Unit Selection
I have been involved with research on the concatenative approach to speech synthesis over the course of many years, for example as part of the Cougar project, and as a developer for Festival, and its Multisyn unit selection engine and associated voice-building tools.
This section presents one aspect of that work - Viterbi search using an articulatory join cost component - along with some short audio samples to demonstrate. Those not familiar with the unit selection approach to speech synthesis might want to begin with the optional simplified background overview included below.
Articulatorily guided unit selection
Many variations of join cost function have been previously used to measure how well matched two candidate units are for concatentation. Typically, for example, these involve Euclidean, or Mahalanobis, distance metrics with weighted subcomponents calculated in terms of three feature types: spectral features (LSFs, MFCCs etc.), f0 and energy. Notwithstanding all the variations, previous join cost function have been acoustic in nature - they try to capture differences in how the two candidate units sound across the potential join point.
A novel alternative is to compare the positions of the articulators (tongue, lips, jaw etc.) across a potential join point. The intuition motivating this approach is that the mouth of a human talker is subject to physiological constraints and cannot jump from one configuration to a completely different one in a split second. Instead, the mouth moves smoothly, and relatively slowly in fact, through a sequence of configurations. Accordingly, sequences of candidate units selected in a Viterbi search should show the same smooth evolution of articulator movements, with minimal jumps from the end of one unit to the beginning of the next.
The synthetic speech samples in the table below demonstrate how this works. To create these samples we first recorded a large, phonetically-diverse speech database with articulator movements recorded using electromagnetic articulography (EMA) in parallel with the audio. Then, we built three unit selection voices which differ only in their join cost calculation:
-
acoustic - the standard Multisyn join cost (sum of weighted subcosts for MFCCs, f0 and energy)
-
articulatory - Euclidean distance of 12 EMA parameters (x- and y-coordinates of 6 points in the midsagittal plane: upper lip, lower lip, lower incisor, tongue tip, tongue body, and tongue dorsum). F0 and energy subcosts also included.
-
combined - a combination of all subcosts: F0, energy, MFCCs and EMA parameters.
| Features used for join cost calculation | ||
|---|---|---|
| acoustic | articulatory | combined |
As these samples indicate, we find that performance can be improved when articulatory features are added to our standard acoustic-only join cost function. The resulting speech generally sounds smoother, with fewer noticeable join points.
You can experiment further with differences between articulatory and acoustic join costs using the interactive synthesis demonstration below. There, you can synthesise your own choice of text to compare the results with the following join costs: standard acoustic, articulatory-only, combined articulatory-acoustic.
Simplified background
Unit selection is a concatenative approach for artificially synthesising speech. This refers to the way pre-recorded fragments of speech of one form or another are joined together in sequence to make a new utterance.
To build a synthetic voice under the unit selection approach, a large database of speech is first recorded for one human speaker. This may involve the source speaker reading a script for several hours, with the text having been carefully selected to maximise variety.
This database is then carefully processed to label exactly which sound is spoken at which point in time. Then, to synthesise new speech from input text, it is necessary to:
- analyse the text to work out which sequence of sounds is required ("front-end processing" or "text analysis")
- search for the best sequence of labelled chunks, or units, of speech in the pre-recorded speech database
- concatenate the best sequence of units, optionally using signal processing to modify some units and join points, to give the final synthetic utterance.
A typical unit selection voice database will contain hundreds of thousands of "candidate" units which might be considered for selection, giving billions of combinations of units. Fortunately, the Viterbi search algorithm, allows a good sequence of units to be selected in an efficent and practical way. The following diagram illustrates how this search typcially works.
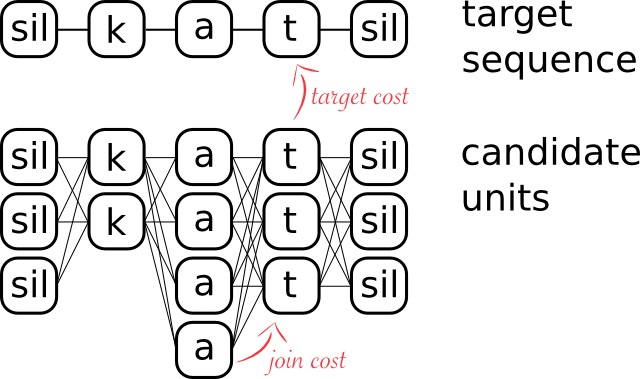
To synthesise the target sound sequence "silence-k-a-t-silence" (i.e. for the word "cat"), the first step conceptually is to find all candidate units in the pre-recorded database for each target sound and use these to build the unit lattice. This lattice is indicated in the lower part fo the diagram above, with links between candidate units indicating all the possible paths which could be followed to synthesise this word. The Viterbi search which is used to efficiently identify the best path through the lattice of candidate units is guided by two cost functions:
Target cost : Measures how well each candidate unit matches the target unit.
Join cost : Measures how well each candidate unit joins on to each path of preceding units?
By carefully designing both the speech database and the target and join cost functions, it is possible to synthesise surprisingly intelligible and natural sound novel speech. The following live demo shows this.
Live unit selection demo
This interactive demo makes use of the Multisyn unit selection engine. Two types of voice are available:
- a few standard Multisyn UK English voices (2 male, 1 female)
- 3 versions of a single voice, allowing comparison of acoustic and articulatory join costs
Note: in this demonstration, no signal processing is used when concatenating units to give the final audible speech. This makes it possible to experiment and directly hear how far we can get in synthesising speech in this straightforward way - essentially we are just gluing pre-recorded fragments of speech back together again in a different order!