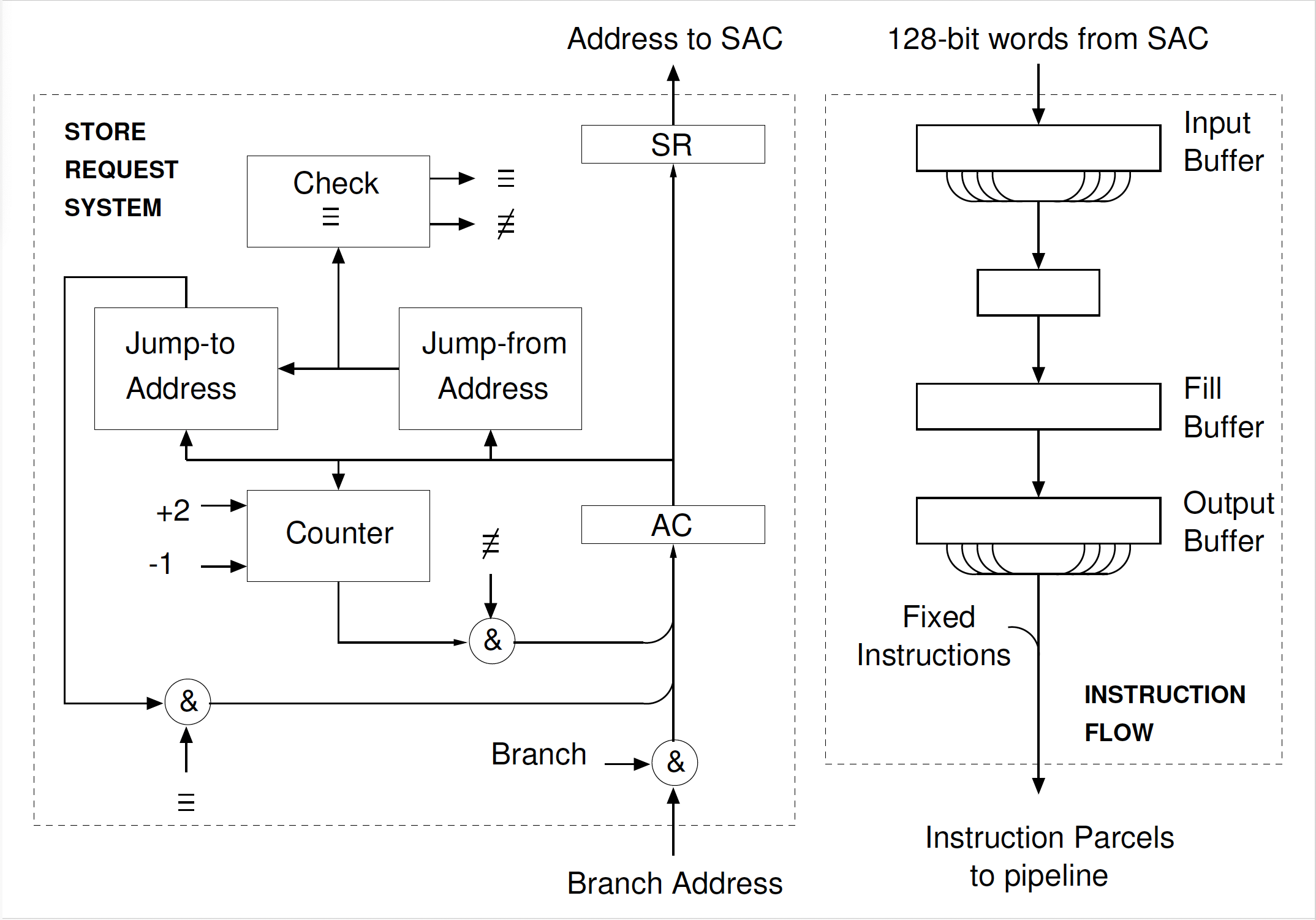
Figure 1 The MU5 Instruction Buffer Unit
Figure 1 The MU5 Instruction Buffer Unit
This system operates (the remainder of this section is written in the present tense) satisfactorily until a control transfer occurs as a result of either an unconditional control transfer instruction, or a conditional control transfer instruction for which the condition is met. Then all the pre-fetched instructions must be abandoned, and the correct new instruction cannot be sent to PROP until the store has been accessed, using the new control address, and the instruction has passed through the Data Flow. As a result the total time between the execution of the control transfer and the first instruction of a new sequence is 950 ns.
Measurements made during the execution of a number of benchmark programs run on MU5 showed that control transfers constitute around 13 per cent of obeyed instructions [1]. Thus without some attempt being made to overcome the effects of these control transfers, the average instruction execution time would be
which represents a reduction by a factor of over three from the peak execution rate.
A system was initially considered which had buffer registers containing the first few instructions at the destination or jump-to addresses of recently obeyed control transfers. Access to these instructions was to have been via an associative search on their addresses. The pre-fetching mechanism would proceed normally until a control transfer occurred, and the destination address would then be presented to the associative store. If a match was found, the instructions in the corresponding buffer register would be read out and sent to the Primary Operand Unit (PROP). If no match was found, one of the set of associative and buffer registers would be updated when the instructions had been obtained from store.
Simulation studies of this technique showed that only eight lines of store would be needed to trap 80 per cent of jump instructions and that increasing the number of lines to sixteen would only produce an extra 1 per cent improvement. The problem in implementing this scheme was the width of the buffer store. In order to allow the pre-fetching mechanism to catch up after a control transfer, each line of the buffer would need to hold up to 950 ns worth of instructions. At 50 ns per 16-bit instruction the number of bits needed in each line would have amounted to over 300.
In order to retain the advantage obtained by using an associatively addressed store, without incurring the cost of buffering large amounts of data, the system actually used in the MU5 Instruction Buffer Unit (IBU) includes an eight-line associatively addressed Jump Trace store which attempts to predict the outcome of an impending control transfer. Whenever a new instruction address is generated by the IBU it is presented to the associative jump-from address store before being sent to the Local Store via the Store Access Control Unit (SAC). If an equivalence is found, this address is replaced by the corresponding jump-to address, so that pre-fetching of the new sequence takes place instead. When the control transfer instruction which gave equivalence in the trace is sent to PROP, it is accompanied by a bit indicating that the instructions following it are out of sequence. This bit is used in PROP to determine the action after execution of the control transfer. If the following instructions have been correctly predicted, execution of instructions continues uninterrupted. If the instructions are not out of sequence, but should have been, a request is made to SAC for the instructions at the jump-to address, and at the same time a line in the Jump Trace is loaded with the jump-from and jump-to addresses (This line is selected using a cyclic replacement algorithm and as each line is overwritten a use digit associated with it is set. The use digits are normally only re-set, and the Trace thereby cleared, at a process change.) Thus when the jump-from address re-occurs within the IBU, the instructions at the jump-to address are automatically pre-fetched.
Simulation studies of this system indicated that about 75 per cent of control transfers could be trapped using an eight-line store, and that, as before, increasing the number of lines in the store did not significantly improve the performance. The apparent drop in performance as compared with the first system considered occurs because the prediction mechanism sometimes predicts a transfer which does not occur. No attempt is made to correct the Jump Trace when a predicted branch does not occur, however, since the drop in performance is more than offset by the fact that the prediction mechanism allows useful overlapping of instructions to continue in PROP when the prediction is correct.
Ordinary requests normally continue to be made until an instruction sequence discontinuity arises. This happens when an interrupt occurs, for example, or when the IBU has sent an incorrect sequence of instructions to PROP. This can occur either because an unpredicted control transfer instruction causes a jump, or because a predicted control transfer does not cause a jump. In either of these cases the priority mechanism is re-invoked when the address of the required instruction is sent from PROP. In the case of an interrupt two fixed (hard-wired) instructions are read from within the IBU. The first of these preserves essential linking information in store and the second causes a control transfer to the start of the appropriate interrupt routine. This again invokes the IBU priority mechanism.
The operation of the Store Request System can also be temporarily halted as a result of interlocks incorporated into the IBU to ensure that no loss of information occurs as a result of asynchronous operation. These interlocks simply cause time delays before the next ordinary request can be sent. For example, the rate of issuing of requests from the IBU to SAC is normally geared to the maximum rate at which PROP can process instructions. When PROP executes an instruction which requires a long interval of time for its completion, however, a hold-up occurs and this hold-up propagates back through PROP to the IBU Instruction Flow section. Since the IBU is obliged to accept instructions from SAC as soon as they becomes available, sufficient space must be maintained in these buffers to receive them. In order to meet this condition and to be able to maintain the maximum throughput rate, IBU ordinary requests may be held up within SAC until the IBU can guarantee to accept the requested instructions.
A further problem arises from the variable instruction length. The Control Register always addresses the first parcel of a multi-length instruction, but clearly jump-from addresses must always correspond to the last. This address must therefore be computed specially, since it is not otherwise required (This complication could be seen as one argument in favour of RISC architectures.) In MU5 the value in the Control Register after the execution of a conditional control transfer is either the address of the first parcel of the next instruction in sequence (the jump-from address + 1), or some quite different address (the jump-to address). The first alternative can be generated immediately, since it requires no operand, whereas the second must await the arrival of the operand and the result of the condition. The Control Adder associated with the Control Register in PROP can therefore perform two cycles with no loss of performance, and when an unpredicted control transfer using a literal operand occurs, both values are sent to the IBU. The first is loaded into register AC and then decremented by the address counter before being used to load a line in the jump-from field. The second is loaded into AC and thence into the jump-to field and also into SR to be sent to SAC as a priority request.