



The purpose of redefining the unit transfer function was to permit
intermediate network layers to produce ``visible'' influence at the
output layer.
For a multi layer network,
equation 3 still measures the performance, and
the LMS gradient descent update procedure 4
is still valid, but
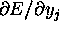 (part of equation 5)
is not easy to calculate for the hidden units.
(part of equation 5)
is not easy to calculate for the hidden units.
We solve this problem by assuming that units in a given layer (J)
only directly
affect units in the immediately subsequent layer (K);
we further assume that for 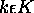 , we have already somehow
computed
, we have already somehow
computed
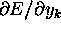 .
We then can observe that
.
We then can observe that
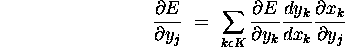
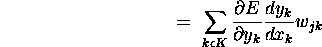
That is, what we want is now computable.
We can ``bootstrap'' this procedure by noting that for the output units,
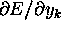 is available from equation 3 as before.
Thus the derivatives we require can be propagated backwards through the
network.
is available from equation 3 as before.
Thus the derivatives we require can be propagated backwards through the
network.
Speed of convergence in back propagation networks is a problem, and the literature on ways around this is very full.
A commonly used acceleration to training is to use the rule
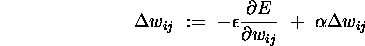
(so before we had 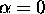 ).
).
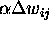 is a momentum
term which has the dual benefit of keeping convergence
moving on plateaux, and damping oscillations in ravines.
is a momentum
term which has the dual benefit of keeping convergence
moving on plateaux, and damping oscillations in ravines.
The choice of  and
and 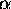 is critical - it may be possible for
them to adapt to the local shape of the error surface, thereby speeding
convergence.
is critical - it may be possible for
them to adapt to the local shape of the error surface, thereby speeding
convergence.