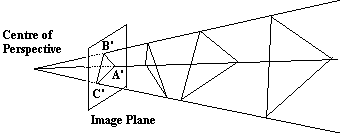
Figure 1: Back-projecting a triangle into the world


The problem of 3D interpretation of single 2D images is difficult because there is no unique calculation of 3D position in the world coordinate system. For example, consider Figure 1, below. The image plane shows a simple triangle, but there are an infinite number of possible triangles which could give rise to this image. In order to solve this problem we need additional information. Of course, one way to provide this is to take another image or images from a different viewpoint, depth from stereo or depth from motion. We can also infer or calculate relative depth from shading or texture. In this section we shall consider the most common constraint, knowledge of the object or objects which we are looking at from a rigid model.
As in the 3D-3D case, we must first attempt to find matching points or vectors based on analysis of primitives in the scene and in the model. From matched primitives, we calculate the pose. In the 3D-3D case, we were able to use geometric invariants such as the angle between planes or space curves, or the 3D separation of control points to index possible models. These invariants are more difficult to find in the 2D perspective case. One approach is to use complex higher order mathematical invariants; the alternative approach we consider here is to use grouping and non-accidental properties to generate matching hypotheses.



[ Contents: Matching and locating 3D models in 2D images |
Grouping and non-accidental properties ]
Comments to: Sarah Price at ICBL.