If both the view and scene geometry are unknown but the scene structure remains rigid between views, then it is possible to deduce the viewing geometry (up to a scale factor) and hence to solve for the scene structure. In such a scenario, all we have is a number of matched points in two images. The viewing geometry is specified by six parameters, namely the translation and rotation parameters of the camera motion.
Each observation of a point in the two images gives us four pieces of information, the row and column pixel coordinates in the two images. However, we also introduce three unknowns for each observation, namely the 3D coordinates of the observed point.
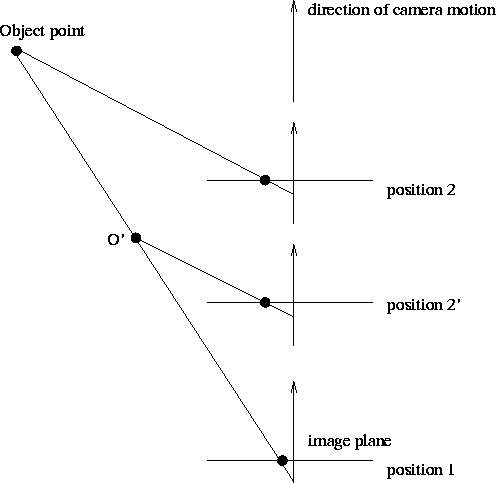
Thus, if n points are observed, we have 6 + 3n unknowns, and 4n observations. However, it is only possible to deduce camera translation up to a scale factor, as is illustrated in figure 5. So we really only have 5 + 3n solvable unknowns. From this we can deduce that we must have at least n = 5 observations of matched points to solve the system. In practice many more points than 5 are used to reduce the influence of noise.
 |