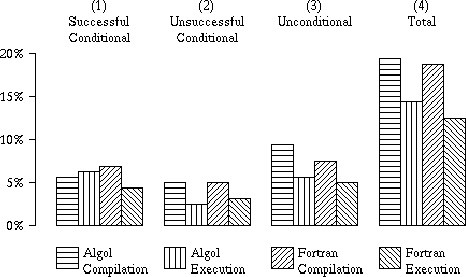
Figure 1 Percentages of Branches
Depending on the position of the Control Point, the pipeline can be described as early control, with the Control Point at an early stage in the pipeline (often the first), or late control, with the Control Point several stages further on. The position of the Control Point depends on a number of factors including the instruction set, hardware organisation, and the nature of program addresses (real or virtual, for example). Thus the parallelism of the functional units in machines like the CDC 6600 indicates an early Control Point, while the pre-processing required for an MU5 virtual address is easier to perform with a late control pipeline. Within these guidelines, there is a degree of flexibility in the position of the Control Point, and designers have to take other factors into consideration.
The effects of control transfers (branch instructions) are particularly important. Branch instructions can be divided into conditional branches, where the branch only occurs if some condition within the processor is satisfied, and unconditional branches, which always branch. Clearly, a conditional branch instruction may be successful or unsuccessful, depending on the state of the condition when it is executed, and the relative proportions of successful conditional, unsuccessful conditional, and unconditional branches are important to the performance of the instruction fetching strategy used in the processor.
Branch instructions are normally executed at the Control Point stage in the pipeline. Since branches are often followed down the pipeline by wrong sequences of instructions, the delay incurred when these instructions have to be discarded increases in proportion to the number of stages in the pipeline between the main store and the Control Point. A late control pipeline would therefore seem to imply long delays for branch instructions. However, a closer examination reveals a more complicated situation.
The decoding of any instruction in the pipeline normally takes place before the final execution of some preceding instructions. This produces an information gap, or Gulf of Ignorance, between instructions entering the pipeline and those completing execution. This particularly affects conditional branches, since their execution depends on a value or condition determined by some previous instruction, or, in the case of machines like the CDC 6600, by the branch instruction itself. If this value is calculated by an instruction within the Gulf of Ignorance, then the branch is unresolvable and cannot proceed until the required instruction completes execution. Resolvable branches are those which are unconditional or which depend on the outcome of a long-passed instruction, outside the Gulf of Ignorance.
Thus the proportion of branches that are resolvable is very important, as a resolvable branch can be obeyed as soon as it is decoded. Unresolvable branches must normally be held at the Control Point until the required condition or result has been evaluated, usually at, or near, the end of the pipeline in one of the arithmetic units, and a gap will occur in the flow of instructions through the pipeline. The length of this gap is determined by the number of pipeline stages between the Control Point and the later stage where the arithmetic is performed (It is this gap which the Conditional Mode of the IBM System/360 Model 195 is designed to overcome, in cases where the outcome of the conditional branch has been correctly predicted. When it has not the Instruction Address Register at the Control Point has to be wound back to take account of the instructions issued but not actually obeyed.)
Once the condition has been resolved, the branch can be obeyed. Unless the appropriate sequence is already following the branch down the pipeline, however, a further delay will be incurred while the new sequence of instructions is requested from store (or the instruction buffer). This delay will be equal to the instruction access time plus the time to pass through the pipeline from the store to the Control Point. Thus, for a conditional branch followed by the wrong sequence of instructions, the delay subsequently incurred depends on the numbers of pipeline stages both between the main store and the Control Point and between the Control Point and the arithmetic unit, that is, the total pipeline length. However, if the correct instruction sequence following the conditional branch has been supplied to the pipeline, then this delay is only proportional to the number of stages in the pipeline beyond the Control Point.
On at least some occasions conditional branch instructions will be followed by the correct sequence (when they are unsuccessful in a simple system), and in these cases the pipeline delays are reduced if the Control Point is as late as possible in the pipeline. In the absence of any special techniques for supplying correct instructions after unconditional branches, however, the pipeline delays for unconditional branches are reduced by placing the Control Point as early in the pipeline as possible. Clearly, the relative proportions of these instructions are important. Measurements made using the MU5 hardware performance monitor produced the results shown in Figure 1 for the proportions of different types of branch instruction obeyed during compilation and execution of 10 Algol and 15 FORTRAN benchmark programs [1].
Figure 1 Percentages of Branches
During Algol execution 14.0% of all instructions obeyed are branches, made up of 6.0% successful conditional, 2.4% unsuccessful conditional and 5.6% unconditional branches. For FORTRAN execution 12.5% of all instructions are branches, made up of 4.5% successful conditional, 2.8% unsuccessful conditional, and 5.2% unconditional branches. During both Algol and FORTRAN compilation the proportions of branches are higher, and the success rates of the conditional branches are lower. Both of these differences arise from the nature of the tasks. The execution figures include large numbers of loops of numerical calculations ended by successful conditional branches, while the data-dependent nature of the compilation task involves many unsuccessful tests for particular values of the input data.
The relative numbers of predictable and unpredictable branches are also important in MU5, since only predictable branches (those which use a literal (immediate) operand) cause a Jump Trace entry to be made following their first successful execution. The results in column 1 of Figure 2 show that the percentage of these predictable branches (including conditional and unconditional) is fairly constant at over 85% for all the types of program considered.
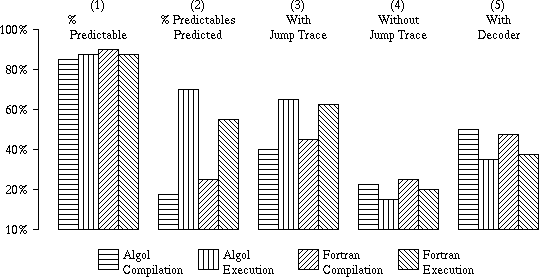
Figure 2 Branch Prediction Rates
Column 2 of Figure 2 shows the proportion of predictable branches that are correctly predicted by the Jump Trace. The figures for execution are much better than for compilation, and again the nature of the tasks accounts for this difference. During execution, the Jump Trace appears to offer less advantage for FORTRAN than Algol programs, even though many of the benchmarks actually correspond to the same task carried out in each language. When the percentages of branches followed by correct sequences of instructions are considered, however, as in column 3, the lower success rate of conditional branches in FORTRAN compensates for this effect. The figures in column 3 may be compared with those in column 4, which shows the percentages of branches what would be followed by correct sequences in the absence of the Jump Trace.
An alternative system that might seem to produce useful improvements in the numbers of correct sequences is one that decodes and executes predictable unconditional branches at an earlier stage in the pipeline than the Control Point. Such a scheme was used in some of the more powerful machines in the ICL 2900 series of computers. Using MU5 figures for the numbers of unsuccessful conditional branches and the predictable unconditional branches, the percentages of branches followed by correct sequences using the decoder scheme alone, would be as shown in column 5 of Figure 2. The effects for compilation are remarkably similar to those obtained using the Jump Trace, though clearly for execution this scheme is less attractive. Furthermore, large gaps will occur in the pipeline unless the decoding and execution of an unconditional branch occurs sufficiently far in advance of the Control Point for the new sequence to be accessed from store and supplied to the pipeline before the preceding instructions have all been processed.
A further set of measurements taken from MU5 concerns resolvability. Conditional branches in MU5 depend on the outcome of a previously executed COMPARE order, the result of which is held in a separate Test Register, and measurements of the numbers of conditional branches separated by a given number of instructions from the preceding COMPARE order were used to determine the percentages of conditional branches that would be resolvable for a given pipeline length (Figure 3). For a pipeline separation of more than one stage between the Control Point and the arithmetic unit carrying out the comparison, most conditional branches are unresolvable, even though the MU5 compiler writers attempted to separate comparison and branch orders wherever possible in the compiled code. If all conditional branches are assumed to be unresolvable in MU5, their proportion of the total number of branches amounts to very close to 60% for each type of program considered. This figure agrees very closely with that obtained by Flynn from measurements taken from an IBM System/360 machine [2]. Flynn found the overall proportion of branches to be higher, at 9% resolvable and 16.5% unresolvable (27.5% in all), but the proportion of branches which were unresolvable was also 60%.
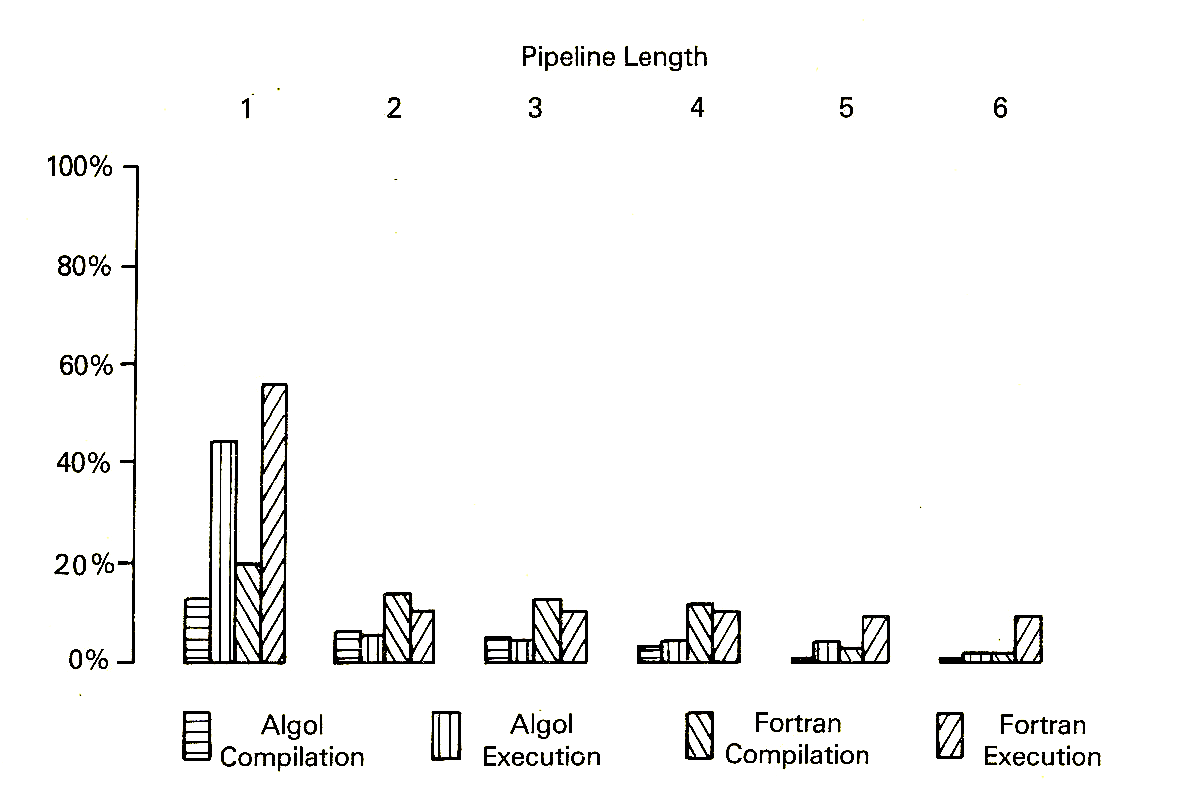
Figure 3 Percentages of Resolvable Branches
The performance of pipelined processors is critically dependent on the effects of branches. What is important is the total length of the pipeline, and simply designing for greater overlap within a processor will not necessarily improve performance. For a given pipeline length, however, performance can be improved by placing the Control Point as late as possible in the pipeline and supplying the pipeline with the correct sequence of instructions after control branches as frequently as possible. This necessarily involves the prediction of the outcome of a branch, and this must normally be made as early as possible in order to overcome store access delays. A system such as the MU5 Jump Trace, which bases its prediction on the addresses used to pre-fetch instructions, seems to offer the best chance of success in this situation. A number of commercial systems now use a similar mechanism, one of the earliest being the IBM 3090 [3]. Here "a decode-history-table scheme is used, in which a table keeps the history of branches. Just as past references are used to predict the data that should be kept in a cache, so past branching results can be used to predict future branch behaviour. The location of the branch is used to reference the table, and, if the table indicates that the last branch was successful, the current branch is predicted to be successful.".