Figure 1
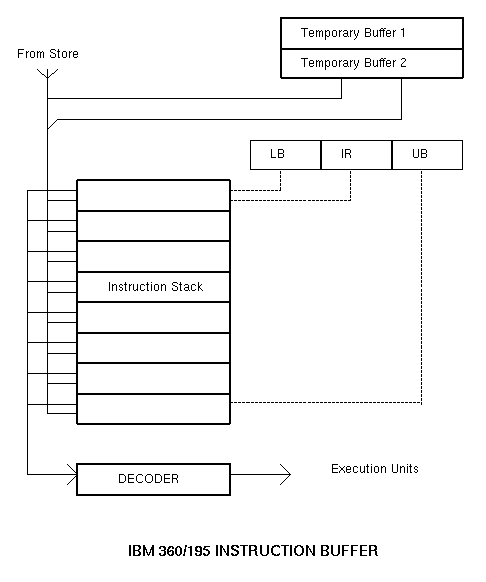
Instructions fetched from store are buffered in an eight-doubleword (64-bit) Instruction Stack (see Figure 1). The instruction fetching mechanism is controlled by three registers: the Instruction Register (IR) which addresses the instruction currently being decoded, the Upper Bound Register (UB) which points to the most recent doubleword brought into the stack, and the Lower Bound Register (LB) which points to the earliest doubleword in the stack. During normal operation the stack contains the current instruction doubleword, some doublewords ahead of the current instruction and a copy of some instructions which have already been issued.
Figure 1
Once the first instruction access has been sent to store, the instruction fetching mechanism increments UB and continues to make sequential store accesses until prevented from doing so either because the address in UB is seven doublewords higher than that in IR (and any further accesses would cause instructions not yet decoded to be overwritten), or because the Instruction Processor has detected a condition giving rise to a change in the instruction sequence (a branch instruction or an interrupt, for example).
During normal operation the instruction fetching mechanism continually attempts to increment UB and fetch instruction doublewords from store, while the instruction decoding mechanism continually increments IR as instructions are decoded and passed along the processor pipeline. Once IR has been incremented beyond the address in LB, instructions in the first doubleword fetched into the stack can be overwritten with new information. Provided IR remains ahead of LB, then when incrementing UB would cause its three least significant doubleword address bits to match the corresponding bits in LB, both these registers are incremented together. Thus at each instruction access the oldest doubleword in the stack is replaced by the latest doubleword fetched from store.
Use of this pre-fetching mechanism allows a continuous sequence of instructions to be supplied to the processor at a rate approaching one per machine clock cycle, and thus roughly matching the instruction execution rate (Although the processor pipeline was designed to execute instructions at a rate of one per clock cycle, instruction dependencies, storage conflicts and the frequency of operations requiring multi-cycle execution combine to reduce the average rate to about half this figure.) When a new sequence of instructions is required as a result of the branch being taken in a branch instruction, however, the start-up delay is of the order of six clock cycles, and in the absence of some additional technique the average performance of the processor would be seriously degraded. Conditional branches cause even further problems since the branch decision depends on the outcome of a previously issued, but not necessarily completed arithmetic instruction, and an additional delay may be incurred in awaiting this outcome. This problem is discussed further in Position of the Control Point. In the Model 195 two techniques are used to ameliorate the problems caused by branches, one involving the establishment of a Conditional Mode of operation, and the other a Loop Mode.
Since in general the Condition Code will not be valid when a conditional branch is decoded, the hardware always assumes this to be the case and establishes Conditional Mode. In Conditional Mode further sequential instruction accesses are inhibited, but rather than hold up further activity entirely, processing of the remaining instructions in the Instruction Stack proceeds as far as possible (until a further branch is decoded or the pipeline becomes full, for example), with the instructions being marked as conditional. Conditional instructions are decoded, their operand fetches are initiated, and they are forwarded to the relevant execution units in the normal way. The conditional tag inhibits the execution units from actually completing them, however, and once the first such instruction reaches the point of execution, further processing is held up until the Condition Code is set and the branching action determined. If the branch is not taken, the conditional tags are re-set and the pipeline is re-started without further delay.
If the branch is taken, the conditional instructions must be abandoned and a fresh start made with a new sequence. The delay incurred in refilling the pipeline from the decoder onwards is unavoidable, but the delay in accessing the first instruction at the target address of the new sequence is minimised in the Model 195 because the hardware assumes at the start of Conditional Mode that either outcome is equally likely and fetches the first two instruction doublewords at the branch target address immediately. These two doublewords are loaded into the two Temporary Buffers shown in Figure 1, in order that the Instruction Stack remain unaffected if the branch is not taken. Clearly these instruction fetches will have been made unnecessarily on many occasions, and since instruction accesses have priority over operand accesses on the store address path, some performance degradation can occur due to interference with operand accesses for the conditional instructions. This disadvantage is more than offset, however, by the advantage gained, when the branch does occur, of the access time for the target instructions having been overlapped with the wait for the Condition Code. In the case of an unconditional branch to an instruction not in the Instruction Stack, there is, of course, no need to wait for the Condition Code to become valid. As in the conditional case, the target instruction sequence is requested immediately, but unless the execution unit pipelines are also held up (as a result of divide operations, for example) the six clock cycle start-up delay inevitably causes a gap to occur in the instruction processing sequence.
The primary purpose of the whole conditional philosophy was the circumvention of storage delays, and in retrospect the designers felt that the complications of the system, which involve numerous interlocks throughout the processor, would become increasingly difficult to justify as storage access times decrease.
Loop Mode is entered whenever a branch backwards is taken to a target address within eight doublewords of the current instruction. The Instruction Stack is immediately re-initialised to contain the appropriate eight doublewords, after which instruction fetching ceases and the address path to store is fully available for operand fetching throughout execution of the loop. Loop Mode is controlled by two additional registers, one containing the loop target address (SLT) and the other the value of IR corresponding to the loop closing instruction (SLCIR). Once in Loop Mode the address of any branch instruction being decoded is compared with that in SLCIR, and if it is the same the branch is made immediately to the target address held in SLT. Thus the rôle of Conditional Mode is reversed, since it is assumed that the branch will be taken, and instructions are therefore decoded from the target path rather than the straight-through path. Furthermore, no fetches are made to the Temporary Buffers in Loop Mode.
Loop Mode is normally turned off because an exit is taken from the loop. This can happen in a variety of ways. If the branch closing the loop is not taken, for example, IR will run off the end of the instructions held in the stack and require a store access. Alternatively some other branch within the loop may be taken to a target outside the stack, or the address in SLCIR may be invalidated. This can happen if the base or index register specified in the instruction which caused SLCIR to be set up is altered. A record of these registers is kept with SLCIR and a check made against this record if any instruction in the loop alters a fixed-point register.