We now describe the invocation process in detail, based on the intuitions of the previous section.
The first consideration of invocation is from its externally viewed characteristics - its function and its input and output behavior. Formally, the inputs to invocation are:
Invocation always takes place in an image context. This is because objects are always connected and their features are always spatially close. The context defines where image data can come from and what structures can provide supporting evidence. For this research, the two types of contexts are the surface hypothesis (Chapter 4) and the surface cluster (Chapter 5), which localize evidence for model SURFACEs and ASSEMBLYs respectively. The surface cluster also groups surfaces and contained surface clusters, so is a suitable context for accumulating subcomponent plausibilities.
Model invocation calculates a plausibility representing the degree to which an object model explains an image structure. Plausibility is a function of the model, the data context, the data properties, the desired properties, the model-to-model relationships, current object hypotheses, and the plausibilities of all related model-to-data pairings.
A plausibility measure is used instead of direct indexing because:
Given the plausibility ranking, when should a model be invoked?
Even if a model instance has the highest plausibility, it should not invoke
the model if the absolute plausibility is low,
as when analyzing an image with no identifiable objects in it.
The measure used lies in the range [![]() ], and when it is positive, the model
can be invoked.
Because the invocation network described below
favors positive plausibilities as supporting and negative plausibilities
as contradicting, a threshold of zero was used.
], and when it is positive, the model
can be invoked.
Because the invocation network described below
favors positive plausibilities as supporting and negative plausibilities
as contradicting, a threshold of zero was used.
Plausibility is a function of property evidence arising from observed features and relationship evidence arising from hypotheses that have some relationship with the current one. For example, a toroidal shape gives property evidence for a bicycle wheel, whereas a bicycle frame gives relationship evidence.
The foundation of plausibility is property evidence and is acquired by matching descriptions of image-based structures to model-based evidence constraints. The constraints implement the notion that certain features are important in distinguishing the structure.
Relationship evidence comes from associated model instances. Although there are many types of relationships, this work only considered the following ones (treating object A as the model of current interest):
These seven relationships have been made explicit because each embodies different forms of visual knowledge and because their individual evidence computations are different. Component relationships give strong circumstantial evidence for the presence of objects. An object necessarily requires most of its subcomponents for it to be considered that object, whereas the reverse does not hold. The presence of a car makes the presence of wheels highly plausible, but cannot say much about whether a particular image feature is a wheel. The presence of automobile wheels also makes the presence of a car plausible (though the latter implication is weaker), but does not mean that any containing image context is likely to contain the car.
The final issue is evidence integration. Evidence is cumulative: each new piece of valid evidence modifies the plausibility of a structure. Evidence is also suggestive: each item of support is evaluated independently of the others and so does not confirm the identity of any structure. Because there are eight different evidence types, the problem of how to compute a single plausibility value arises. We wish to use all the evidence, as data errors, missing values, and object variations are alternative causes for weak evidence, as well as having the wrong identity. The solution given below treats the different evidence values on the same scale, but integrates the values according to the evidence type.
The different model hypotheses in the different contexts are represented as nodes in a network linked by property and relationship evidence arcs. Many of the arcs also connect to arithmetic function nodes that compute the specific evidence values, as discussed in detail below. Property evidence provides the raw plausibility values for a few of the nodes, and the other nodes acquire plausibility by value propagation through the relationship arcs.
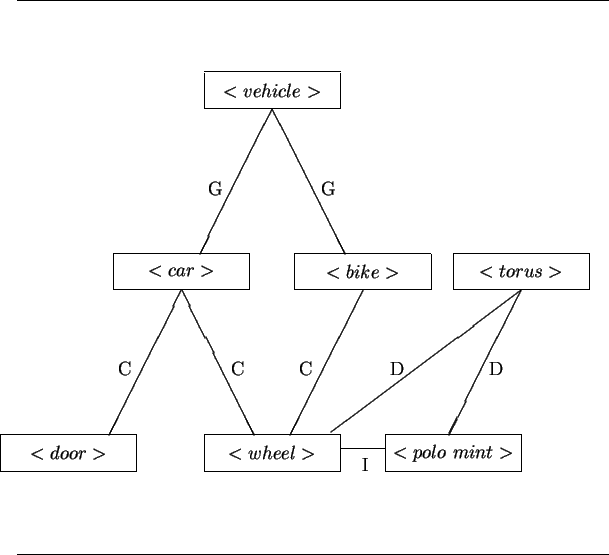
An abbreviated example is shown in Figure 8.6,
where a simplified network is shown with the given relationship links
("G" denotes a class relationship, "D" denotes a description relationship,
"I" denotes an inhibiting relationship and "C" denotes a component relationship).
The precise formulation of the calculations is given in later
sections, and the point here is to introduce the character of the
computation (while glossing over the details).
Supposing there was property evidence for there being a ![]() and a
and a
![]() in the current context, the question then is what the
plausibility of the
in the current context, the question then is what the
plausibility of the ![]() is.
This value comes from integrating description evidence
from the
is.
This value comes from integrating description evidence
from the ![]() and component evidence from the
and component evidence from the ![]() and
and ![]() , and
competing generic evidence from the
, and
competing generic evidence from the ![]() .
.
When a model has been invoked, it is subject to a model-directed
hypothesis construction and
verification process.
If the process is successful, then the plausibility value for that object
is set to 1.0.
Alternatively, failure sets the plausibility to ![]() .
These values are permanently recorded for the hypotheses and
affect future invocations by propagating through the network.
.
These values are permanently recorded for the hypotheses and
affect future invocations by propagating through the network.
In the discussion of each of the relationship types below, three major
aspects are considered: the type of relationship, the calculation of the
relationship's invocation contribution and the context from which the relationship
evidence is taken.