primitives designed to match with either curve, surface or volumetric data as alternatives. The models are hierarchical, building larger models from previously defined substructures. All model dimensions and reference frame transformations may involve variables and expressions, and algebraic constraints can bound the range of the variables.
The models have viewpoint dependent feature groups, which record the
fundamentally distinct viewpoints of the object.
They also identify (1) model features visible from the viewpoint and (2) new viewpoint
dependent features (such as occlusion relationships,
TEE junctions or extremal boundaries).
Hypothesis Construction
Initial selection of the model may come bottom-up from invocation or top-down as part of another hypothesis being constructed. Hypothesis construction then attempts to find evidence for all model features.
Feature visibility information comes from a viewpoint dependent feature group, which is selected according to the estimated orientation of the object.
Construction is largely hierarchical, grouping recognized subcomponents to form larger hypotheses. The most primitive features are designed to be recognized using either curve, surface or volumetric data, depending on what is available. At all stages, geometric consistency is required, which also results in more precise position estimates and estimates for embedded variables (such as a variable rotation angle about an axis).
Construction is a heuristic process whereby various approaches are tried to find evidence for a feature. For example, some heuristics for surface finding are:
The network-based geometric reasoning was described here. The geometric relationships between model features, model and data pairings and a priori scene knowledge are represented algebraically and are implemented as networks expressing the computational relationships between the variables.
Analysis of the types of geometric relationships occurring in scene analysis
showed that most relationships could be expressed using only a small set of
standard relationships (e.g. "a model point is paired with a data point").
The standard relationships are then be used to create standard network
modules, which are allocated and connected as
model matching produces new model-to-data pairings.
Agenda Management
To facilitate experimentation with different control regimes, the hypothesis
construction processes are activated from a priority-ordered agenda.
The processes take inputs from and return results to a global blackboard.
An agenda item embodies a request for applying a specified hypothesis
construction process on a given datum or hypothesis.
The activated process may then enter other requests into the agenda.
We use the agenda to implement a mixed control regime involving both
top-down and bottom-up hypothesis construction.
Hypothesis Verification
Because data can be fragmented or erroneous, object hypotheses may be incomplete. Further, spurious hypotheses may be created from coincidental alignments between scene features. Hypothesis construction and geometric reasoning eliminate some spurious hypotheses, but other instances of global inconsistency may remain.
This module considers two problems: (1) global consistency of evidence (e.g. connectedness and proper depth ordering of all components) and (2) heuristic criteria for when to accept incomplete models.