Conference/Journal
2022
-
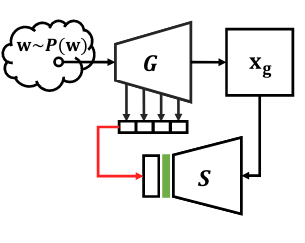 Yang, Y., Cheng, X., Liu, C., Bilen, H., & Ji, X. (2022). Distilling Representations from GAN Generator via Squeeze and Span. Neural Information Processing Systems (NeurIPS).
Yang, Y., Cheng, X., Liu, C., Bilen, H., & Ji, X. (2022). Distilling Representations from GAN Generator via Squeeze and Span. Neural Information Processing Systems (NeurIPS).
In recent years, generative adversarial networks (GANs) have been an actively studied topic and shown to successfully produce high-quality realistic images in various domains. The controllable synthesis ability of GAN generators suggests that they maintain informative, disentangled, and explainable image representations, but leveraging and transferring their representations to downstream tasks is largely unexplored. In this paper, we propose to distill knowledge from GAN generators by squeezing and spanning their representations. We squeeze the generator features into representations that are invariant to semantic-preserving transformations through a network before they are distilled into the student network. We span the distilled representation of the synthetic domain to the real domain by also using real training data to remedy the mode collapse of GANs and boost the student network performance in a real domain. Experiments justify the efficacy of our method and reveal its great significance in self-supervised representation learning. Code will be made public.
@inproceedings{Yang22b, title = {Distilling Representations from GAN Generator via Squeeze and Span}, author = {Yang, Yu and Cheng, Xaiotian and Liu, Chang and Bilen, Hakan and Ji, Xiangyang}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2022} } -
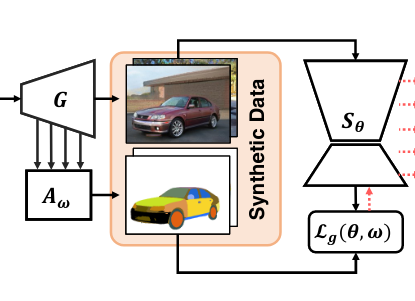 Yang, Y., Cheng, X., Bilen, H., & Ji, X. (2022). Learning to Annotate Part Segmentation with Gradient Matching. International Conference on Learning Representations (ICLR).
Yang, Y., Cheng, X., Bilen, H., & Ji, X. (2022). Learning to Annotate Part Segmentation with Gradient Matching. International Conference on Learning Representations (ICLR).
The success of state-of-the-art deep neural networks heavily relies on the presence of large-scale labeled datasets, which are extremely expensive and time-consuming to annotate. This paper focuses on reducing the annotation cost of part segmentation by generating high-quality images with a pre-trained GAN and labeling the generated images with an automatic annotator. In particular, we formulate the annotator learning as the following learning-to-learn problem. Given a pre-trained GAN, the annotator learns to label object parts in a set of randomly generated images such that a part segmentation model trained on these synthetic images with automatic labels obtains superior performance evaluated on a small set of manually labeled images. We show that this nested-loop optimization problem can be reduced to a simple gradient matching problem, which is further efficiently solved with an iterative algorithm. As our method suits the semi-supervised learning setting, we evaluate our method on semi-supervised part segmentation tasks. Experiments demonstrate that our method significantly outperforms other semi-supervised competitors, especially when the amount of labeled examples is limited.
@inproceedings{Yang22a, title = {Learning to Annotate Part Segmentation with Gradient Matching}, author = {Yang, Yu and Cheng, Xiaotian and Bilen, Hakan and Ji, Xiangyang}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2022} } -
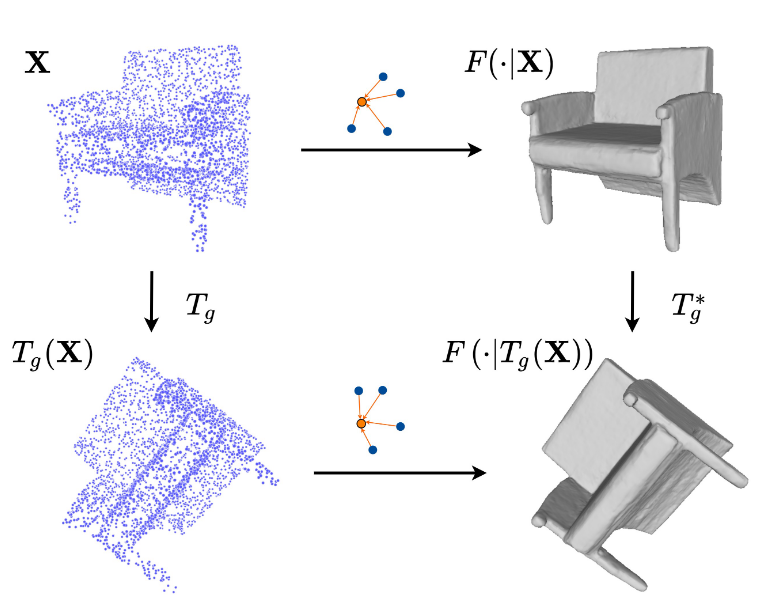 Chen, Y., Fernando, B., Bilen, H., Nießner, M., & Gavves, E. (2022). 3D Equivariant Graph Implicit Functions. European Conference on Computer Vision (ECCV).
Chen, Y., Fernando, B., Bilen, H., Nießner, M., & Gavves, E. (2022). 3D Equivariant Graph Implicit Functions. European Conference on Computer Vision (ECCV).
In recent years, neural implicit representations have made remarkable progress in modeling of 3D shapes with arbitrary topology.In this work, we address two key limitations of such representations, in failing to capture local 3D geometric fine details, and to learn from and generalize to shapes with unseen 3D transformations. To this end, we introduce a novel family of graph implicit functions with equivariant layers that facilitates modeling fine local details and guaranteed robustness to various groups of geometric transformations, through local k-NN graph embeddings with sparse point set observations at multiple resolutions.Our method improves over the existing rotation-equivariant implicit function from 0.69 to 0.89 (IoU) on the ShapeNet reconstruction task. We also show that our equivariant implicit function can be extended to other types of similarity transformations and generalizes to unseen translations and scaling.
@inproceedings{Chen22, title = {3D Equivariant Graph Implicit Functions}, author = {Chen, Yunlu and Fernando, Basura and Bilen, Hakan and Nie{\ss}ner, Matthias and Gavves, Efstratios}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2022} } -
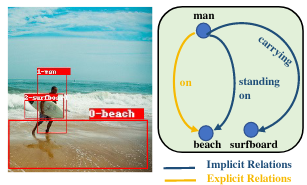 Goel, A., Fernando, B., Keller, F., & Bilen, H. (2022). Not All Relations are Equal: Mining Informative Labels for Scene Graph Generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Goel, A., Fernando, B., Keller, F., & Bilen, H. (2022). Not All Relations are Equal: Mining Informative Labels for Scene Graph Generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Scene graph generation (SGG) aims to capture a wide variety of interactions between pairs of objects, which is essential for full scene understanding. Existing SGG methods trained on the entire set of relations fail to acquire complex reasoning about visual and textual correlations due to various biases in training data. Learning on trivial relations that indicate generic spatial configuration like ’on’ instead of informative relations such as ’parked on’ does not enforce this complex reasoning, harming generalization. To address this problem, we propose a novel framework for SGG training that exploits relation labels based on their informativeness. Our model-agnostic training procedure imputes missing informative relations for less informative samples in the training data and trains a SGG model on the imputed labels along with existing annotations. We show that this approach can successfully be used in conjunction with state-of-the-art SGG methods and improves their performance significantly in multiple metrics on the standard Visual Genome benchmark. Furthermore, we obtain considerable improvements for unseen triplets in a more challenging zero-shot setting.
@inproceedings{Goel22, title = {Not All Relations are Equal: Mining Informative Labels for Scene Graph Generation}, author = {Goel, Arushi and Fernando, Basura and Keller, Frank and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } -
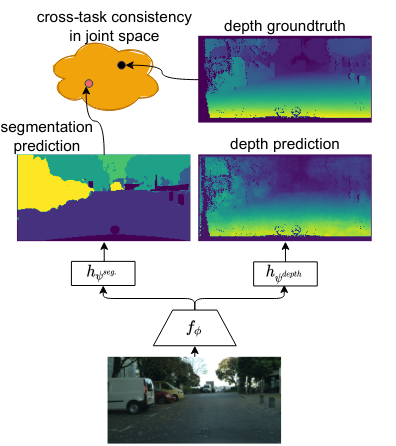 Li, W.-H., Liu, X., & Bilen, H. (2022). Learning Multiple Dense Prediction Tasks from Partially Annotated Data. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Li, W.-H., Liu, X., & Bilen, H. (2022). Learning Multiple Dense Prediction Tasks from Partially Annotated Data. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Despite the recent advances in multi-task learning of dense prediction problems, most methods rely on expensive labelled datasets. In this paper, we present a label efficient approach and look at jointly learning of multiple dense prediction tasks on partially annotated data, which we call multi-task partially-supervised learning. We propose a multi-task training procedure that successfully leverages task relations to supervise its multi-task learning when data is partially annotated. In particular, we learn to map each task pair to a joint pairwise task-space which enables sharing information between them in a computationally efficient way through another network conditioned on task pairs, and avoids learning trivial cross-task relations by retaining high-level information about the input image. We rigorously demonstrate that our proposed method effectively exploits the images with unlabelled tasks and outperforms existing semi-supervised learning approaches and related methods on three standard benchmarks.
@inproceedings{Li22, title = {Learning Multiple Dense Prediction Tasks from Partially Annotated Data}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } -
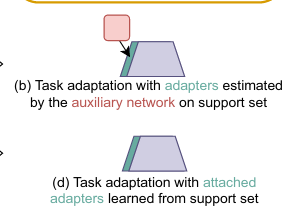 Li, W.-H., Liu, X., & Bilen, H. (2022). Cross-domain Few-shot Learning with Task-specific Adapters. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Li, W.-H., Liu, X., & Bilen, H. (2022). Cross-domain Few-shot Learning with Task-specific Adapters. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
In this paper, we look at the problem of cross-domain few-shot classification that aims to learn a classifier from previously unseen classes and domains with few labeled samples. We study several strategies including various adapter topologies and operations in terms of their performance and efficiency that can be easily attached to existing methods with different meta-training strategies and adapt them for a given task during meta-test phase. We show that parametric adapters attached to convolutional layers with residual connections performs the best, and significantly improves the performance of the state-of-the-art models in the Meta-Dataset benchmark with minor additional cost.
@inproceedings{Li22a, title = {Cross-domain Few-shot Learning with Task-specific Adapters}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, xcode = {https://github.com/VICO-UoE/URL} } -
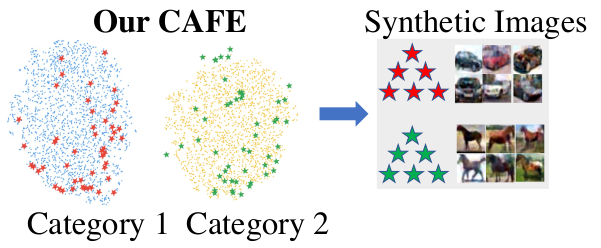 Wang, K., Zhao, B., Peng, X., Zhu, Z., Yang, S., Wang, S., Huang, G., Bilen, H., Wang, X., & You, Y. (2022). CAFE: Learning to Condense Dataset by Aligning Features. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Wang, K., Zhao, B., Peng, X., Zhu, Z., Yang, S., Wang, S., Huang, G., Bilen, H., Wang, X., & You, Y. (2022). CAFE: Learning to Condense Dataset by Aligning Features. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Dataset condensation aims at reducing the network training effort through condensing a cumbersome training set into a compact synthetic one. State-of-the-art approaches largely rely on learning the synthetic data by matching the gradients between the real and synthetic data batches. Despite the intuitive motivation and promising results, such gradient-based methods, by nature, easily overfit to a biased set of samples that produce dominant gradients, and thus lack a global supervision of data distribution. In this paper, we propose a novel scheme to Condense dataset by Aligning FEatures (CAFE), which explicitly attempts to preserve the real-feature distribution as well as the discriminant power of the resulting synthetic set, lending itself to strong generalization capability to various architectures. At the heart of our approach is an effective strategy to align features from the real and synthetic data across various scales, while accounting for the classification of real samples. Our scheme is further backed up by a novel dynamic bi-level optimization, which adaptively adjusts parameter updates to prevent over-/under-fitting. We validate the proposed CAFE across various datasets, and demonstrate that it generally outperforms the state of the art: on the SVHN dataset, for example, the performance gain is up to 11%. Extensive experiments and analysis verify the effectiveness and necessity of proposed designs
@inproceedings{Wang22, title = {CAFE: Learning to Condense Dataset by Aligning Features}, author = {Wang, Kai and Zhao, Bo and Peng, Xiangyu and Zhu, Zheng and Yang, Shuo and Wang, Shuo and Huang, Guan and Bilen, Hakan and Wang, Xinchao and You, Yang}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } -
 Yang, Y., Bilen, H., Zou, Q., Cheung, W. Y., & Ji, X. (2022). Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs. IEEE Winter Conference on Applications of Computer Vision (WACV).
Yang, Y., Bilen, H., Zou, Q., Cheung, W. Y., & Ji, X. (2022). Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs. IEEE Winter Conference on Applications of Computer Vision (WACV).
We propose an unsupervised foreground-background segmentation method via training a segmentation network on the synthetic pseudo segmentation dataset generated from GANs, which are trained from a collection of images without annotations to explicitly disentangle foreground and background. To efficiently generate foreground and background layers and overlay them to compose novel images, the construction of such GANs is fulfilled by our proposed Equivariant Layered GAN, whose improvement, compared to the precedented layered GAN, is embodied in the following two aspects. (1) The disentanglement of foreground and background is improved by extending the previous perturbation strategy and introducing private code recovery that reconstructs the private code of foreground from the composite image. (2) The latent space of the layered GANs is regularized by minimizing our proposed equivariance loss, resulting in interpretable latent codes and better disentanglement of foreground and background. Our methods are evaluated on unsupervised object segmentation datasets including Caltech-UCSD Birds and LSUN Car, achieving state-of-the-art performance.
@inproceedings{Yang22, title = {Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs}, author = {Yang, Yu and Bilen, Hakan and Zou, Qiran and Cheung, Wing Yin and Ji, Xiangyang}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2022} }
2021
-
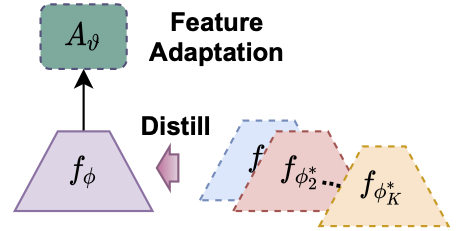 Li, W.-H., Liu, X., & Bilen, H. (2021). Universal Representation Learning from Multiple Domains for Few-shot Classification. International Conference on Computer Vision (ICCV).
Li, W.-H., Liu, X., & Bilen, H. (2021). Universal Representation Learning from Multiple Domains for Few-shot Classification. International Conference on Computer Vision (ICCV).
In this paper, we look at the problem of few-shot classification that aims to learn a classifier for previously unseen classes and domains from few labeled samples. Recent methods use adaptation networks for aligning their features to new domains or select the relevant features from multiple domain-specific feature extractors. In this work, we propose to learn a single set of universal deep representations by distilling knowledge of multiple separately trained networks after co-aligning their features with the help of adapters and centered kernel alignment. We show that the universal representations can be further refined for previously unseen domains by an efficient adaptation step in a similar spirit to distance learning methods. We rigorously evaluate our model in the recent Meta-Dataset benchmark and demonstrate that it significantly outperforms the previous methods while being more efficient.
@inproceedings{Li21, title = {Universal Representation Learning from Multiple Domains for Few-shot Classification}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2021} } -
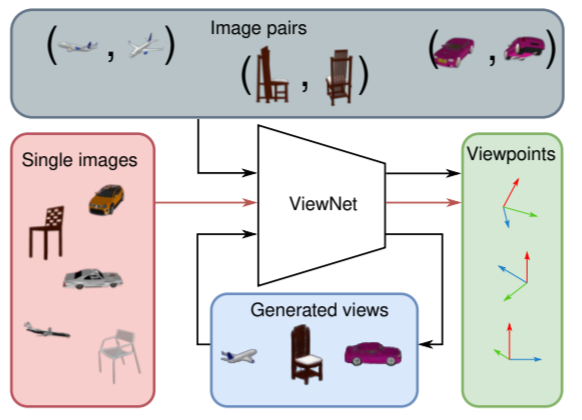 Mariotti, O., Mac Aodha, O., & Bilen, H. (2021). ViewNet: Unsupervised Viewpoint Estimation From Conditional Generation. International Conference on Computer Vision (ICCV).
Mariotti, O., Mac Aodha, O., & Bilen, H. (2021). ViewNet: Unsupervised Viewpoint Estimation From Conditional Generation. International Conference on Computer Vision (ICCV).
Understanding the 3D world without supervision is currently a major challenge in computer vision as the annotations required to supervise deep networks for tasks in this domain are expensive to obtain on a large scale.In this paper, we address the problem of unsupervised viewpoint estimation. We formulate this as a self-supervised learning task, where image reconstruction from raw images provides the supervision needed to predict camera viewpoint. Specifically, we make use of pairs of images of the same object at training time, from unknown viewpoints, to self-supervise training by combining the viewpoint information from one image with the appearance information from the other. We demonstrate that using a perspective spatial transformer allows efficient viewpoint learning, outperforming existing unsupervised approaches on synthetic data and obtaining competitive results on the challenging PASCAL3D+.
@inproceedings{Mariotti21, title = {ViewNet: Unsupervised Viewpoint Estimation From Conditional Generation}, author = {Mariotti, Octave and Mac~Aodha, Oisin and Bilen, Hakan}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2021} } -
 Chen, Y., Fernando, B., Bilen, H., Mensink, T., & Gavves, E. (2021). Shape Transformation with Deep Implicit Functions by Matching Implicit Features. International Conference on Machine Learning (ICML).
Chen, Y., Fernando, B., Bilen, H., Mensink, T., & Gavves, E. (2021). Shape Transformation with Deep Implicit Functions by Matching Implicit Features. International Conference on Machine Learning (ICML).
Recently , neural implicit functions have achieved impressive results for encoding 3D shapes. Conditioning on low-dimensional latent codes generalises a single implicit function to learn shared representation space for a variety of shapes, with the advantage of smooth interpolation. While the benefits from the global latent space do not correspond to explicit points at local level, we propose to track the continuous point trajectory by matching implicit features with the latent code interpolating between shapes, from which we corroborate the hierarchical functionality of the deep implicit functions, where early layers map the latent code to fitting the coarse shape structure, and deeper layers further refine the shape details. Furthermore, the structured representation space of implicit functions enables to apply feature matching for shape deformation, with the benefits to handle topology and semantics inconsistency, such as from an armchair to a chair with no arms, without explicit flow functions or manual annotations.
@inproceedings{Chen21, title = {Shape Transformation with Deep Implicit Functions by Matching Implicit Features}, author = {Chen, Yunlu and Fernando, Basura and Bilen, Hakan and Mensink, Thomas and Gavves, Efstratios}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021} } -
 Deecke, L., Ruff, L., Vandermeulen, R. A., & and Bilen, H. (2021). Transfer Based Semantic Anomaly Detection. International Conference on Machine Learning (ICML).
Deecke, L., Ruff, L., Vandermeulen, R. A., & and Bilen, H. (2021). Transfer Based Semantic Anomaly Detection. International Conference on Machine Learning (ICML).
Detecting semantic anomalies is challenging due to the countless ways in which they may appear in real-world data. While enhancing the robustness of networks may be sufficient for modeling simplistic anomalies, there is no good known way of preparing models for all potential and unseen anomalies that can potentially occur, such as the appearance of new object classes. In this paper, we show that a previously overlooked strategy for anomaly detection (AD) is to introduce an explicit inductive bias toward representations transferred over from some large and varied semantic task. We rigorously verify our hypothesis in controlled trials that utilize intervention, and show that it gives rise to surprisingly effective auxiliary objectives that outperform previous AD paradigms.
@inproceedings{Deecke21, title = {Transfer Based Semantic Anomaly Detection}, author = {Deecke, Lucas and Ruff, Lucas and Vandermeulen, Robert~A. and and Bilen, Hakan}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021}, xcode = {https://github.com/VICO-UoE/TransferAD} } -
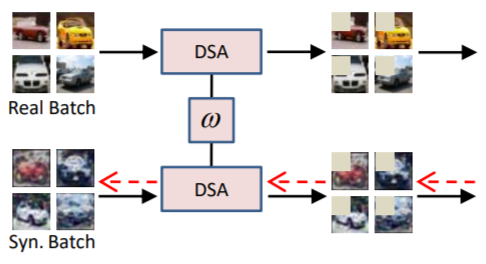 Zhao, B., & Bilen, H. (2021). Dataset Condensation with Differentiable Siamese Augmentation. International Conference on Machine Learning (ICML).
Zhao, B., & Bilen, H. (2021). Dataset Condensation with Differentiable Siamese Augmentation. International Conference on Machine Learning (ICML).
In many machine learning problems, large-scale datasets have become the de-facto standard to train state-of-the-art deep networks at the price of heavy computation load. In this paper, we focus on condensing large training sets into significantly smaller synthetic sets which can be used to train deep neural networks from scratch with minimum drop in performance. Inspired from the recent training set synthesis methods, we propose Differentiable Siamese Augmentation that enables effective use of data augmentation to synthesize more informative synthetic images and thus achieves better performance when training networks with augmentations. Experiments on multiple image classification benchmarks demonstrate that the proposed method obtains substantial gains over the state-of-the-art, 7% improvements on CIFAR10 and CIFAR100 datasets. We show with only less than 1% data that our method achieves 99.6%, 94.9%, 88.5%, 71.5% relative performance on MNIST, FashionMNIST, SVHN, CIFAR10 respectively. We also explore the use of our method in continual learning and neural architecture search, and show promising results.
@inproceedings{Zhao21a, title = {Dataset Condensation with Differentiable Siamese Augmentation}, author = {Zhao, Bo and Bilen, Hakan}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021}, xcode = {https://github.com/vico-uoe/DatasetCondensation} } -
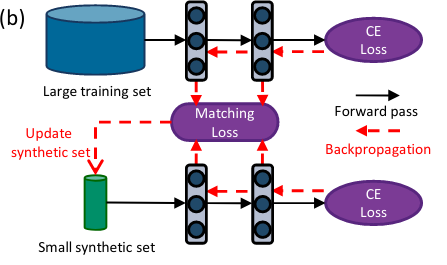 Zhao, B., Konda, R. M., & Bilen, H. (2021). Dataset Condensation with Gradient Matching. International Conference on Learning Representations (ICLR).
Zhao, B., Konda, R. M., & Bilen, H. (2021). Dataset Condensation with Gradient Matching. International Conference on Learning Representations (ICLR).
As the state-of-the-art machine learning methods in many fields rely on larger datasets, storing datasets and training models on them become significantly more expensive. This paper proposes a training set synthesis technique for data-efficient learning, called Dataset Condensation, that learns to condense large dataset into a small set of informative synthetic samples for training deep neural networks from scratch. We formulate this goal as a gradient matching problem between the gradients of deep neural network weights that are trained on the original and our synthetic data. We rigorously evaluate its performance in several computer vision benchmarks and demonstrate that it significantly outperforms the state-of-the-art methods. Finally we explore the use of our method in continual learning and neural architecture search and report promising gains when limited memory and computations are available.
@inproceedings{Zhao21, title = {Dataset Condensation with Gradient Matching}, author = {Zhao, Bo and Konda, Reddy~Mopuri and Bilen, Hakan}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2021}, xcode = {https://github.com/vico-uoe/DatasetCondensation} }
2020
-
 Mariotti, O., & Bilen, H. (2020). Semi-supervised Viewpoint Estimation with Geometry-aware Conditional Generation. European Conference on Computer Vision (ECCV) Workshop.
Mariotti, O., & Bilen, H. (2020). Semi-supervised Viewpoint Estimation with Geometry-aware Conditional Generation. European Conference on Computer Vision (ECCV) Workshop.
There is a growing interest in developing computer vision methods that can learn from limited supervision. In this paper, we consider the problem of learning to predict camera viewpoints, where obtaining ground-truth annotations are expensive and require special equipment, from a limited number of labeled images. We propose a semisupervised viewpoint estimation method that can learn to infer viewpoint information from unlabeled image pairs, where two images differ by a viewpoint change. In particular our method learns to synthesize the second image by combining the appearance from the first one and viewpoint from the second one. We demonstrate that our method significantly improves the supervised techniques, especially in the low-label regime and outperforms the state-of-the-art semi-supervised methods.
@inproceedings{Mariotti20, title = {Semi-supervised Viewpoint Estimation with Geometry-aware Conditional Generation}, author = {Mariotti, Octave and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV) Workshop}, year = {2020}, xcode = {https://github.com/VICO-UoE/SemiSupViewNet} } -
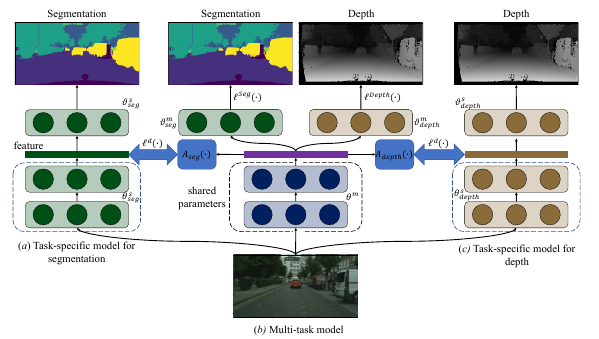 Li, W.-H., & Bilen, H. (2020). Knowledge Distillation for Multi-task Learning. European Conference on Computer Vision (ECCV) Workshop.
Li, W.-H., & Bilen, H. (2020). Knowledge Distillation for Multi-task Learning. European Conference on Computer Vision (ECCV) Workshop.
Multi-task learning (MTL) is to learn one single model that performs multiple tasks for achieving good performance on all tasks and lower cost on computation. Learning such a model requires to jointly optimize losses of a set of tasks with different difficulty levels, magnitudes, and characteristics (e.g. cross-entropy, Euclidean loss), leading to the imbalance problem in multi-task learning. To address the imbalance problem, we propose a knowledge distillation based method in this work. We first learn a task-specific model for each task. We then learn the multitask model for minimizing task-specific loss and for producing the same feature with task-specific models. As the task-specific network encodes different features, we introduce small task-specific adaptors to project multi-task features to the task-specific features. In this way, the adaptors align the task-specific feature and the multi-task feature, which enables a balanced parameter sharing across tasks. Extensive experimental results demonstrate that our method can optimize a multi-task learning model in a more balanced way and achieve better overall performance.
@inproceedings{Li20, title = {Knowledge Distillation for Multi-task Learning}, author = {Li, Wei-Hong and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV) Workshop}, year = {2020}, xcode = {https://github.com/VICO-UoE/KD4MTL} } -
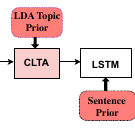 Goel, A., Fernando, B., Nguyen, T.-S., & Bilen, H. (2020). Injecting Prior Knowledge into Image Captioning. European Conference on Computer Vision (ECCV) Workshop.
Goel, A., Fernando, B., Nguyen, T.-S., & Bilen, H. (2020). Injecting Prior Knowledge into Image Captioning. European Conference on Computer Vision (ECCV) Workshop.
Automatically generating natural language descriptions from an image is a challenging problem in artificial intelligence that requires a good understanding of the visual and textual signals and the correlations between them. The state-of-the-art methods in image captioning struggles to approach human level performance, especially when data is limited. In this paper, we propose to improve the performance of the state-of-the-art image captioning models by incorporating two sources of prior knowledge: (i) a conditional latent topic attention, that uses a set of latent variables (topics) as an anchor to generate highly probable words and, (ii) a regularization technique that exploits the inductive biases in syntactic and semantic structure of captions and improves the generalization of image captioning models. Our experiments validate that our method produces more human interpretable captions and also leads to significant improvements on the MSCOCO dataset in both the full and low data regimes.
@inproceedings{Goel20, title = {Injecting Prior Knowledge into Image Captioning}, author = {Goel, Arushi and Fernando, Basura and Nguyen, Thanh-Son and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV) Workshop}, year = {2020} } -
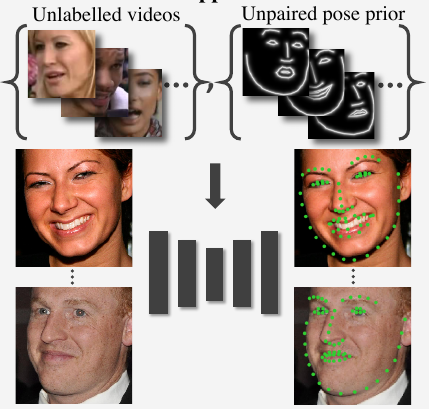 Jakab, T., Gupta, A., Bilen, H., & Vedaldi, A. (2020). Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Jakab, T., Gupta, A., Bilen, H., & Vedaldi, A. (2020). Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
We propose a new method for recognizing the pose of objects from a single image that for learning uses only unlabelled videos and a weak empirical prior on the object poses. Video frames differ primarily in the pose of the objects they contain, so our method distils the pose information by analyzing the differences between frames. The distillation uses a new dual representation of the geometry of objects as a set of 2D keypoints, and as a pictorial representation, i.e. a skeleton image. This has three benefits: (1) it provides a tight ‘geometric bottleneck’ which disentangles pose from appearance, (2) it can leverage powerful image-to-image translation networks to map between photometry and geometry, and (3) it allows to incorporate empirical pose priors in the learning process. The pose priors are obtained from unpaired data, such as from a different dataset or modality such as mocap, such that no annotated image is ever used in learning the pose recognition network. In standard benchmarks for pose recognition for humans and faces, our method achieves state-of-the-art performance among methods that do not require any labelled images for training.
@inproceedings{Jakab20, title = {Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos}, author = {Jakab, T. and Gupta, A. and Bilen, H and Vedaldi, A.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2020}, xcode = {https://github.com/tomasjakab/keypointgan} } -
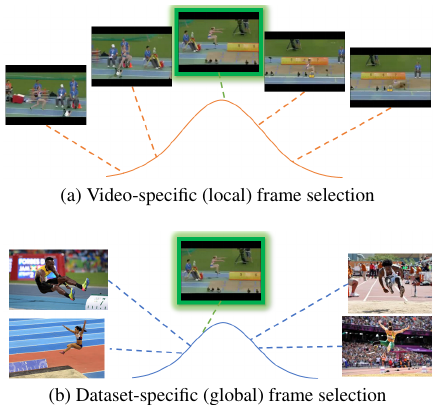 Fernando, B., Tan, C., & Bilen, H. (2020). Weakly Supervised Gaussian Networks for Action Detection. IEEE Winter Conference on Applications of Computer Vision (WACV).
Fernando, B., Tan, C., & Bilen, H. (2020). Weakly Supervised Gaussian Networks for Action Detection. IEEE Winter Conference on Applications of Computer Vision (WACV).
Detecting temporal extents of human actions in videos is a challenging computer vision problem that requires detailed manual supervision including frame-level labels. This expensive annotation process limits deploying action detectors to a limited number of categories. We propose a novel method, called WSGN, that learns to detect actions from weak supervision, using only video-level labels. WSGN learns to exploit both video-specific and datasetwide statistics to predict relevance of each frame to an action category. This strategy leads to significant gains in action detection for two standard benchmarks THUMOS14 and Charades. Our method obtains excellent results compared to state-of-the-art methods that uses similar features and loss functions on THUMOS14 dataset. Similarly, our weakly supervised method is only 0.3% mAP behind a state-of-the-art supervised method on challenging Charades dataset for action localization.
@inproceedings{Fernando20, title = {Weakly Supervised Gaussian Networks for Action Detection}, author = {Fernando, B. and Tan, C. and Bilen, H.}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2020} }
2019
-
 Thewlis, J., Albanie, S., Bilen, H., & Vedaldi, A. (2019). Unsupervised Learning of Landmarks by Descriptor Vector Exchange. International Conference on Computer Vision (ICCV).
Thewlis, J., Albanie, S., Bilen, H., & Vedaldi, A. (2019). Unsupervised Learning of Landmarks by Descriptor Vector Exchange. International Conference on Computer Vision (ICCV).
@inproceedings{Thewlis19, title = {Unsupervised Learning of Landmarks by Descriptor Vector Exchange}, author = {Thewlis, J. and Albanie, S. and Bilen, H. and Vedaldi, A.}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2019}, xcode = {http://www.robots.ox.ac.uk/\~{}vgg/research/DVE/} } -
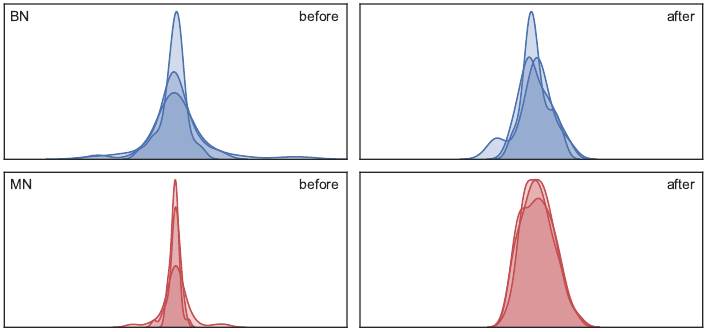 Deecke, L., Murray, I., & Bilen, H. (2019). Mode Normalization. International Conference on Learning Representations (ICLR).
Deecke, L., Murray, I., & Bilen, H. (2019). Mode Normalization. International Conference on Learning Representations (ICLR).
Normalization methods are a central building block in the deep learning toolbox. They accelerate and stabilize training, while decreasing the dependence on manually tuned learning rate schedules. When learning from multi-modal distributions, the effectiveness of batch normalization (BN), arguably the most prominent normalization method, is reduced. As a remedy, we propose a more flexible approach: by extending the normalization to more than a single mean and variance, we detect modes of data on-the-fly, jointly normalizing samples that share common features. We demonstrate that our method outperforms BN and other widely used normalization techniques in several experiments, including single and multi-task datasets.
@inproceedings{Deecke19, title = {Mode Normalization}, author = {Deecke, L. and Murray, I. and Bilen, H.}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2019}, xcode = {https://github.com/ldeecke/mn-torch} }
2018
-
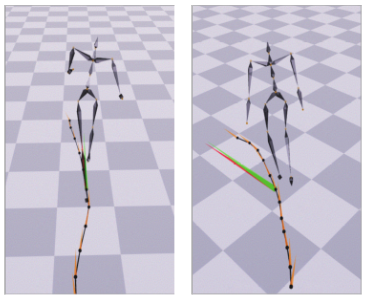 Mason, I., Starke, S., Zhang, H., Bilen, H., & Komura, T. (2018). Few-shot learning of homogeneous human locomotion styles. Computer Graphics Forum, 37(7), 143–153.
Mason, I., Starke, S., Zhang, H., Bilen, H., & Komura, T. (2018). Few-shot learning of homogeneous human locomotion styles. Computer Graphics Forum, 37(7), 143–153.
@article{Mason18, title = {Few-shot learning of homogeneous human locomotion styles}, author = {Mason, Ian and Starke, Sebastian and Zhang, He and Bilen, Hakan and Komura, Taku}, journal = {Computer Graphics Forum}, volume = {37}, number = {7}, pages = {143-153}, year = {2018}, publisher = {Wiley} } -
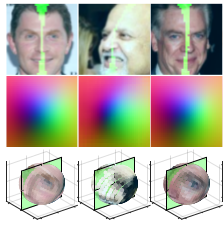 Thewlis, J., Bilen, H., & Vedaldi, A. (2018). Modelling and unsupervised learning of symmetric deformable object categories. Neural Information Processing Systems (NeurIPS).
Thewlis, J., Bilen, H., & Vedaldi, A. (2018). Modelling and unsupervised learning of symmetric deformable object categories. Neural Information Processing Systems (NeurIPS).
@inproceedings{Thewlis18, title = {Modelling and unsupervised learning of symmetric deformable object categories}, author = {Thewlis, J. and Bilen, H. and Vedaldi, A.}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2018} } -
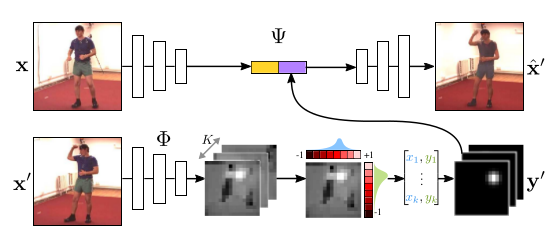 Jakab, T., Gupta, A., Bilen, H., & Vedaldi, A. (2018). Unsupervised Learning of Object Landmarks through Conditional Image Generation. Neural Information Processing Systems (NeurIPS).
Jakab, T., Gupta, A., Bilen, H., & Vedaldi, A. (2018). Unsupervised Learning of Object Landmarks through Conditional Image Generation. Neural Information Processing Systems (NeurIPS).
@inproceedings{Jakab18, title = {Unsupervised Learning of Object Landmarks through Conditional Image Generation}, author = {Jakab, T. and Gupta, A. and Bilen, H and Vedaldi, A.}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2018} } -
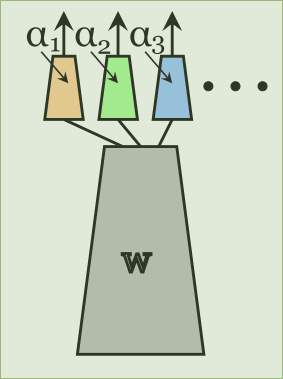 Rebuffi, S.-A., Bilen, H., & Vedaldi, A. (2018). Efficient parametrization of multi-domain deep neural networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Rebuffi, S.-A., Bilen, H., & Vedaldi, A. (2018). Efficient parametrization of multi-domain deep neural networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
@inproceedings{Rebuffi18, title = {Efficient parametrization of multi-domain deep neural networks}, author = {Rebuffi, S-A. and Bilen, H. and Vedaldi, A.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2018}, xcode = {https://github.com/srebuffi/residual_adapters} }
2017
-
 Thewlis, J., Bilen, H., & Vedaldi, A. (2017). Unsupervised learning of object frames by dense equivariant image labelling. Neural Information Processing Systems (NeurIPS).
Thewlis, J., Bilen, H., & Vedaldi, A. (2017). Unsupervised learning of object frames by dense equivariant image labelling. Neural Information Processing Systems (NeurIPS).
@inproceedings{Thewlis17a, title = {Unsupervised learning of object frames by dense equivariant image labelling}, author = {Thewlis, J. and Bilen, H. and Vedaldi, A.}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2017} } -
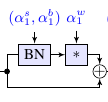 Rebuffi, S.-A., Bilen, H., & Vedaldi, A. (2017). Learning multiple visual domains with residual adapters. Neural Information Processing Systems (NeurIPS).
Rebuffi, S.-A., Bilen, H., & Vedaldi, A. (2017). Learning multiple visual domains with residual adapters. Neural Information Processing Systems (NeurIPS).
@inproceedings{Rebuffi17, title = {Learning multiple visual domains with residual adapters}, author = {Rebuffi, S-A. and Bilen, H. and Vedaldi, A.}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2017}, xcode = {https://github.com/srebuffi/residual_adapters} } -
 Thewlis, J., Bilen, H., & Vedaldi, A. (2017). Unsupervised learning of object landmarks by factorized spatial embeddings. International Conference on Computer Vision (ICCV).
Thewlis, J., Bilen, H., & Vedaldi, A. (2017). Unsupervised learning of object landmarks by factorized spatial embeddings. International Conference on Computer Vision (ICCV).
@inproceedings{Thewlis17, title = {Unsupervised learning of object landmarks by factorized spatial embeddings}, author = {Thewlis, J. and Bilen, H. and Vedaldi, A.}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2017} } -
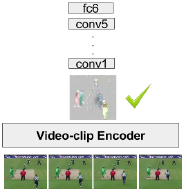 Fernando, B., Bilen, H., Gavves, E., & Gould, S. (2017). Self-Supervised Video Representation Learning With Odd-One-Out Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Fernando, B., Bilen, H., Gavves, E., & Gould, S. (2017). Self-Supervised Video Representation Learning With Odd-One-Out Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
@inproceedings{Fernando17, title = {Self-Supervised Video Representation Learning With Odd-One-Out Networks}, author = {Fernando, B. and Bilen, H. and Gavves, E. and Gould, S.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2017} } -
 Bilen, H., Fernando, B., Gavves, E., & Vedaldi, A. (2017). Action Recognition with Dynamic Image Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
Bilen, H., Fernando, B., Gavves, E., & Vedaldi, A. (2017). Action Recognition with Dynamic Image Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
@article{Bilen17a, title = {Action Recognition with Dynamic Image Networks}, author = {Bilen, H. and Fernando, B. and Gavves, E. and Vedaldi, A.}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2017}, keywords = {journal}, xcode = {https://github.com/hbilen/dynamic-image-nets} }
2016
-
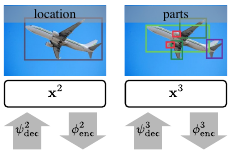 Bilen, H., & Vedaldi, A. (2016). Integrated perception with recurrent multi-task neural networks. Neural Information Processing Systems (NeurIPS).
Bilen, H., & Vedaldi, A. (2016). Integrated perception with recurrent multi-task neural networks. Neural Information Processing Systems (NeurIPS).
@inproceedings{Bilen16b, title = {Integrated perception with recurrent multi-task neural networks}, author = {Bilen, H. and Vedaldi, A.}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2016} } -
 Bilen, H., Fernando, B., Gavves, E., Vedaldi, A., & Gould, S. (2016). Dynamic Image Networks for Action Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Bilen, H., Fernando, B., Gavves, E., Vedaldi, A., & Gould, S. (2016). Dynamic Image Networks for Action Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
@inproceedings{Bilen16a, title = {Dynamic Image Networks for Action Recognition}, author = {Bilen, H. and Fernando, B. and Gavves, E. and Vedaldi, A. and Gould, S.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2016}, xcode = {https://github.com/hbilen/dynamic-image-nets} } -
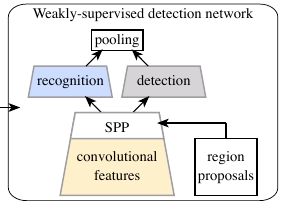 Bilen, H., & Vedaldi, A. (2016). Weakly Supervised Deep Detection Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Bilen, H., & Vedaldi, A. (2016). Weakly Supervised Deep Detection Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
@inproceedings{Bilen16, title = {Weakly Supervised Deep Detection Networks}, author = {Bilen, H. and Vedaldi, A.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2016}, xcode = {https://github.com/hbilen/WSDDN} }
2015
-
 Bilen, H., Pedersoli, M., & Tuytelaars, T. (2015). Weakly Supervised Object Detection with Convex Clustering. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Bilen, H., Pedersoli, M., & Tuytelaars, T. (2015). Weakly Supervised Object Detection with Convex Clustering. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
@inproceedings{Bilen15, title = {Weakly Supervised Object Detection with Convex Clustering}, author = {Bilen, H. and Pedersoli, M. and Tuytelaars, T.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2015} }
2014
-
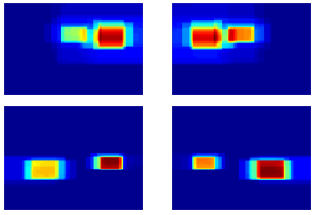 Bilen, H., Pedersoli, M., & Tuytelaars, T. (2014). Weakly Supervised Object Detection with Posterior Regularization. British Machine Vision Conference (BMVC).
Bilen, H., Pedersoli, M., & Tuytelaars, T. (2014). Weakly Supervised Object Detection with Posterior Regularization. British Machine Vision Conference (BMVC).
@inproceedings{Bilen14b, title = {Weakly Supervised Object Detection with Posterior Regularization}, author = {Bilen, H. and Pedersoli, M. and Tuytelaars, T.}, booktitle = {British Machine Vision Conference (BMVC)}, year = {2014} } -
 Bilen, H., Pedersoli, M., Namboodiri, V. P., Tuytelaars, T., & Van Gool, L. (2014). Object Classification with Adaptive Regions. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Bilen, H., Pedersoli, M., Namboodiri, V. P., Tuytelaars, T., & Van Gool, L. (2014). Object Classification with Adaptive Regions. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
@inproceedings{Bilen14a, title = {Object Classification with Adaptive Regions}, author = {Bilen, H. and Pedersoli, M. and Namboodiri, V.P. and Tuytelaars, T. and Van~Gool, L.}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2014} } -
 Bilen, H., Namboodiri, V. P., & Van Gool, L. (2014). Object and Action Classification with Latent Window Parameters. International Journal Computer Vision (IJCV), 106(3), 237–251.
Bilen, H., Namboodiri, V. P., & Van Gool, L. (2014). Object and Action Classification with Latent Window Parameters. International Journal Computer Vision (IJCV), 106(3), 237–251.
@article{Bilen14, title = {Object and Action Classification with Latent Window Parameters}, author = {Bilen, H. and Namboodiri, V.P. and Van~Gool, L.}, journal = {International Journal Computer Vision (IJCV)}, volume = {106}, number = {3}, pages = {237--251}, year = {2014}, keywords = {journal} }
2012
-
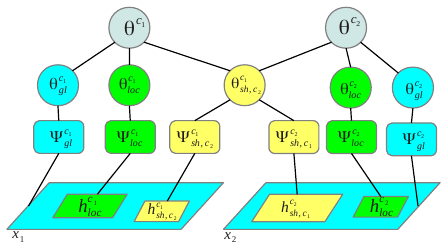 Bilen, H., Namboodiri, V. P., & Van Gool, L. (2012). Classification with Global, Local and Shared Features. DAGM-OAGM.
Bilen, H., Namboodiri, V. P., & Van Gool, L. (2012). Classification with Global, Local and Shared Features. DAGM-OAGM.
@inproceedings{Bilen12, title = {Classification with Global, Local and Shared Features}, author = {Bilen, H. and Namboodiri, V.P. and Van~Gool, L.}, booktitle = {DAGM-OAGM}, year = {2012} } -
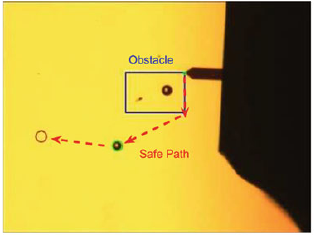 Bilen, H., Hocaoglu, M., Unel, M., & Sabanovic, A. (2012). Developing robust vision modules for microsystems applications. Machine Vision and Applications, 23(1), 25–42.
Bilen, H., Hocaoglu, M., Unel, M., & Sabanovic, A. (2012). Developing robust vision modules for microsystems applications. Machine Vision and Applications, 23(1), 25–42.
@article{Bilen12a, title = {Developing robust vision modules for microsystems applications}, author = {Bilen, H. and Hocaoglu, M. and Unel, M. and Sabanovic, A.}, journal = {Machine Vision and Applications}, volume = {23}, number = {1}, pages = {25--42}, year = {2012}, publisher = {Springer} }
2011
-
 Bilen, H., Namboodiri, V. P., & Van Gool, L. (2011). Object and Action Classification with Latent Variables. British Machine Vision Conference (BMVC).
Bilen, H., Namboodiri, V. P., & Van Gool, L. (2011). Object and Action Classification with Latent Variables. British Machine Vision Conference (BMVC).
@inproceedings{Bilen11a, title = {Object and Action Classification with Latent Variables}, author = {Bilen, H. and Namboodiri, V.~P. and Van~Gool, L.}, booktitle = {British Machine Vision Conference (BMVC)}, year = {2011} } -
 Bilen, H., Namboodiri, V. P., & Van Gool, L. (2011). Action Recognition: A Region Based Approach. IEEE Winter Conference on Applications of Computer Vision (WACV).
Bilen, H., Namboodiri, V. P., & Van Gool, L. (2011). Action Recognition: A Region Based Approach. IEEE Winter Conference on Applications of Computer Vision (WACV).
@inproceedings{Bilen11, title = {Action Recognition: A Region Based Approach}, author = {Bilen, H. and Namboodiri, V.~P. and Van~Gool, L.}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2011} }
2009
-
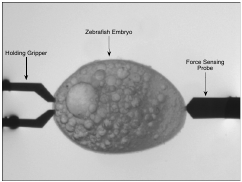 Bilen, H., Hocaoglu, M., Ozgur, E., Baran, E. A., Unel, M., & Gozuacik, D. (2009). Novel Parameter Estimation Schemes in Microsystems. Proceedings of International Conference on Robotics and Automation (ICRA).
Bilen, H., Hocaoglu, M., Ozgur, E., Baran, E. A., Unel, M., & Gozuacik, D. (2009). Novel Parameter Estimation Schemes in Microsystems. Proceedings of International Conference on Robotics and Automation (ICRA).
@inproceedings{Bilen09, title = {Novel Parameter Estimation Schemes in Microsystems}, author = {Bilen, H. and Hocaoglu, M. and Ozgur, E. and Baran, E.A. and Unel, M. and Gozuacik, D.}, booktitle = {Proceedings of International Conference on Robotics and Automation (ICRA)}, year = {2009} }
2008
-
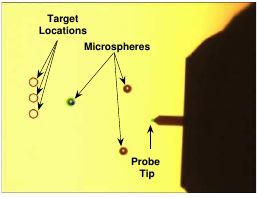 Bilen, H., & Unel, M. (2008). Micromanipulation using a microassembly workstation with vision and force sensing. Advanced Intelligent Computing Theories and Applications, 1164–1172.
Bilen, H., & Unel, M. (2008). Micromanipulation using a microassembly workstation with vision and force sensing. Advanced Intelligent Computing Theories and Applications, 1164–1172.
@inproceedings{Bilen08, title = {Micromanipulation using a microassembly workstation with vision and force sensing}, author = {Bilen, H. and Unel, M.}, booktitle = {Advanced Intelligent Computing Theories and Applications}, pages = {1164--1172}, year = {2008}, publisher = {Springer Berlin Heidelberg} }
2007
-
 Bilen, H., Hocaoglu, M., Ozgur, E., Unel, M., & Sabanovic, A. (2007). A Comparative Study of Conventional Visual Servoing Schemes in Microsystem Applications. Conference on Intelligent Robots and Systems (IROS).
Bilen, H., Hocaoglu, M., Ozgur, E., Unel, M., & Sabanovic, A. (2007). A Comparative Study of Conventional Visual Servoing Schemes in Microsystem Applications. Conference on Intelligent Robots and Systems (IROS).
@inproceedings{Bilen07, title = {A Comparative Study of Conventional Visual Servoing Schemes in Microsystem Applications}, author = {Bilen, H. and Hocaoglu, M. and Ozgur, E. and Unel, M. and Sabanovic, A.}, booktitle = {Conference on Intelligent Robots and Systems (IROS)}, year = {2007} }
Theses
-
 Bilen, H. (2013). Object Classification with Latent Parameters [PhD thesis]. PhD Thesis, KU Leuven.
Bilen, H. (2013). Object Classification with Latent Parameters [PhD thesis]. PhD Thesis, KU Leuven.
@phdthesis{Bilen13a, title = {Object Classification with Latent Parameters}, author = {Bilen, H.}, year = {2013}, organization = {PhD Thesis, KU Leuven}, keywords = {thesis} } -
 Bilen, H. (2008). Novel Estimation and Control Techniques in Micromanipulation Using Vision
and Force Feedback [Master's thesis]. MSc Thesis, Sabanci University.
Bilen, H. (2008). Novel Estimation and Control Techniques in Micromanipulation Using Vision
and Force Feedback [Master's thesis]. MSc Thesis, Sabanci University.
@mastersthesis{Bilen08a, title = {{Novel Estimation and Control Techniques in Micromanipulation Using Vision and Force Feedback}}, author = {Bilen, H.}, organization = {MSc Thesis, Sabanci University}, keywords = {thesis}, year = {2008} }
Technical Reports
-
 Bilen, H., & Vedaldi, A. (2017). Universal representations: The missing link between faces, text, planktons, and cat breeds. arXiv preprint arXiv:1701.07275.
Bilen, H., & Vedaldi, A. (2017). Universal representations: The missing link between faces, text, planktons, and cat breeds. arXiv preprint arXiv:1701.07275.
@techreport{Bilen17, title = {Universal representations: The missing link between faces, text, planktons, and cat breeds}, author = {Bilen, H. and Vedaldi, A.}, organization = {arXiv preprint arXiv:1701.07275}, year = {2017} } -
 Mahendran, A., Bilen, H., Henriques, J. F., & Vedaldi, A. (2016). ResearchDoom and CocoDoom: Learning Computer Vision with Games.
Mahendran, A., Bilen, H., Henriques, J. F., & Vedaldi, A. (2016). ResearchDoom and CocoDoom: Learning Computer Vision with Games.
@inproceedings{Mahendran16, title = {ResearchDoom and CocoDoom: Learning Computer Vision with Games}, author = {Mahendran, A. and Bilen, H. and Henriques, J.F. and Vedaldi, A.}, organization = {arXiv preprint arXiv:1610.02431}, year = {2016} }