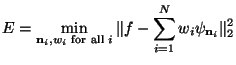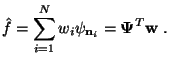To define a WN, we begin
by taking a family of ![]() wavelet functions
wavelet functions
![]() with parameter vectors
with parameter vectors
![]() of some mother wavelet
of some mother wavelet ![]() :
:
It should be mentioned that it was proposed before
[Daubechies, 1990,Daugman, 1988,Lee, 1996] to use an energy
functional
(2) in order to find the optimal set of weights ![]() for
a fixed set of non-orthogonal wavelets
for
a fixed set of non-orthogonal wavelets
![]() . The WN concept
enhances these approaches by finding also the optimal parameters
. The WN concept
enhances these approaches by finding also the optimal parameters
![]() for each (not-necessarily orthonormal) wavelet
for each (not-necessarily orthonormal) wavelet
![]() .
WNs also appear to enhance the RBF neural network approach considerably. This
was pointed out recently by [Reyneri, 1999], even though he investigated
a considerably simplified version of WNs with radial wavelets which
limits the potentials of the WNs considerably.
.
WNs also appear to enhance the RBF neural network approach considerably. This
was pointed out recently by [Reyneri, 1999], even though he investigated
a considerably simplified version of WNs with radial wavelets which
limits the potentials of the WNs considerably.
The parameters ![]() are chosen from
continuous phase space and the wavelets are positioned with
sub-pixel accuracy. This is precisely the main
advantage over the discrete approach of [Daubechies, 1990,Lee, 1996].
While in the case of a discrete phase space local image structure has to be
approximated by a combination of wavelets,
only a single wavelet needs to be chosen in the continuous
case to reflect precise the
local image structure. This assures that a maximum of the image
information can be encoded with only a small number of wavelets.
are chosen from
continuous phase space and the wavelets are positioned with
sub-pixel accuracy. This is precisely the main
advantage over the discrete approach of [Daubechies, 1990,Lee, 1996].
While in the case of a discrete phase space local image structure has to be
approximated by a combination of wavelets,
only a single wavelet needs to be chosen in the continuous
case to reflect precise the
local image structure. This assures that a maximum of the image
information can be encoded with only a small number of wavelets.
In order to find a WN
![]() ,
, ![]() for a function
for a function ![]() , we use
the Levenberg-Marquardt method. As initialization, we distribute the
wavelets homogeneously over the region of interest.
The orientations are initialized randomly, the scales are
initialized to a constant value that is related to the density with
which the wavelets are distributed. We constrained the wavelet parameters
to prevent degenerated wavelet shapes. For the two wavelet types in
this paper (odd Gabor, difference-of-Gaussian) we used constrains
according to [Daugman, 1985].
In several experiments we have found that this rough initialization is
sufficient. Also, we apply a coarse-to-fine strategy by first optimizing a set of
wavelets initialized to coarse scale, followed by the optimization of
a set of wavelets, initialized to a finer scale.
Intuitively, a coarse-to-fine strategy for optimization
makes sense because this minimizes the energy functional (2)
more efficiently. To optimize a WN with 16 wavelets it takes about 30s on
a 750 MHz Pentium processor.
, we use
the Levenberg-Marquardt method. As initialization, we distribute the
wavelets homogeneously over the region of interest.
The orientations are initialized randomly, the scales are
initialized to a constant value that is related to the density with
which the wavelets are distributed. We constrained the wavelet parameters
to prevent degenerated wavelet shapes. For the two wavelet types in
this paper (odd Gabor, difference-of-Gaussian) we used constrains
according to [Daugman, 1985].
In several experiments we have found that this rough initialization is
sufficient. Also, we apply a coarse-to-fine strategy by first optimizing a set of
wavelets initialized to coarse scale, followed by the optimization of
a set of wavelets, initialized to a finer scale.
Intuitively, a coarse-to-fine strategy for optimization
makes sense because this minimizes the energy functional (2)
more efficiently. To optimize a WN with 16 wavelets it takes about 30s on
a 750 MHz Pentium processor.
Using the optimal wavelets ![]() and weights
and weights ![]() of the
wavelet network of an image
of the
wavelet network of an image ![]() ,
, ![]() can be (closely) reconstructed by
a linear combination of the weighted wavelets:
can be (closely) reconstructed by
a linear combination of the weighted wavelets:
|
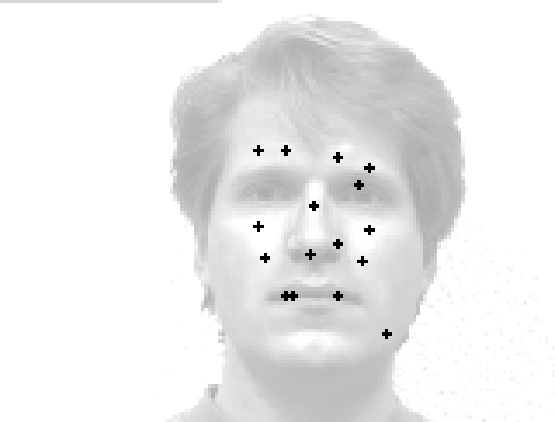
The images in fig. 2 show the relation between the optimized positions of the wavelets (right), and their reconstructions(left) for two different mother wavelets: the odd Gabor function (top) and an anisotropic difference-of-Gaussian (DOF) (bottom).
|