Moses et al, have constructed a theoretical argument for why
non-model-based vision systems cannot correctly recognize objects in
a consistent manner [58]. The authors offer a mathematical
proof for their arguments based on a definition of consistent
recognition functions. The details of this proof are beyond the
scope of this dissertation. However, the basic result of the proof is
that because different objects can produce similar looking images or
image features, it is not possible to distinguish these objects
without prior knowledge of how the images were formed. For example,
consider the cylinder and the truncated cone in
Figure ![]() . Both the top and bottom as well as
the left and right sides of the cylinder are parallel in view (a), and
the left and right sides of the cone are antiparallel. However, when
viewed from orientation (b), the left and right sides of the cylinder
have become antiparallel, making the cylinder indistinguishable from
the cone. In order to recognize these two objects, a non-model-based
vision system would have to be trained on all possible perspective
transformations of these two objects. Furthermore, it would be
difficult to take into account a known viewing orientation to improve
the discrimination capability of the non-model-based system. On the
other hand, a model-based system would not have to be trained on all
possible view orientations. Furthermore, the model-based system could
use the viewing orientation (either known or hypothesized) to
discriminate between the two objects. For example, the ratio of the
radii of the top and bottom disks spans a smaller interval for the
cylinder than for the cone. Also, the degree of antiparallelism of
the left and right sides is less pronounced for the cylinder than for
the cone. Given the viewing orientation, the model-based system can
predict a priori the degree of antiparallelism and the ratio
of the radii that it will expect to see.
. Both the top and bottom as well as
the left and right sides of the cylinder are parallel in view (a), and
the left and right sides of the cone are antiparallel. However, when
viewed from orientation (b), the left and right sides of the cylinder
have become antiparallel, making the cylinder indistinguishable from
the cone. In order to recognize these two objects, a non-model-based
vision system would have to be trained on all possible perspective
transformations of these two objects. Furthermore, it would be
difficult to take into account a known viewing orientation to improve
the discrimination capability of the non-model-based system. On the
other hand, a model-based system would not have to be trained on all
possible view orientations. Furthermore, the model-based system could
use the viewing orientation (either known or hypothesized) to
discriminate between the two objects. For example, the ratio of the
radii of the top and bottom disks spans a smaller interval for the
cylinder than for the cone. Also, the degree of antiparallelism of
the left and right sides is less pronounced for the cylinder than for
the cone. Given the viewing orientation, the model-based system can
predict a priori the degree of antiparallelism and the ratio
of the radii that it will expect to see.
A less-contrived example of the limitations of non-model-based vision is the correction of blurred photographic images. Image blurring can be caused by camera motion, object motion, lens defocusing, chromatic separation, and image sensor diffusion. Without a model of the image formation process, it is difficult to reduce the degree of blurring. However, if we know the properties of the lens, or the velocity of the objects, or the physics of the image sensing device, we can optimally correct for the blurring. Of course, the correction will still be limited by factors such as the signal-to-noise ratio of the image sensors and the quality of the lens. Furthermore, some blurring processes such as intensity saturation and image bleeding are mathematically or physically irreversible. The point is that for any given set of constraints, a model-based vision system will have a better object discriminating capability than a non-model-based system. Indeed, many current research projects in computer vision deal with the construction of better geometric and computational models for recognizing objects and scenes.
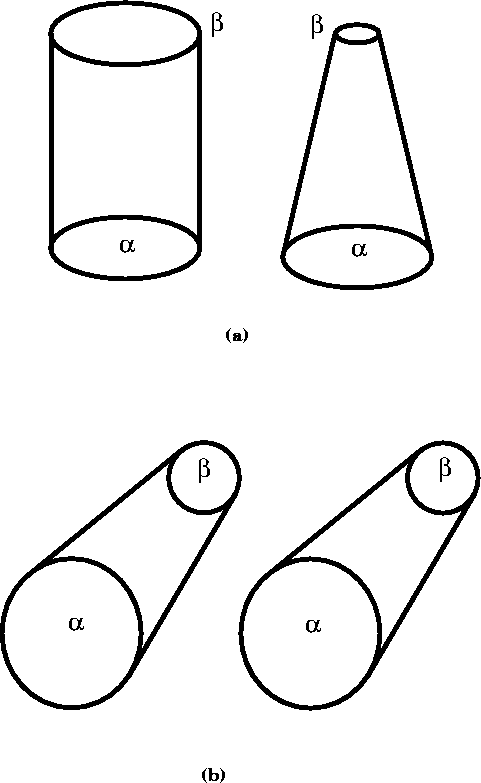
Figure: A cone and a cylinder (a) can have identical perspective
transformations when viewed at a particular orientation (b).