Once a correspondence between landmark reference-views and visual prediction has been established, the texture values in the reference-views can be mapped to the virtual view. It is proposed to apply projective texture mapping in an adaptive way, in order to take advantage of multiple reference-views of landmarks, (from different positions), depending on the current robot pose.
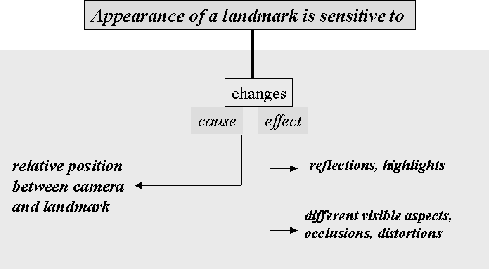
The basic concept is that the appearance of an object in the camera image-plane strongly depends on relative position between camera and object, and on present light conditions. In particular, different views of an object may reveal different visible aspects, (e.g. disocculsions), and local illumination effects, (e.g. shadows, reflections, highlights, etc.). Figure 4 summarizes the main factors affecting appearance of objects when observed from different viewpoints.
 |
But, how should texture values of different reference-views contribute when transfered to the same pixel in the virtual view?
In some of the literature works related to realistic visualization the issue of blending multiple images have been addressed, and it has been demonstrated the advantage of considering more than one reference texture when generating texture on a virtual view.
Different techniques have been proposed for blending texture values relative to different views. Among them, simple weighting functions based on the angle of the camera to the object, to more sophisticated post-rendering calculations, (Mark et al [18]). In case a geometric model is available for the represented objects, (even if this is a coarse model), textures could efficiently be mapped by a view-dependent projective mapping as shown in Debevec, Yu and Borshukov [8]. In Debevec, Taylor and Malik [7] it is shown that such a mapping could also be exploited to refine the geometric model of an object by a technique named: model-based stereo.
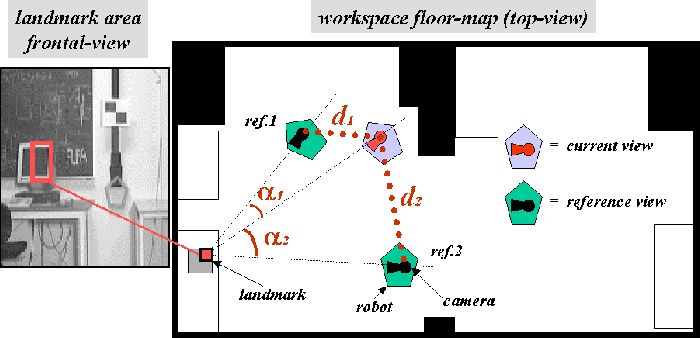
In case of Livatino [14], it is proposed to merge two o more landmark reference views into a composite rendering, combining texture values of correspondent pixels in different reference views. In particular, the system calculates a weighted average where involved textures provide a different contribution. Images from reference views which are closer to current viewpoint are expected to better approximate the current view than a reference-view further away. Closer images are in fact expected to best approximate landmark visible aspects and local illumination effects present in current camera observation.
Figure 6 shows an example situation which can also be
referred to the landmark of figure 5 (a portion of the computer
monitor).
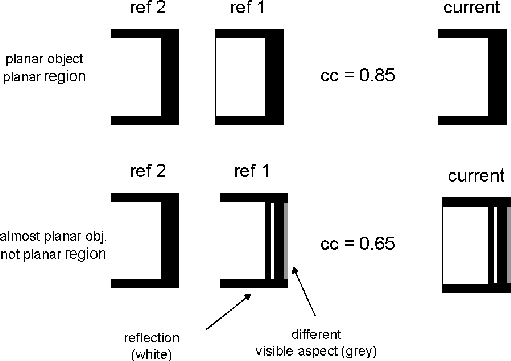
In case of a planar object with a planar neighbor region, it is not that
relevant which reference view should provide a higher contribution
when estimating the texture of the current view.
In case of an "almost" planar object with a not planar neighbor
region (as the case of the monitor), the closest reference view
(![]() in figure 5) should provide the higher contribution.
In fact, the closest view contains reflections,
visible aspects, etc., which could have not been shown in the farer
reference view (
in figure 5) should provide the higher contribution.
In fact, the closest view contains reflections,
visible aspects, etc., which could have not been shown in the farer
reference view (![]() ).
).
In particular, it is proposed to calculate a weighted average where involved textures provide a different contribution which depends on:
 |
 |
The reference view which is closer to current viewpoint in "angle" and
in "distance" will thus give a higher contribution in the final summation.
In case of two reference views, the resulting texture value for a
pixel, ![]() , would then be calculated as in the following:
, would then be calculated as in the following:
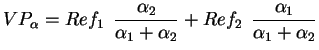 |
(7) |
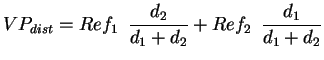 |
(8) |
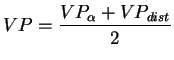 |
(9) |
The above equations can naturally be extended to the case of more than two reference views.
Merging reference-views based only on the above criteria can cause visible seams in the landmark visual prediction due to specularity, and unmodeled geometric detail may arise when neighboring textures comes from different reference-images and in case of occlusions or "disocclusions". Some of the techniques proposed in the literature for calculating texture transitions between different mapped views could then be applied to cope with the problem.
In the context of robot navigation as proposed in (Livatino [14]), the main reasons for proposing view-adapted texture mapping can be summarized in: