Fish4Knowledge Overview
One approach to acquiring biological data of insects, fish and animals in
their natural setting is to use embedded video cameras to observe the
presence and behaviour of the organisms. This presents three problems for
the biologists: 1) the quantities of acquired raw data can approach 1-2 gigabyte
per hour per camera, even with substantial compression,
2) extracting information from the data can require substantial
computer programming skills and 3) adapting the programs as scientific
questions evolve or new questions arise can be quite time-consuming.
These three problems sit at the heart of the motivations for the
Intelligent Information Management workprogram focus.
As a practical framework for focussing and integrating research into
issues of Intelligent Information Management,
this project will investigate methods for capture, storage, analysis
and query of multiple video streams of undersea environmental videos.
The video streams are being generated as part of an ecological monitoring
effort and also form a resource base for marine biologists.
The cameras (e.g. 10) generate on the order of 20 gigabytes per
hour of video data and, with 12+ hours of usable daylight, this
could lead to on the order of 100 terabytes of data per year.
This project will investigate methods for how a combination
of computer vision, semantic web, database storage and query
and workflow methods can be used to extract
useful information and make it accessible to non-programming scientists.
A typical image from one of the monitored areas is:

This marine monitoring scenario is an application framework that motivates and
unifies the scientific research of this project, and which will supply
the data for evaluation of that research.
Complicating the issue is the 3000 different species of fish that have been
observed in the area.
However, the core goal of the project is to investigate research issues,
in particular, into knowledge and data representation, database indexing,
flexible data processing workflow architectures, computer vision
based video analysis and query answering.
The real issue underlying the project is how to extract useful scientific
information from the enormous amount of data provided by the video cameras,
and, in fact, see if this enormous amount of data can actually allow marine
scientists to answer new sorts of scientific questions.
This point is made eloquently in the recent electronic
book "The Fourth Paradigm: Data-Intensive
Scientific Discovery", Tony Hey, Stewart Tansley, and Kristin Tolle (Eds),
online, 2009.
The book argues that the next wave of scientific development will be data-driven,
as contrasted with observation, theory or simulation driven,
and new tools are needed to enable this new wave.
While we are not addressing this big issue in general, we are
investigating tools that turn raw data into analysable, conceptual units
that can be accessed flexibly through a knowledge-driven user interface
and efficiently using high-performance computing resources.
And the goal is to provide this without requiring the target user scientist
(marine biologists here) to also be a programmer.
The particular questions that will be investigated are:
- What are the appropriate forms of ontologies and vocabularies that:
- describe organisms like the observed fish,
their behaviours, the environmental conditions seen in the videos?
- allow formulation of the questions that the marine biologists
are interested in?
- describe the video data itself?
- describe the computer algorithm capabilities and processing resources
available for use when question answering?
These ontologies and vocabularies include both
computer and human-level descriptions, and are the primary mechanism
to ensure that the different project components can interface with
a consistent understanding.
- What storage representations allow for:
- Massive reduction in stored data (e.g. only record the extracted
fish and a background frame, or perhaps only a description of each
fish and a single view of it)?
- Efficient indexing to fish images and segments within the videos?
- Effective re-analysis of previously acquired video data to
answer new scientific queries?
- What computer vision methods are most effective for describing
fish shape, appearance, movement and behaviour? What descriptions are
computable for the environmental conditions seen in the videos?
What machine learning methods are beneficial for discovering optimal
fish detection and categorisation.
- What are the most effective methods for accessing information
previously extracted from the videos, combining user text-based query terms,
computer vision based descriptions and a semantic ontology linking
the two?
How can the user generated queries be used to compile new workflow
sequences for extracting new information from the video data?
Does user feedback during database retrieval provide a benefit here?
- What computer processing structures will allow continuous capture,
analysis and storage of the video data without a backlog of unanalysed videos?
How might irrelevant information be removed and redundancy reduced to make the
recorded data tractable in size, and enable the possibility of increased
numbers of cameras in the future?
- How can the processing components be organised to allow
flexible real-time reconfiguration of the processing workflow, as users formulate
new scientific questions?
How can new scientific questions be quickly translated into new processing
workflows that extract the answers to the questions in a manner that
does not require the user to be a scientific programmer?
How can processing resources be redeployed between processing of
live versus pre-stored data processing?
- Which sorts of queries are most effectively answered, such as
fish and behaviour identification or counting? How generally can
we allow users to frame queries, e.g. using some sort of a logical
specification query language? What are the types of query primitives
that can be computed accurately?
To help answer the scientific questions listed above, we will
undertake research into: 1) computer vision methods (for fish detection,
species identification and behaviour recognition),
2) ontology driven semantic user interfaces (to allow non-programming
biologist users to specify queries about the video content),
3) ontology and planning driven automatic workflow construction (for on-line
automatic construction of computational sequences
that answer the biological questions) and 4) computer
hardware and software architecture organisations that can acquire
and process the massive amount of video data efficiently.
We will integrate the individual research components into a
publically usable demonstration system.
This system will allow a marine biologist to formulate a query
in his/her vocabulary (by the semantic interface),
which will be translated into a sequence of image processing
and database access operations (by the workflow compiler), which
are then executed using the database host and query execution machine.
One novel aspect of this project is the location where the data analysis
will take place. In the past, scientists downloaded the datasets or bought
copies on CDs/DVDs. With up to 10E+12 pieces of data, this is now impossible
for most projects. Even with new 1T portable disks, these databases would require
dozens, if not hundreds of drives. So, instead, this project takes the scientist's
questions to the data. In this case, this means the use of an intelligent
web-based user interface, which leads to queries over the database, executed on
a HPC computing system co-located with the data.
A schematic architecture for the integrated project and system can be seen here:
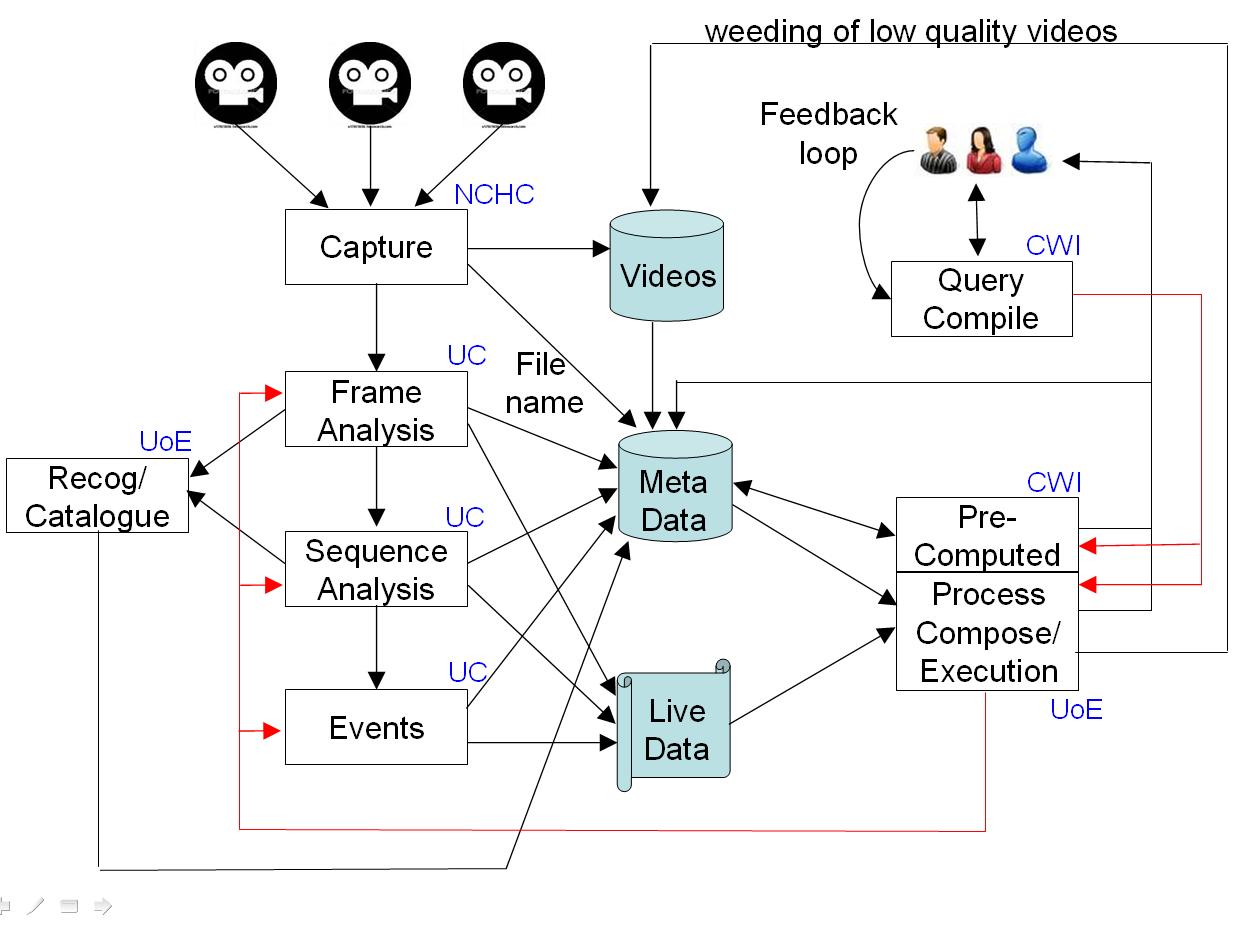
At the centre of the diagram are the three data repositories to be developed and
hosted by NCHC: a repository of previously recorded video data in a computationally
compressed format, a metadata repository of RDF triples recording
previously extracted information from the videos, plus an XML database
of the videos and associated summaries. The content producers for these
repositories are shown at the left side, where image data is captured from
multiple cameras, fish are detected and tracked in the video
(which will require coping with potential problems like: murky water,
algae on the lens, moving background plants and changing lighting conditions).
From the tracked fish, the project will develop processes for recognising
fish species and distribution, and for inferring interactions between individual fish.
The video data could be live or previously captured, depending on the
user requests. Partners UCATANIA and UEDIN will be responsible for the
image and video analysis research.
At the right of the diagram are mainly the user response processes.
A marine biologist will be able to phrase a broad range of fish-related queries
in a reasonably natural way, with the domain ontologies providing re-interpretation
into the system's vocabulary. The queries will lead to either previously
computed results being extracted from the RDF metadata store, or new results being
computed (which could involve a mixture of processing video data - either
previously captured or live - and previously extracted information).
The new results will be generated by workflows compiled `on-the-spot' from the
user query and image processing knowledge, using a set of domain, user, fish and
capability ontologies. Partners CWI and UEDIN are responsible for the
query, planning and workflow construction processes.
The workflows would then be executed on a flexible architecture,
which may involve more that one processor (NCHC is responsible for this).
An important workflow component is the database query engine.
For this project, we do not anticipate undertaking any research into
high-performance database query. Because of the quantity of the
data, we are planning for a distributed database and distributed subqueries
over that data. However, at the moment, we propose to use multiple distributed
instances of standard query engines, i.e. SPARQL for the RDF component,
XQuery for the XML component.
As part of the project, we will develop a public web-accessable database
of the videos and their associated computed descriptors (e.g. XML and RDF).
We will develop a web interface that will allow users anywhere to
access live or previously stored videos or compose queries about the
previously stored data.
Extensive performance experiments will be performed to provide statistics
on the accuracy, ease and speed of retrieval of information from the database.
Given a successful outcome, as well as producing new research results,
we will demonstrate a potential environmental analysis tool suitable
for answering questions like:
- What species and numbers of fish appeared in the last N days?
- What unrecognised fish were detected? Do they cluster by appearance?
- Show me examples of fish from species X?
- Show me examples of a fish with description X?
- What other species were also present when species X was seen?
- Are the observed numbers of species X increasing in the past 3 years?
While the focus of the project is based on very specific marine eco-system
video data and environmental study tasks, this has been selected as a
particular use case to demonstrate the more general techniques being
developed within the project. The strength of the project is not only in
going beyond the state of the art in the expertises of the different
partners, but in combining their strengths to form an end-to-end solution
- a thin bridge over the semantic gap.
As a whole, the research undertaken here is partially
applicable to other video-based monitoring applications, e.g.
video-based monitoring of the behaviour of farm and wild land-based animals,
people in shops, secure area surveillance, etc.
Furthermore, several of the core technologies being investigated and
developed here should have wider applicability, such as the knowledge
driven expert query interfaces, computational workflow compilation
from user task ontologies, hierarchical object recognition, target
detection and tracking in unfavourable image data, automatic workflow
distribution over multiple processors.
While we do not expect that the project results will generalise directly,
it is at least clear that the technologies listed just above address
research issues encountered in other applications.
|