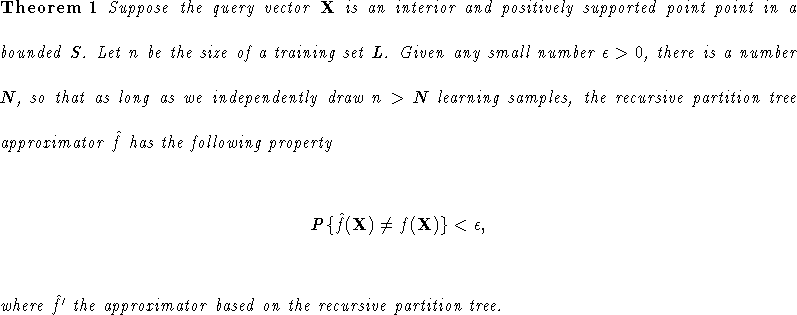

An important issue to study here is how well the above approximators can approximate a function f. Its answer is closely related to the way samples are generated for the learning set L. In [44], Weng and Chen have shown that the nearest neighbor approximator approaches f pointwise in probability. In this section, we show that the same result also holds for the recursive partition tree approximator.
Due to a high complexity and
undetermined nature
of the way in which a learning set L is drawn from the real world, it is
effective to consider that X(L), the set of samples in S, is generated
randomly.
We know that a fixed L is a special case of random L in that the
probability distribution is concentrated at the single location.
Thus, we consider ![]() in X(L) as a random sample from S. The
learning set
L is generated by acquiring samples from S with a d-dimensional
probability
distribution function
in X(L) as a random sample from S. The
learning set
L is generated by acquiring samples from S with a d-dimensional
probability
distribution function ![]() .
.
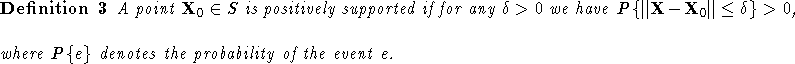
If S consists of a finite number of discrete points, a point ![]() in
P is
positively supported means that the probability of selecting
in
P is
positively supported means that the probability of selecting ![]() as a
sample is not a zero-probability event. If S consists of infinitely many
points,
a point
as a
sample is not a zero-probability event. If S consists of infinitely many
points,
a point ![]() in P is positively supported means that in any small
neighborhood centered at
in P is positively supported means that in any small
neighborhood centered at ![]() , the probability of selecting any point in
the neighborhood is not a zero-probability event. In practice, we are not
interested in cases that almost never appears in a real-world application. An
approximate function
, the probability of selecting any point in
the neighborhood is not a zero-probability event. In practice, we are not
interested in cases that almost never appears in a real-world application. An
approximate function ![]() can assume any value in subregions of S that
will never be used in the application, without hurting the real performance
of the system. Thus, we just need to investigate how well the approximation
can do at points
can assume any value in subregions of S that
will never be used in the application, without hurting the real performance
of the system. Thus, we just need to investigate how well the approximation
can do at points ![]() 's that are positively supported.
's that are positively supported.
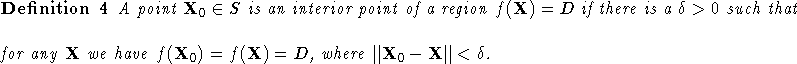
For a classification problem, we have a set of discrete number of
categories to be assigned to the input. Then, ![]() is
continuous only at the interior points.
is
continuous only at the interior points.
The proof is presented in Appendix A. Theorem 1 means
that the RPTA approaches f pointwisely in probability:
![]() , as the size
of training set L increases without bound.
, as the size
of training set L increases without bound.