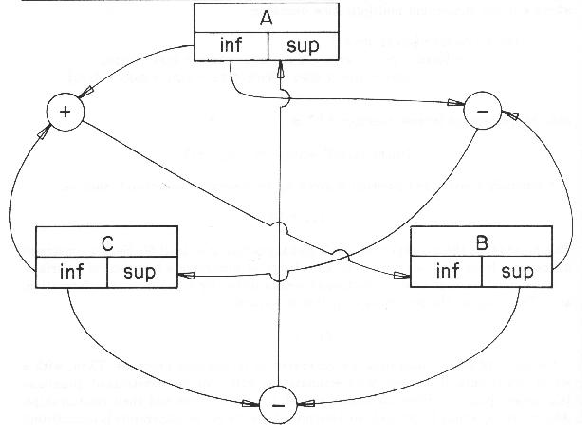
Position errors result from two causes - errors in the input data and deficiencies in the position estimation algorithms. To help remove the second source, Fisher and Orr [74] developed a network technique based on the algebraic method used in ACRONYM. The technique implements the constraint relationships as a value-passing network that results in tighter bounds and improved efficiency. Moreover, we observed that the forms of the algebraic constraints tended to be few and repeated often, and hence standard subnetwork modules could be developed, with instances allocated as new position constraints were identified. Examples of these network modules are: "a model vector is transformed to a data vector" and "a data point must lie near a transformed model point".
There are three aspects to the new network-based geometric reasoner:
The key data type is the position, which represents the relative spatial
relationship between two features (e.g. world-to-camera, camera-to-model,
or model-to-subcomponent).
A position consists of a 3-vector representing relative translation and
a unit 4-vector quaternion representing relative orientation
(of the form
![]() for a rotation
of
for a rotation
of ![]() about the axis
about the axis ![]() ).
).
The key geometric relationships concern relative position and have
two forms: exact and partially constrained.
An example of an exact form is: let object A be at global position
![]() , (translation
, (translation ![]() and
rotation
and
rotation ![]() ) and object B be at
) and object B be at
![]() relative to A.
Then, the global position of B is:
relative to A.
Then, the global position of B is:
where ![]() is the quaternion multiplication operator:
is the quaternion multiplication operator:
and the quaternion inverse operator " ![]() " is:
" is:
A partially constrained position is given by an inequality constraint, such as:
Other relationships concern vectors or points linked by a common
transformation, as in
![]() , or the proximity of points or vectors:
, or the proximity of points or vectors:
Instances of these constraints are generated as recognition proceeds. Then, with a set of constraints, it is possible to estimate the values of the constrained quantities (e.g. object position) from the known model, the data values and their relationships. Alternatively, it may be possible to determine that the set of constraints is inconsistent (i.e. the set of constraints has no solution), and then the hypothesis is rejected.
A key complication is that each data measurement may have some error or uncertainty, and hence the estimated values may also have these. Alternatively, a variable may be only partially constrained in the model or a priori scene information. Hence, each numerical quantity is represented by an interval [7]. Then, following ACRONYM with some extensions, all constraints are represented as inequalities, providing either upper or lower bounds on all quantities.
We now look at how the constraints are evaluated.
ACRONYM used a symbolic algebra technique to estimate upper (SUP) and lower
(INF) bounds on all quantities.
When bounds cross, i.e.
![]() , then inconsistency was
declared and the hypothesis rejected.
This symbolic algebra method was slow and did not always give tight bounds.
, then inconsistency was
declared and the hypothesis rejected.
This symbolic algebra method was slow and did not always give tight bounds.
The basis of the network approach is the propagation of updated bounds, through
functional units linked according to the algebraic problem specification.
A simple example is based on the inequality:
as are the lower bounds of B and C:
There are two advantages to the network structure. First, because values propagate, local improvements in estimates propagate to help constrain other values elsewhere. Hence, even though we still have rectangular interval parameter space bounds, the constraints are non-rectangular and thus can link changes in one variable to others. Even for just local problems, continued propagation until convergence produces better results than the symbolic methods of ACRONYM. Second, these networks have a natural wide-scale parallel structure (e.g. 1000+) that might eventually lead to extremely fast network evaluation in VLSI (e.g. 10-100 microseconds). One disadvantage of the network approach is that standard bounding relationships must be pre-computed as the network is compiled, whereas the symbolic approach can be opportunistic when a fortuitous set of constraints is encountered.
For a given problem, the networks can be complicated, particularly since there may be both exact and heuristic bounding relationships. For example, the network expressing the reference frame transformation between three positions contains about 2000 function nodes (of types "+", "-", "*", "/", "sqrt", "max", "greaterthan", "if" etc.). The evaluation of a network is fast, even in serial, because small changes are truncated to prevent trivial propagations, unlike other constraint propagation approaches (see [53]). Convergence is guaranteed (or inconsistency detected) because bounds can only tighten (or cross), since only sufficiently large changes are propagated.
The creation of the networks is time-consuming, requiring a symbolic analysis of the algebraic inequalities. Fortunately, there is a natural modular structure arising from the types of problems encountered during scene analysis, where most geometric constraints are of a few common types. Hence, it is possible to pre-compile network modules for each relationship, and merely allocate a new instance of the module into the network as scene analysis proceeds. To date, we have identified and implemented network modules for:
One important feature of these modules is that they are bi-directional,
in that each variable partially constrains all other related variables.
Hence, this method is usable for expressing partial constraints (such
as "the object is above the table" or ![]() ).
The constraints on other related variables can then help fully
constrain unbound or partially constrained variables.
).
The constraints on other related variables can then help fully
constrain unbound or partially constrained variables.
We now include a simple and a complicated example of network use.
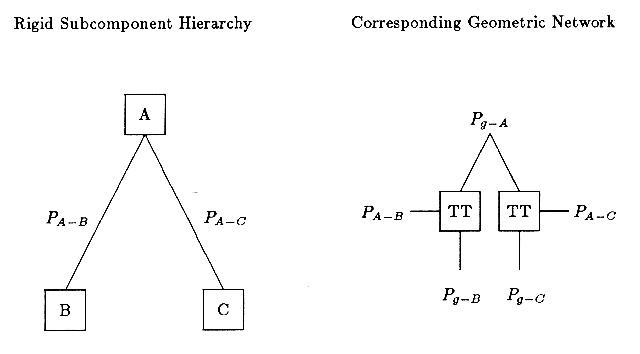
Suppose subcomponents B and C are rigidly connected to form object A.
With the estimated positions of the subcomponents in the global coordinate
system, ![]() and
and ![]() , and the transformations between the
object and local coordinate systems,
, and the transformations between the
object and local coordinate systems, ![]() and
and ![]() , then
these can be used to estimate the global object position,
, then
these can be used to estimate the global object position, ![]() , by using
two instances of the "TT" module listed above.
Figure 9.10 shows this network.
Notice that each subcomponent gives an independent estimate of
, by using
two instances of the "TT" module listed above.
Figure 9.10 shows this network.
Notice that each subcomponent gives an independent estimate of ![]() ,
so that the network keeps the tightest bounds on each component of the position.
Any tighter resulting bounds then propagate back through the modules to refine
the subcomponent position estimates.
,
so that the network keeps the tightest bounds on each component of the position.
Any tighter resulting bounds then propagate back through the modules to refine
the subcomponent position estimates.
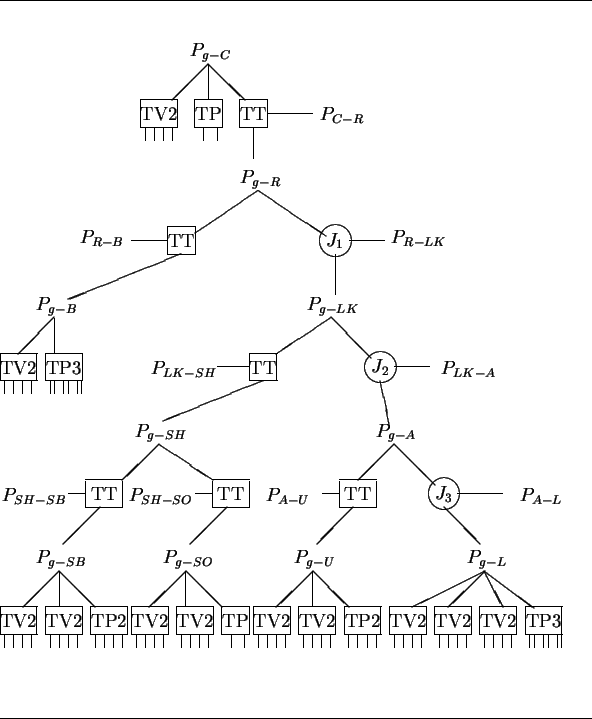
Figure 9.11 shows the full network generated for analyzing
the robot in the test scene.
As before, the boxes represent transformations, but there are more types used
here.
The "TP![]() " boxes stand for
" boxes stand for ![]() instances of a "TP" module.
The circular "
instances of a "TP" module.
The circular "![]() " boxes represent three identical instances of subnetworks
allocated for transformations involving joint angles, which are
omitted to simplify the diagram (each contains 7 network modules).
The relative positions of objects are given by the
" boxes represent three identical instances of subnetworks
allocated for transformations involving joint angles, which are
omitted to simplify the diagram (each contains 7 network modules).
The relative positions of objects are given by the ![]() structures, such
as
structures, such
as ![]() , which represents the position of the robot in the global
reference frame.
These are linked by the various transformations.
Links to model or data vectors or points are represented by the unconnected
segments exiting from some boxes.
, which represents the position of the robot in the global
reference frame.
These are linked by the various transformations.
Links to model or data vectors or points are represented by the unconnected
segments exiting from some boxes.
The top position ![]() is the position of the camera in the global
coordinate system, and the subnetwork to the left and below relates features
in the camera frame to corresponding ones in the global coordinate system.
Below that is the position
is the position of the camera in the global
coordinate system, and the subnetwork to the left and below relates features
in the camera frame to corresponding ones in the global coordinate system.
Below that is the position ![]() of the robot in the global coordinate
system and the position
of the robot in the global coordinate
system and the position ![]() of the robot in the camera coordinate
system, all linked by a TT position transformation module.
Next, to the bottom left is the subnetwork for the cylindrical robot body
of the robot in the camera coordinate
system, all linked by a TT position transformation module.
Next, to the bottom left is the subnetwork for the cylindrical robot body
![]() .
The "
.
The "![]() " node connects the robot position to the rest
("link") on the right, whose position is
" node connects the robot position to the rest
("link") on the right, whose position is ![]() .
Its left subcomponent is the rigid shoulder ASSEMBLY (SH) with its
subcomponents, the shoulder body (SB) and the small shoulder patch (SO).
To the right, the "
.
Its left subcomponent is the rigid shoulder ASSEMBLY (SH) with its
subcomponents, the shoulder body (SB) and the small shoulder patch (SO).
To the right, the "![]() " node connects to the "armasm" ASSEMBLY (A),
linking the upper arm (U) to the lower arm (L), again via another joint
angle ("
" node connects to the "armasm" ASSEMBLY (A),
linking the upper arm (U) to the lower arm (L), again via another joint
angle ("![]() ").
At the bottom are the modules that link model vectors and points to observed
surface normals, cylindrical axis vectors, and central points, etc.
Altogether, there are 61 network modules containing about 96,000 function
nodes.
").
At the bottom are the modules that link model vectors and points to observed
surface normals, cylindrical axis vectors, and central points, etc.
Altogether, there are 61 network modules containing about 96,000 function
nodes.
The network structure closely resembles the model subcomponent hierarchy, and only the bottom level is data-dependent. There, new nodes are added whenever new model-to-data pairings are made, producing new constraints on feature positions.
Evaluating the complete network from the raw data requires about 1,000,000 node evaluations in 800 "clock-periods" (thus implying over 1000-way parallelism). Given the simplicity of operations in a node evaluation, a future machine should be able to support easily a 1 microsecond cycle time. This suggests that an approximate answer to this complicated problem could be achieved in about 1 millisecond.
As the tolerances on the data errors propagate through the network
modules, they do not always produce tight result intervals, though some
interval reduction is achieved by integrating separate estimates.
For example, if each orientation component of a random position ![]() has interval width (i.e. error)
has interval width (i.e. error) ![]() and each orientation component of a random position
and each orientation component of a random position
![]() has interval width
has interval width ![]() , then each component of the resulting position
, then each component of the resulting position
![]() has interval width:
has interval width:
Because the resulting intervals are not tight, confidence that the mean interval value is the best estimate is reduced, though the bounds are correct and the mean interval values provide useful position estimates. To tighten estimates, a post-processing phase iteratively shrinks the bounds on a selected interval and lets the new bounds propagate through the network. For the robot example, this required an additional 12,000 cycles, implying a total solution time of about 13 milliseconds on our hypothetical parallel machine.
Using the new geometric reasoning network, the
numerical results for the whole robot in the test scene are summarized
in Table 9.10.
Here, the values are given in the global reference frame rather than in the
camera reference frame.
| PARAMETER | MEASURED | ESTIMATED |
|---|---|---|
| X | 488 (cm) | 487 (cm) |
| Y | 89 (cm) | 87 (cm) |
| Z | 554 (cm) | 550 (cm) |
| Rotation | 0.0 (rad) | 0.038 (rad) |
| Slant | 0.793 (rad) | 0.702(rad) |
| Tilt | 3.14 (rad) | 2.97 (rad) |
| Joint 1 | 2.24 (rad) | 2.21 (rad) |
| Joint 2 | 2.82 (rad) | 2.88 (rad) |
| Joint 3 | 4.94 (rad) | 4.57 (rad) |
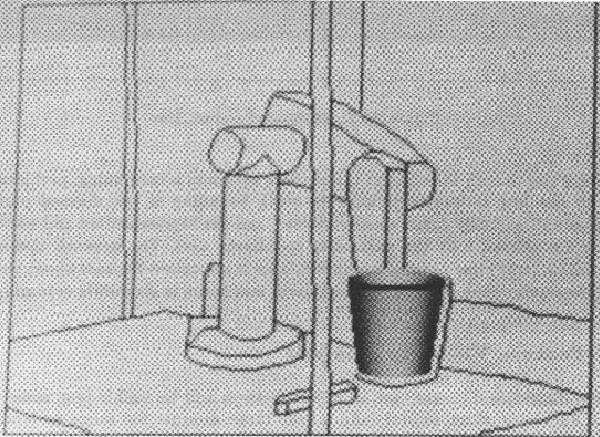
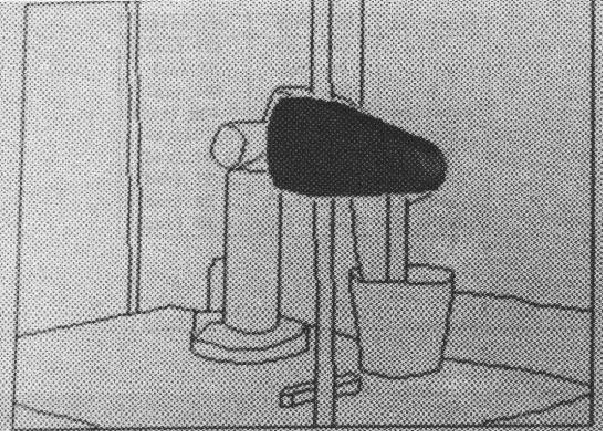
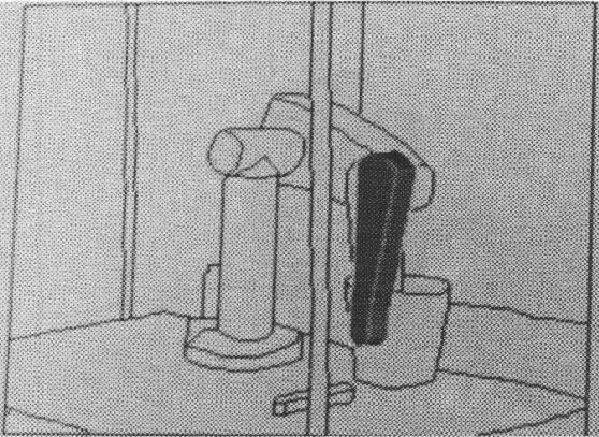
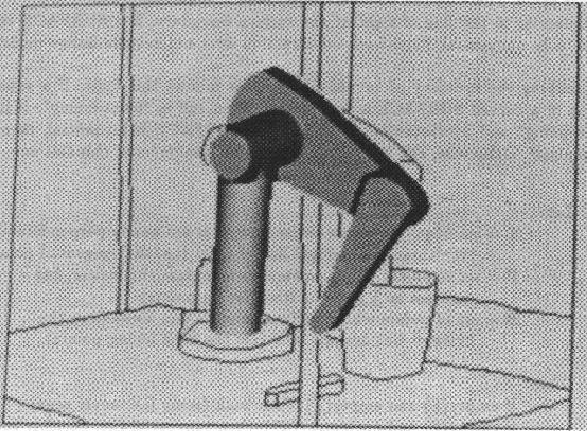
The results of the position estimation can been seen more clearly if we look at some figures showing the estimated object positions overlaying the original scene. Figure 9.12 shows the estimated position of the trash can is nearly correct. The robot upper arm (Figure 9.13) and lower arm (Figure 9.14) are also close. When we join these two to form the armasm ASSEMBLY (Figure 1.10), the results are still reasonable, but by the time we get to the whole robot (Figure 9.15), the accumulated errors in the position and joint angle estimates cause the predicted position of the gripper to drift somewhat from the true position (when using the single pass at network convergence). The iterative bounds tightening procedure described above then produces the slightly better result shown in Figure 1.11. Note, however, that both network methods produced improved position results over that of the original IMAGINE I method, which is shown in Figure 9.16.
Though research on the efficient use of these networks is continuing, problems overcome by the new technique include the weak bounding of transformed parameter estimates and partially constrained variables, and the representation and use of constraints not aligned with the parameter coordinate axes. The network also has the potential for large scale parallel evaluation. This is important because about one-third of the processing time in these scene analyses was spent in geometric reasoning.