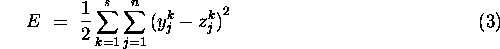Suppose a set of input patterns
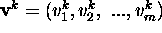 is associated with a set of output patterns
is associated with a set of output patterns
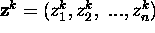 for
for 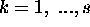 , with the input loaded onto the m inputs of an
array of n generalised perceptrons, whose transfer function is the
sigmoid
, with the input loaded onto the m inputs of an
array of n generalised perceptrons, whose transfer function is the
sigmoid

The performance of the network may be measured by the error
where 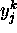 is the state of the
is the state of the 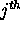 unit when the
input pattern is
unit when the
input pattern is 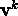 .
E is non-negative, being zero when the network performs `perfectly',
`small' for `good' performance and `large' for `poor' performance.
We note that E depends on the values of the weights, and may hope therefore
to reduce it by performing a gradient descent
.
E is non-negative, being zero when the network performs `perfectly',
`small' for `good' performance and `large' for `poor' performance.
We note that E depends on the values of the weights, and may hope therefore
to reduce it by performing a gradient descent
iteratively (where, as usual, 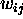 is the weight on the
is the weight on the
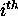 input to unit j.
input to unit j.
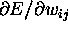 is easily determined (by differentiating
the unit input formula and 3);
is easily determined (by differentiating
the unit input formula and 3);
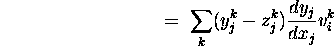
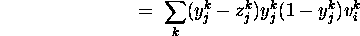
For such simple networks (no intermediate units), we are guaranteed to
minimise E if we take small enough  and perform enough
iterations (although this minimum may well not be 0).
and perform enough
iterations (although this minimum may well not be 0).